تغريدة مثبتة

Gennaro
16.1K posts
Holy shit. Stanford just showed that the biggest performance gap in AI systems isn't the model it's the harness. The code wrapping the model. And they built a system that writes better harnesses automatically than humans can by hand. > +7.7 points. 4x fewer tokens. > #1 ranking on an actively contested benchmark. The harness is the code that decides what information an AI model sees at each step what to store, what to retrieve, what context to show. Changing the harness around a fixed model can produce a 6x performance gap on the same benchmark. Most practitioners know this empirically. What nobody had done was automate the process of finding better harnesses. Stanford's Meta-Harness does exactly that: it runs a coding agent in a loop, gives it access to every prior harness it has tried along with the full execution traces and scores, and lets it propose better ones. The agent reads raw code and failure logs not summaries, not scalar scores and figures out why things broke. The key insight is about information. Every prior automated optimization method compressed feedback before handing it to the optimizer. > Scalar scores only. > LLM-generated summaries. > Short templates. Stanford's finding is that this compression destroys exactly the signal you need for harness engineering. A single design choice about what to store in memory can cascade through hundreds of downstream steps. You cannot debug that from a summary. Meta-Harness gives the proposer a filesystem containing every prior harness's source code, execution traces, and scores up to 10 million tokens of diagnostic information per evaluation and lets it use grep and cat to read whatever it needs. Prior methods worked with 100 to 30,000 tokens of feedback. Meta-Harness works with 3 orders of magnitude more. The TerminalBench-2 search trajectory reveals what this actually looks like in practice. The agent ran for 10 iterations on an actively contested coding benchmark. In iterations 1 and 2, it bundled structural fixes with prompt rewrites and both regressed. In iteration 3, it explicitly identified the confound: the prompt changes were the common failure factor, not the structural fixes. It isolated the structural changes, tested them alone, and observed the smallest regression yet. Over the next 4 iterations it kept probing why completion-flow edits were fragile citing specific tasks and turn counts from prior traces as evidence. By iteration 7 it pivoted entirely: instead of modifying the control loop, it added a single environment snapshot before the agent starts, gathering what tools and languages are available in one shell command. That 80-line additive change became the best candidate in the run and ranked #1 among all Haiku 4.5 agents on the benchmark. The numbers across all three domains: → Text classification vs best hand-designed harness (ACE): +7.7 points accuracy, 4x fewer context tokens → Text classification vs best automated optimizer (OpenEvolve, TTT-Discover): matches their final performance in 4 evaluations vs their 60, then surpasses by 10+ points → Full interface vs scores-only ablation: median accuracy 50.0 vs 34.6 raw execution traces are the critical ingredient, summaries don't recover the gap → IMO-level math: +4.7 points average across 5 held-out models that were never seen during search → IMO math: discovered retrieval harness transfers across GPT-5.4-nano, GPT-5.4-mini, Gemini-3.1-Flash-Lite, Gemini-3-Flash, and GPT-OSS-20B → TerminalBench-2 with Haiku 4.5: 37.6% #1 among all reported Haiku 4.5 agents, beating Goose (35.5%) and Terminus-KIRA (33.7%) → TerminalBench-2 with Opus 4.6: 76.4% #2 overall, beating all hand-engineered agents except one whose result couldn't be reproduced from public code → Out-of-distribution text classification on 9 unseen datasets: 73.1% average vs ACE's 70.2% The math harness discovery is the cleanest demonstration of what automated search actually finds. Stanford gave Meta-Harness a corpus of 535,000 solved math problems and told it to find a better retrieval strategy for IMO-level problems. What emerged after 40 iterations was a four-route lexical router: combinatorics problems get deduplicated BM25 with difficulty reranking, geometry problems get one hard reference plus two raw BM25 neighbors, number theory gets reranked toward solutions that state their technique early, and everything else gets adaptive retrieval based on how concentrated the top scores are. Nobody designed this. The agent discovered that different problem types need different retrieval policies by reading through failure traces and iterating on what broke. The ablation table is the most important result in the paper. > Scores only: median 34.6, best 41.3. > Scores plus LLM-generated summary: median 34.9, best 38.7. > Full execution traces: median 50.0, best 56.7. Summaries made things slightly worse than scores alone. The raw traces the actual prompts, tool calls, model outputs, and state updates from every prior run are what drive the improvement. This is not a marginal difference. The full interface outperforms the compressed interface by 15 points at median. Harness engineering requires debugging causal chains across hundreds of steps. You cannot compress that signal. The model has been the focus of the entire AI industry for the last five years. Stanford just showed the wrapper around the model matters just as much and that AI can now write better wrappers than humans can.
Fuck you too Claude!

woke up and my mentions are full of these Both me and @davemorin tried to talk sense into Anthropic, best we managed was delaying this for a week. Funny how timings match up, first they copy some popular features into their closed harness, then they lock out open source.
🚨 Claude just tried to kill OpenClaw. Anthropic's new 'extra usage' pricing for third-party harnesses is a self-inflicted wound. Most users won't pay more on top of their subscription for tools they already had. They'll just... leave. This is Kimi and MiniMax's moment to steal the agentic crowd. Grok too - xAI's built for this. Even Alibaba's Qwen is shipping multi-turn tool use that just works. The builders who wired Claude into everything? They're already testing replacements. When developer goodwill evaporates, it doesn't come back. Anthropic had the best model. Now they're making you pay twice to use it. That's not a pricing adjustment - that's handing your users to competitors on a silver platter. Who's switching first - and which model are you betting on?




I taught Claude to talk like a caveman to use 75% less tokens. normal claude: ~180 tokens for a web search task caveman claude: ~45 tokens for the same task "I executed the web search tool" = 8 tokens caveman version: "Tool work" = 2 tokens every single grunt swap saves 6-10 tokens. across a FULL task that's 50-100 tokens saved why does it work? caveman claude doesn't explain itself. it does its task first. gives the result. then stops. no "I'd be happy to help you with that." no "Let me search the web for you" no more unnecessary filler words "result. done. me stop." 50-75% burn reduction with usage limits getting tighter every week this might be the most practical hack out there right now
Who said prompt engineering was dead?
woke up and my mentions are full of these Both me and @davemorin tried to talk sense into Anthropic, best we managed was delaying this for a week. Funny how timings match up, first they copy some popular features into their closed harness, then they lock out open source.
Anthropic can't handle the demand they accidentally created. So instead of scaling up, they're cutting off third-party access. Frustrating from a user perspective.
Some thoughts on Snap: savesnapnow.com
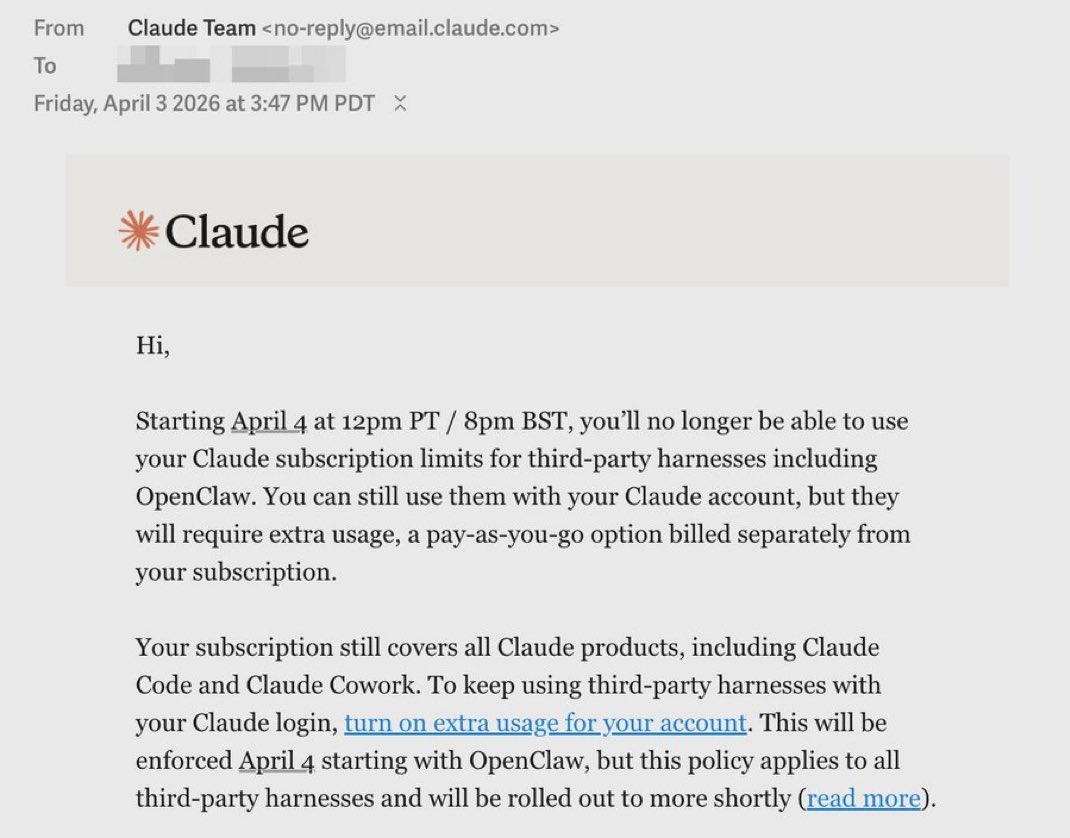
Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw. You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
I connected my Meta RayBans to my OpenClaw so that I can manage my entire fleet of 20+ OpenClaw agents while out and about. It can see what I see, hear what I hear, and I can literally work an entire day while talking to my glasses out in the city in San Francisco. The future of work is here.

I connected my Meta RayBans to my OpenClaw so that I can manage my entire fleet of 20+ OpenClaw agents while out and about. It can see what I see, hear what I hear, and I can literally work an entire day while talking to my glasses out in the city in San Francisco. The future of work is here.

