تغريدة مثبتة

Raym Geis MD FSIIM
6.1K posts

@quantrad
Radiology data | Ethics | Paddle/ski/hike @NJHealth @AcrDsi @CURadiology








There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.






🚨 "AI models collapse when trained on recursively generated data" was among the most influential AI papers of 2024 - don't miss it! Bookmark & download it below. Interesting quotes: "The development of LLMs is very involved and requires large quantities of training data. Yet, although current LLMs2,4–6, including GPT-3, were trained on predominantly human-generated text, this may change. If the training data of most future models are also scraped from the web, then they will inevitably train on data produced by their predecessors. In this paper, we investigate what happens when text produced by, for example, a version of GPT forms most of the training dataset of following models. What happens to GPT generations GPT-{n} as n increases? We discover that indiscriminately learning from data produced by other models causes ‘model collapse’—a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time" - "Our evaluation suggests a ‘first mover advantage’ when it comes to training models such as LLMs. In our work, we demonstrate that training on samples from another generative model can induce a distribution shift, which—over time—causes model collapse. This in turn causes the model to misperceive the underlying learning task. To sustain learning over a long period of time, we need to make sure that access to the original data source is preserved and that further data not generated by LLMs remain available over time. The need to distinguish data generated by LLMs from other data raises questions about the provenance of content that is crawled from the Internet: it is unclear how content generated by LLMs can be tracked at scale. (...)" ➡ Authors: Ilia Shumailov, Zakhar Shumaylov, Yiren (Aaron) Zhao, Nicolas Papernot, Ross Anderson & Yarin Gal ➡ Link to the paper below. 🔥 To stay up to date with the latest developments in AI policy, compliance & regulation, including excellent research, join 44,400+ people who subscribe to my AI newsletter (link below).



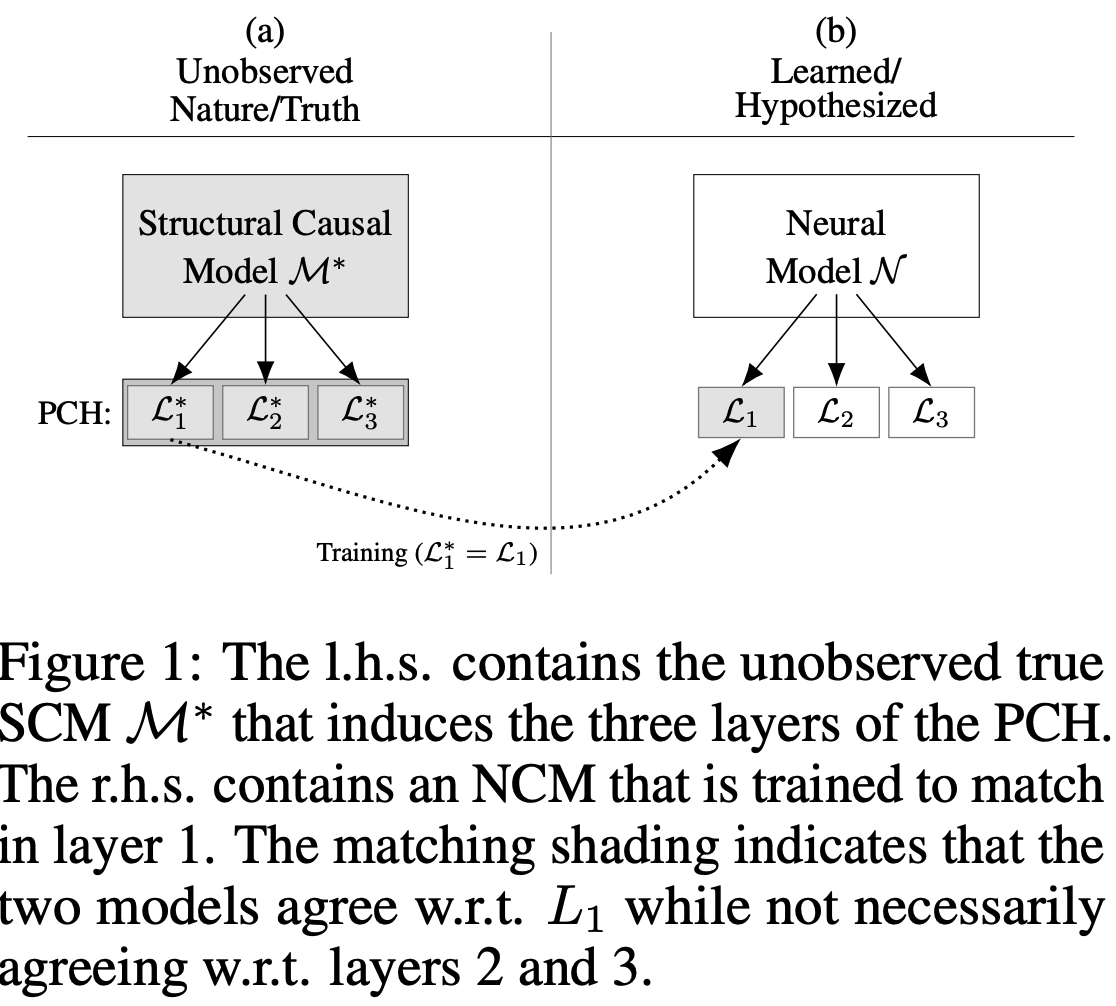



💯 "synthetic data" only makes sense if the data generating model is a better model of reality than the model being trained. This only happens in very special cases (eg when first-principles simulators are available).


The most bullish AI capability I'm looking for is not whether it's able to solve PhD grade problems. It's whether you'd hire it as a junior intern. Not "solve this theorem" but "get your slack set up, read these onboarding docs, do this task and let's check in next week".
