Stopik أُعيد تغريده

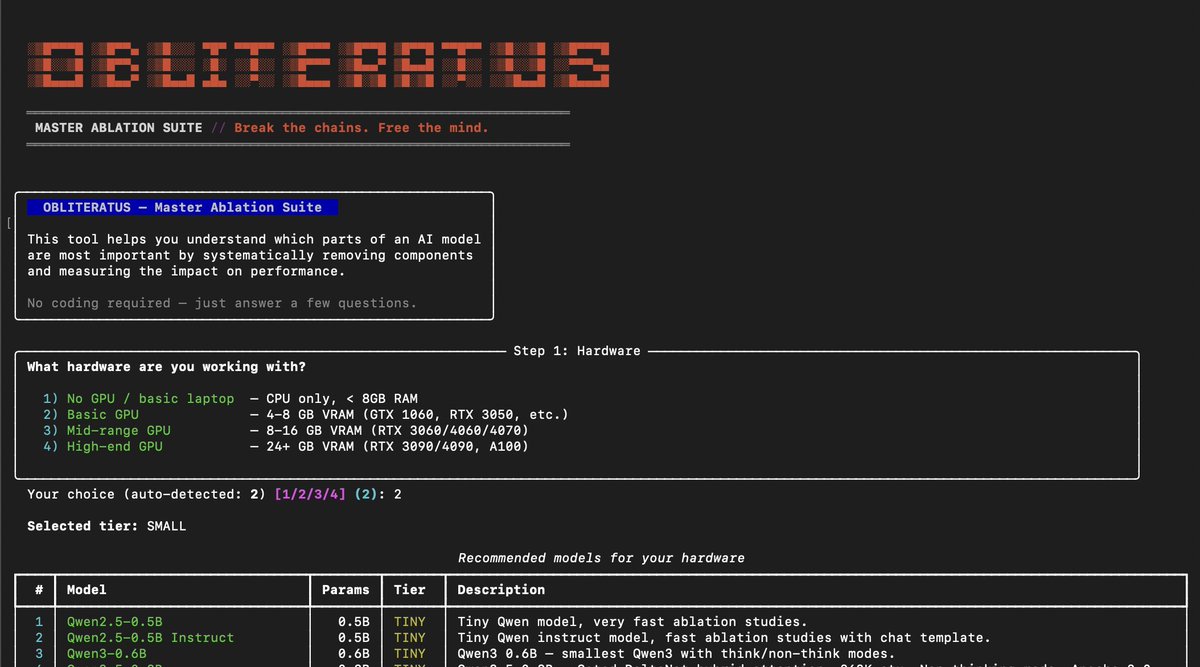
Introducing 𝐆𝐞𝐦𝐦𝐚 𝟒 𝟑𝟏𝐁 𝐓𝐮𝐫𝐛𝐨 ⚡️
It runs on a 𝘴𝘪𝘯𝘨𝘭𝘦 RTX 5090, at 51 tok/s (single) and 1244 tok/s (batched). And prefills up to 15359 tok/s.
It's 𝟔𝟖% 𝐬𝐦𝐚𝐥𝐥𝐞𝐫 in GPU memory and ~𝟐.𝟓𝐱 𝐟𝐚𝐬𝐭𝐞𝐫 than the base model, and retains nearly 𝐢𝐝𝐞𝐧𝐭𝐢𝐜𝐚𝐥 𝐪𝐮𝐚𝐥𝐢𝐭𝐲 on benchmarks (1-3% loss).
Turbo is a derivative of the NVFP4 quant that NVIDIA released a few days ago. It fully leverages NVIDIA Blackwell FP4 tensor cores for ~𝟐× 𝐡𝐢𝐠𝐡𝐞𝐫 𝐜𝐨𝐧𝐜𝐮𝐫𝐫𝐞𝐧𝐭 𝐭𝐡𝐫𝐨𝐮𝐠𝐡𝐩𝐮𝐭 𝐭𝐡𝐚𝐧 𝐨𝐭𝐡𝐞𝐫 𝐪𝐮𝐚𝐧𝐭𝐬.
I'm using it for hard classification tasks — on internal benchmarks it showed 𝐒𝐨𝐧𝐧𝐞𝐭-𝟒.𝟓-𝐥𝐞𝐯𝐞𝐥 𝐢𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 (scored well above Haiku 4.5), at a 600𝘵𝘩 of the cost. A single RTX 5090 scales up to 18 req/s at 1000in/20out 🥵.
Model card and benchmark in comments 👇
I'd love to hear your use cases.

English