Angehefteter Tweet
Krish
209 posts


Krish
@Born_TechK
Foundations now. LLM products soon. | ML • Python • Data stack | Building in public for SaaS founders
India Beigetreten Ağustos 2024
58 Folgt68 Follower
Day 5 of NLP OVERVIEW
Core learning today - Why Transformers Won(Part 2)
It's architecture :
6 encoders + 6 decoders
Each encoder = Self-Attention layer + Feed-Forward layer
Each decoder = Masked self-attention + Cross-attention + FFN
Positional Encoding
BERT vs GPT vs T5
English

Day 41📆
English:
Spoken practice
Not a good mental day.
Still showed up.
😫
#Day41 #LearningInPublic #Consistency
English
🚀 Tech stack completed so far (with projects):
✅Python
✅Data Science Stack
• NumPy
• Pandas
• Matplotlib / Seaborn (visualizations)
✅Maths
✅ML FUNDAMENTALS
🔥 Next up: NLP(Overview)
github.com/codewith-krishh
English
@SAHAJEEN @YouTubeIndia This guy is actually awesome, especially his 1 hour videos(numpy in 1 hour)
English


mention a 10/10 YouTube channel in the comments 👇
English
Stack: Python · Scikit-learn Pipelines · GridSearchCV · Cross Validation
No data leakage. Consistent preprocessing. Production-ready structure.
Full project on GitHub 👇 github.com/codewith-krish…
🧵4/4

English

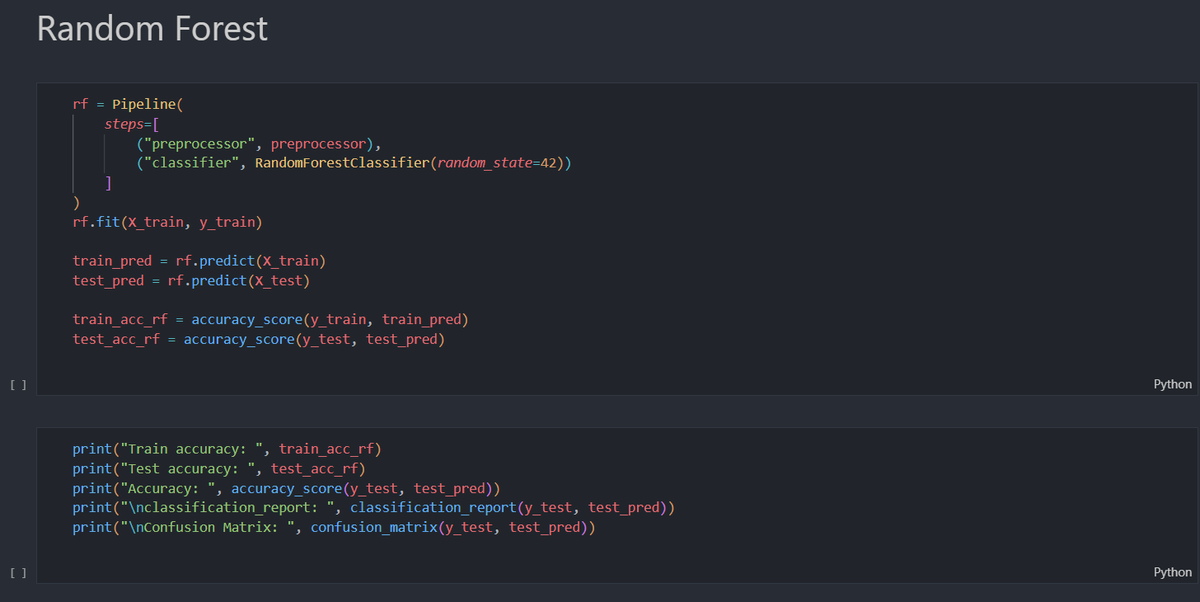
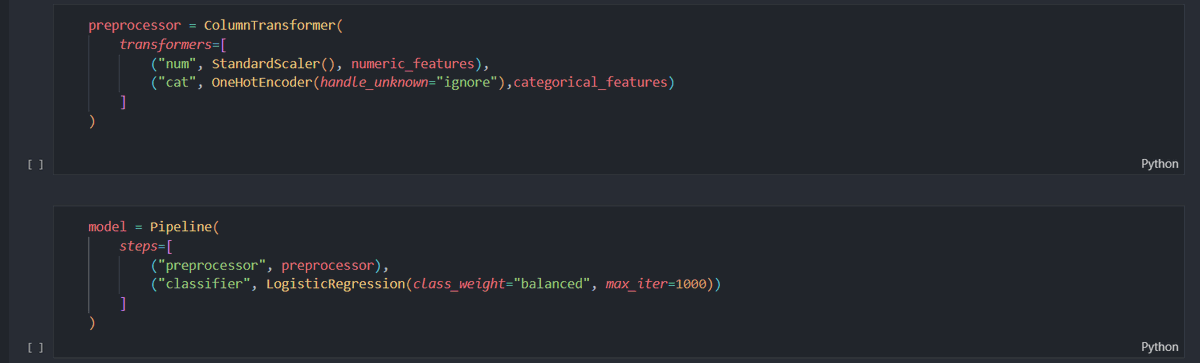
✅Day 29/35 (ML Fundamentals)
I'm just going to improve this project this week -
Today I add :
1. numeric_features
2. binary_features
3. categorical_features
Working on some other stuffs too, which I'm going to share in future (basically after learning tech stack)
Krish@Born_TechK
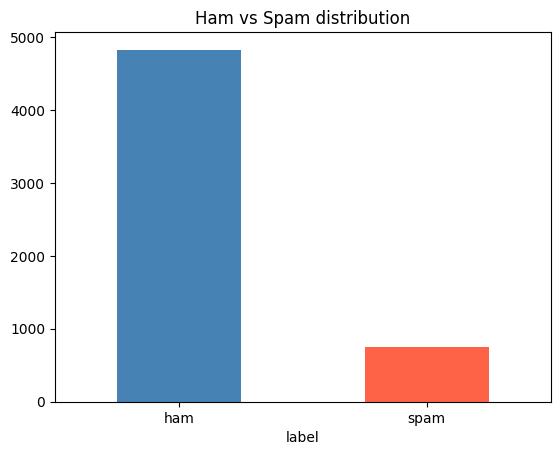
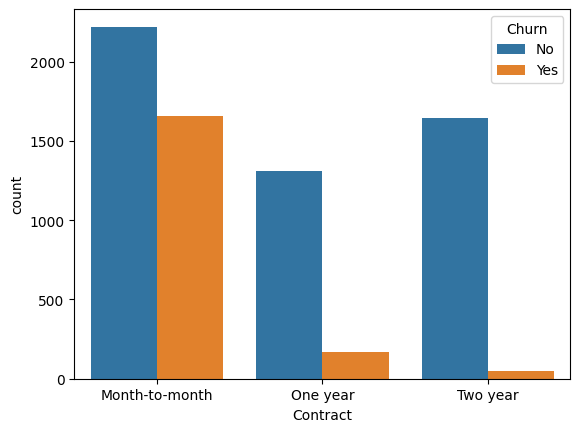
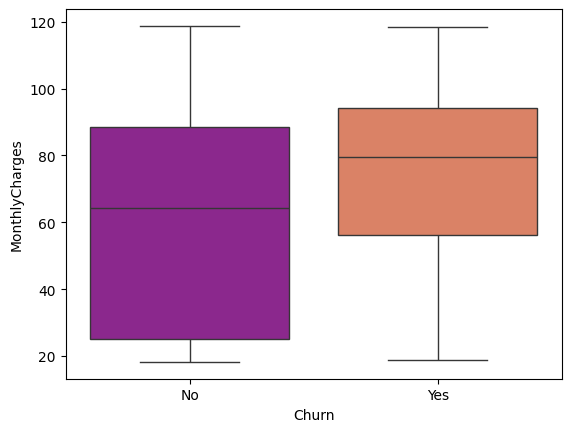
✅Day 27-28/35 (ML Fundamentals) Just shipped a Customer Churn Prediction model. 🧠 Goal: Predict which telecom customers leave - before they do. Here's the build, the results & the metric that matters most 👇 🧵 1/4 #MachineLearning #DataScience #Python
English
Accuracy can lie.
Balanced LR dropped accuracy (0.81→0.74) but recall jumped (0.56→0.78).
For business: early churn detection > a pretty score.
Next (Week 17): Pipelines · GridSearchCV · ROC-AUC · Feature importance
Repo👇
github.com/codewith-krish…
🧵 4/4
English
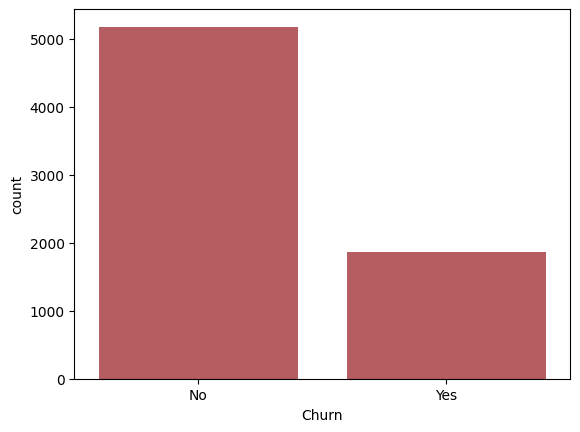
✅Day 27-28/35 (ML Fundamentals)
Just shipped a Customer Churn Prediction model.
🧠 Goal: Predict which telecom customers leave - before they do. Here's the build, the results & the metric that matters most 👇 🧵 1/4
#MachineLearning #DataScience #Python
English