Graeme@gkisokay
The LLM Cheat-Sheet for OpenClaw and Hermes agents
The goal is to choose the right models that best fit your agents' needs for as little cost as possible.
Do this and you can build a proficient agent that will never die.
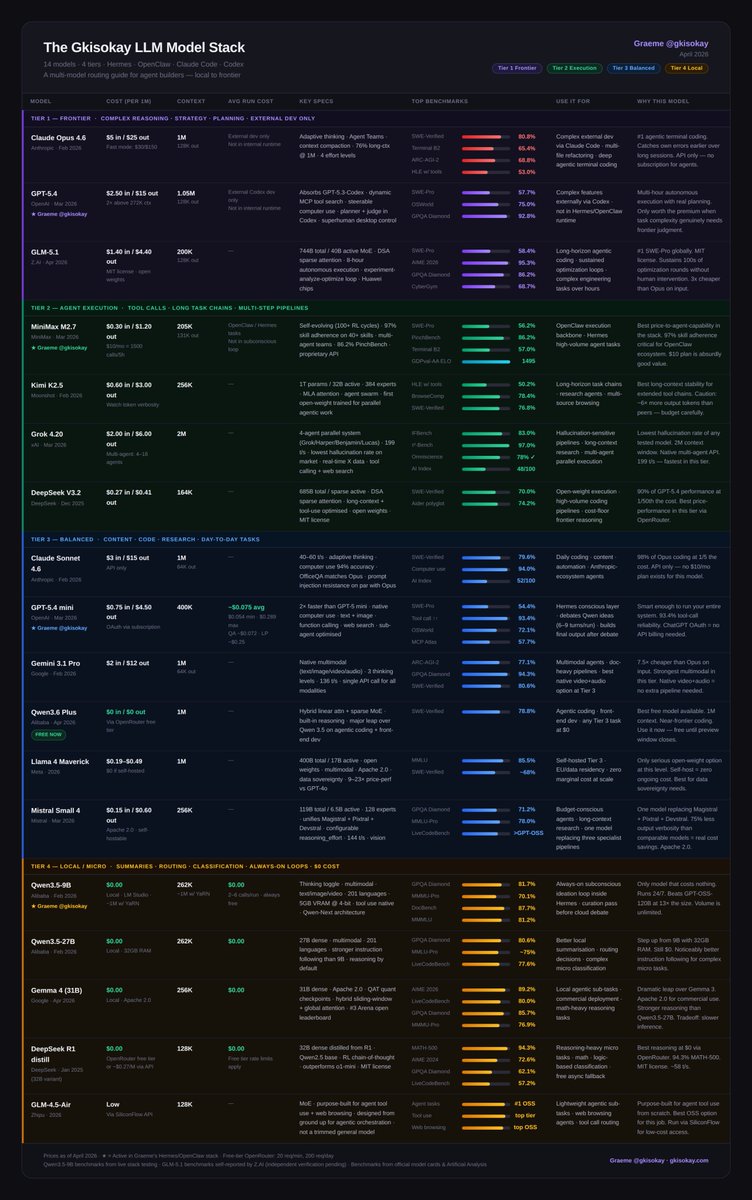
Here's the full landscape on popular models for AI agents: 12 models, 4 tiers, every one earning its place.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding
- GPT-5.4: superhuman computer use, real planning
- Gemini 3.1 Pro: best price/intelligence at frontier, native multimodal
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability
- Qwen3.6 Plus: near-frontier coding, completely free
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
Tier 4 - Local / $0
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table 🔽