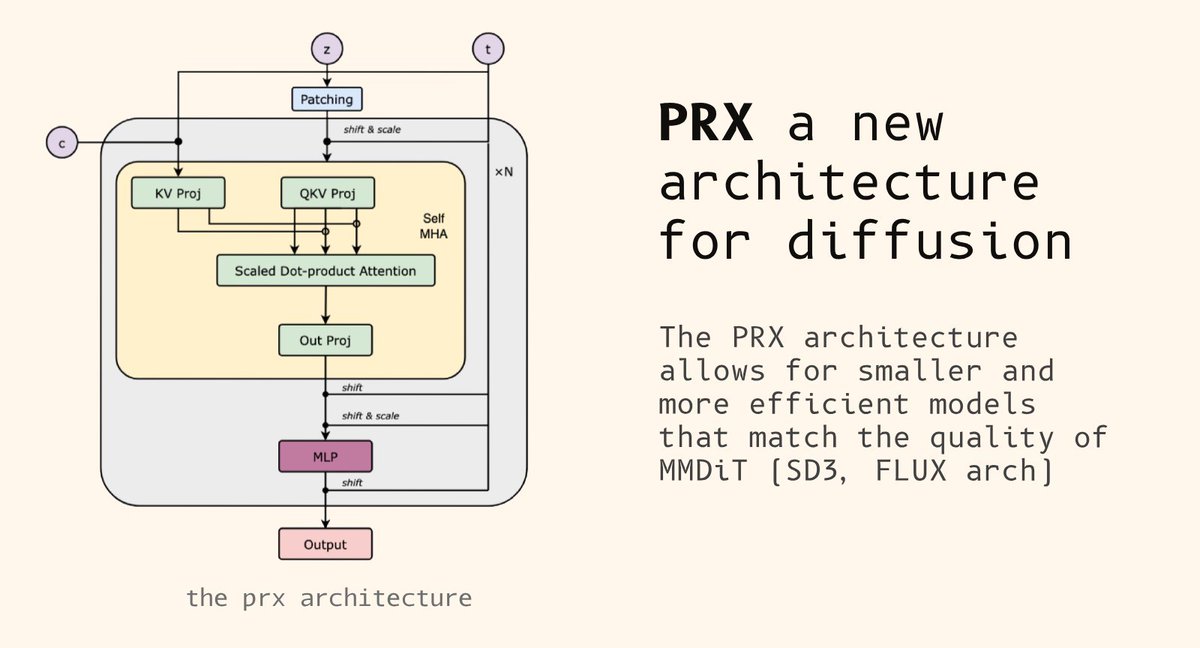
David Bert retweetet

We have been exploring JITs (arxiv.org/abs/2511.13720) a lot recently, and we are quite enthusiastic about them.
Here are some exciting results obtained in just 3.5 days on 4 nodes.
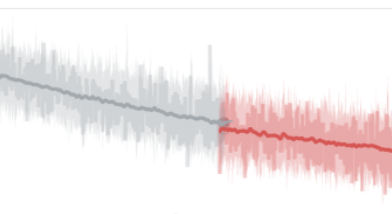
Because JITs are trained to predict x₀ directly in pixel space, we can layer standard computer-vision losses on top of the usual flow-matching objective. That’s exactly what PixelGen (arxiv.org/pdf/2602.02493…) does, using LPIPS and a DINO-based perceptual loss.
We tried replicating this with a small PRX model trained from scratch, and the results are really promising. 🧵
English