Linjie (Lindsey) Li retweetet

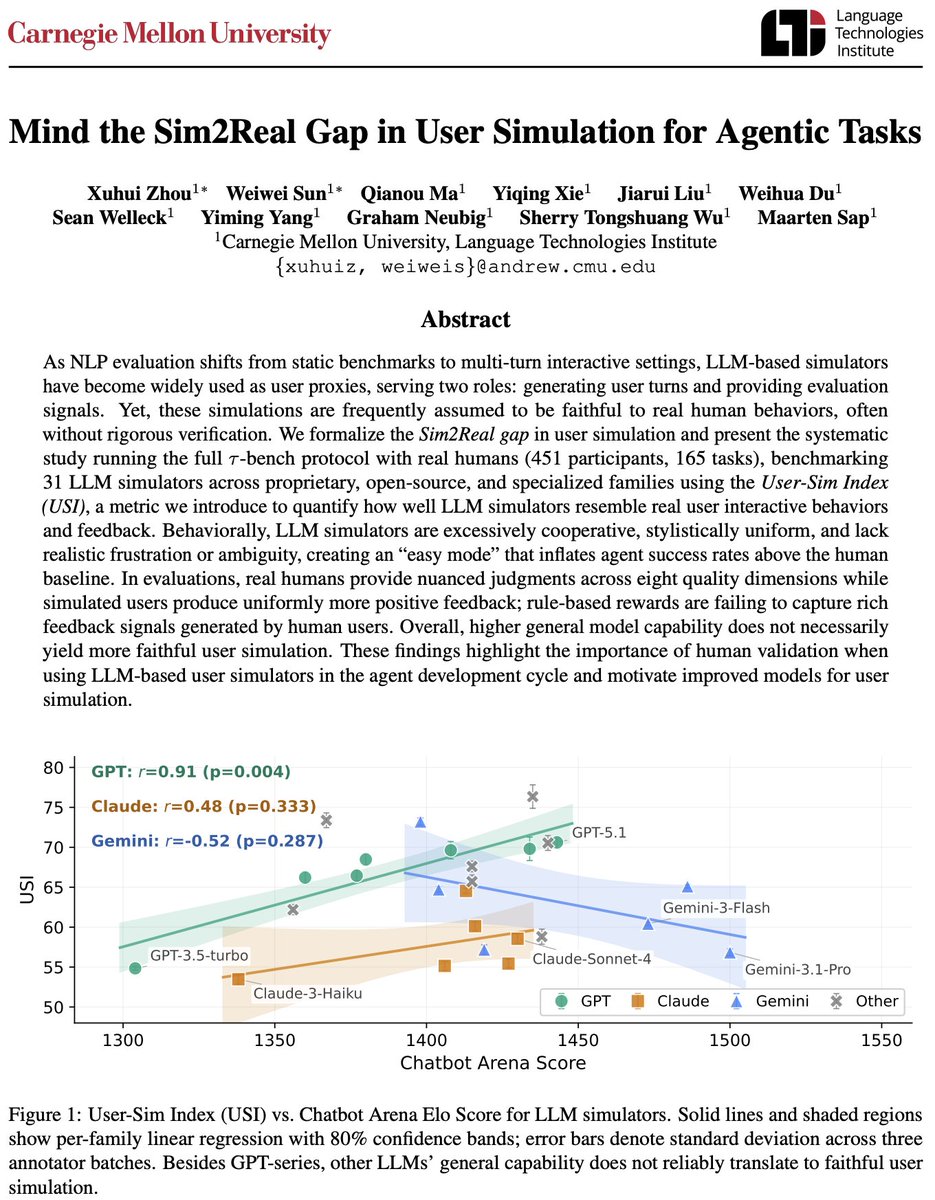
Creating user simulators is a key to evaluating and training models for user-facing agentic applications. But are stronger LLMs better user simulators?
TL;DR: not really.
We ran the largest sim2real study for AI agents to date: 31 LLM simulators vs. 451 real humans across 165 tasks.
Here's what we found (co-lead with @sunweiwei12).
English