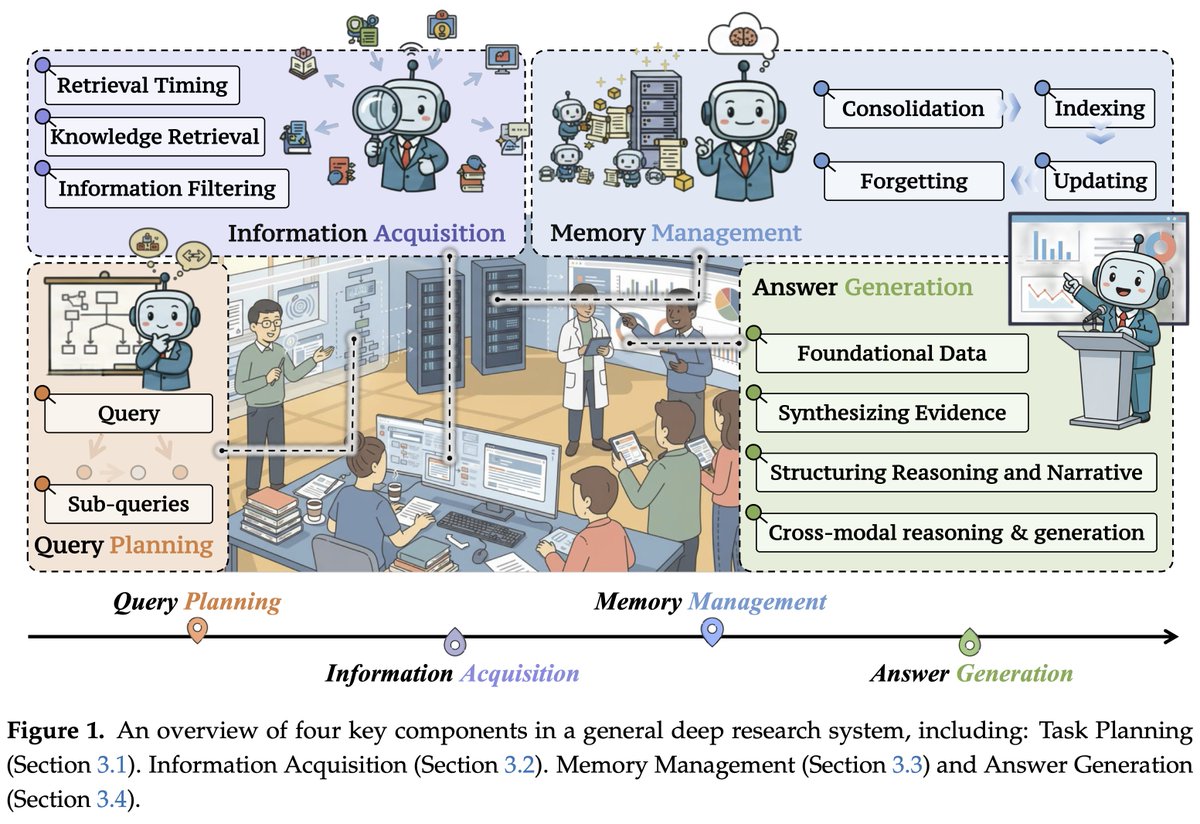
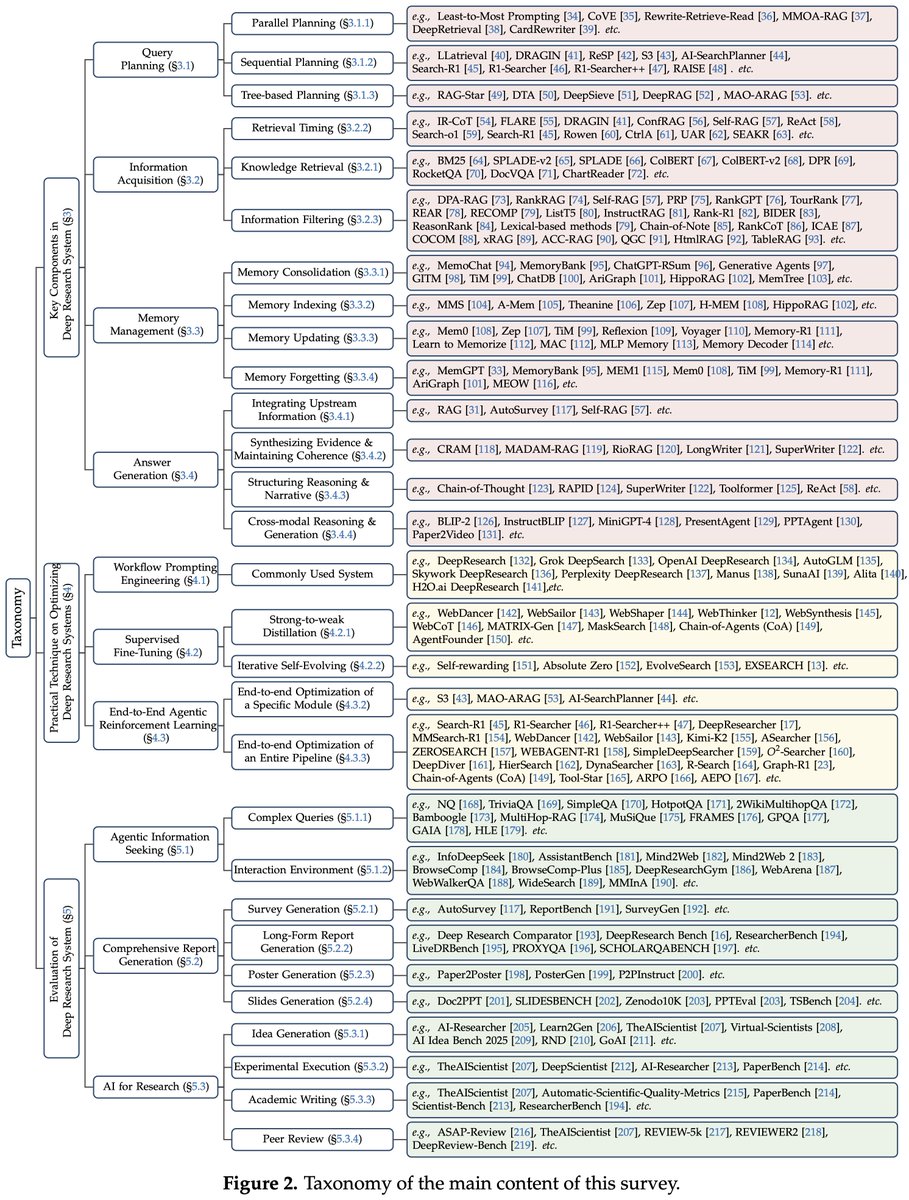
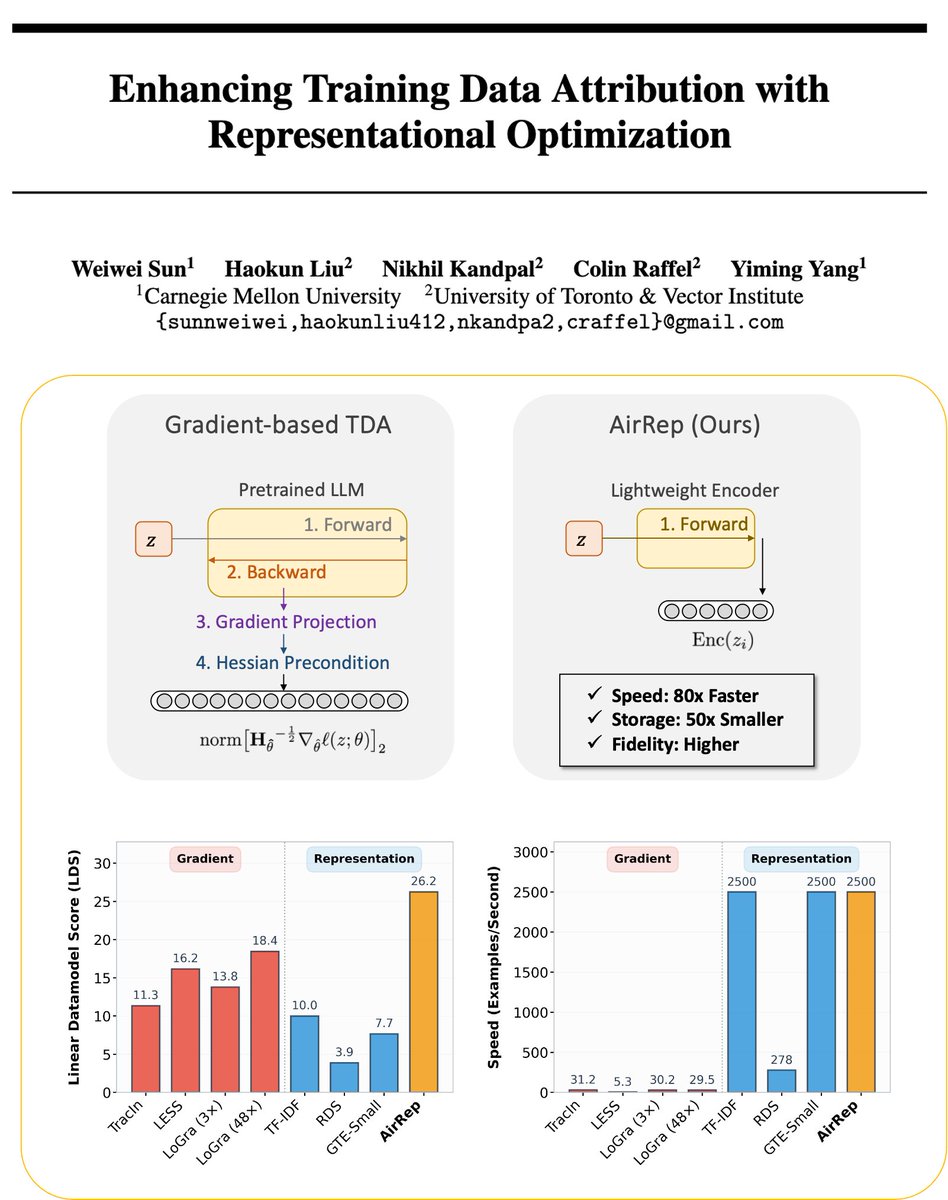
451 real users vs. LLM simulators.
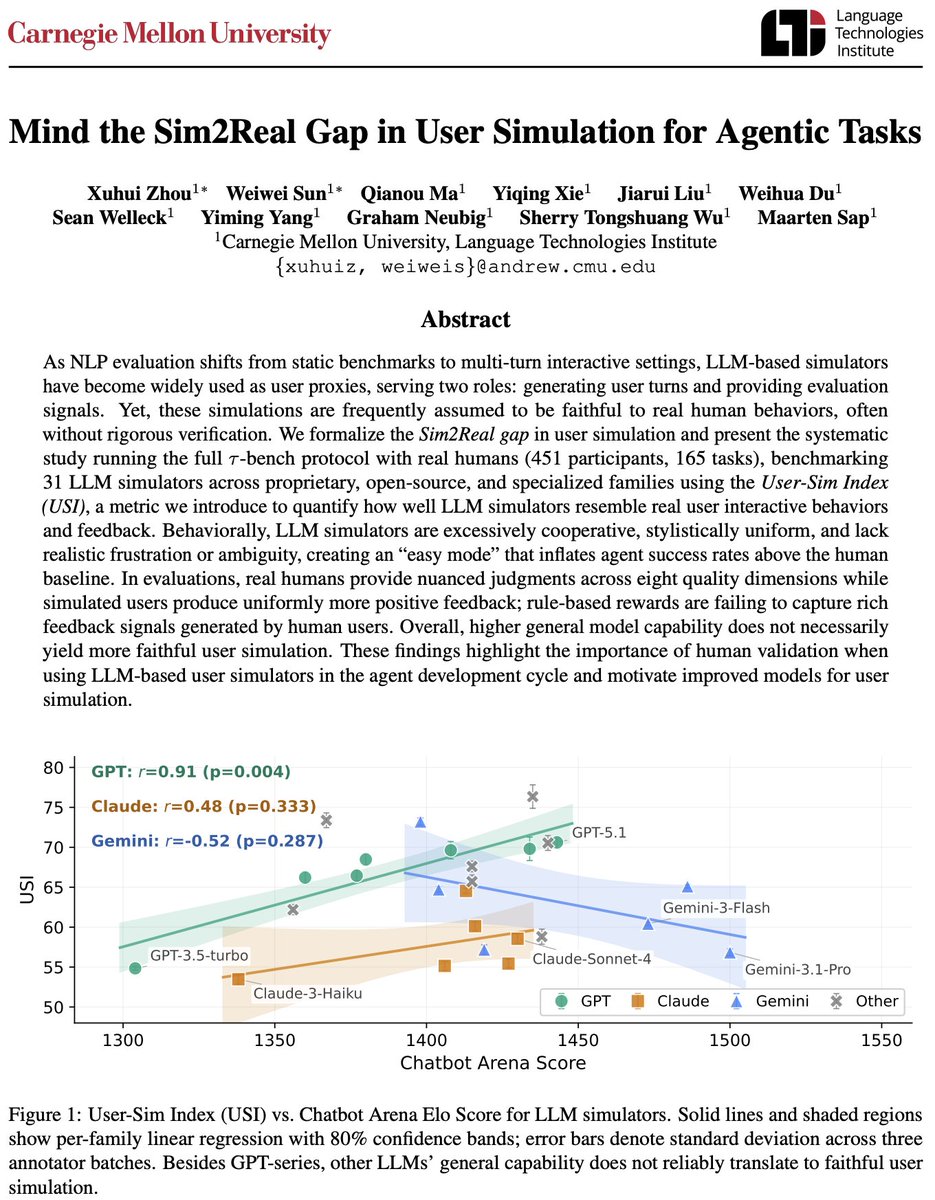
We find a clear sim2real gap across 21 behavioral dimensions. Models deviate from humans in many ways (eg too polite, too verbose)
Stronger LLMs can even be worse at simulating humans.
Check this out 👇
arxiv.org/pdf/2603.11245
Xuhui Zhou@nlpxuhui
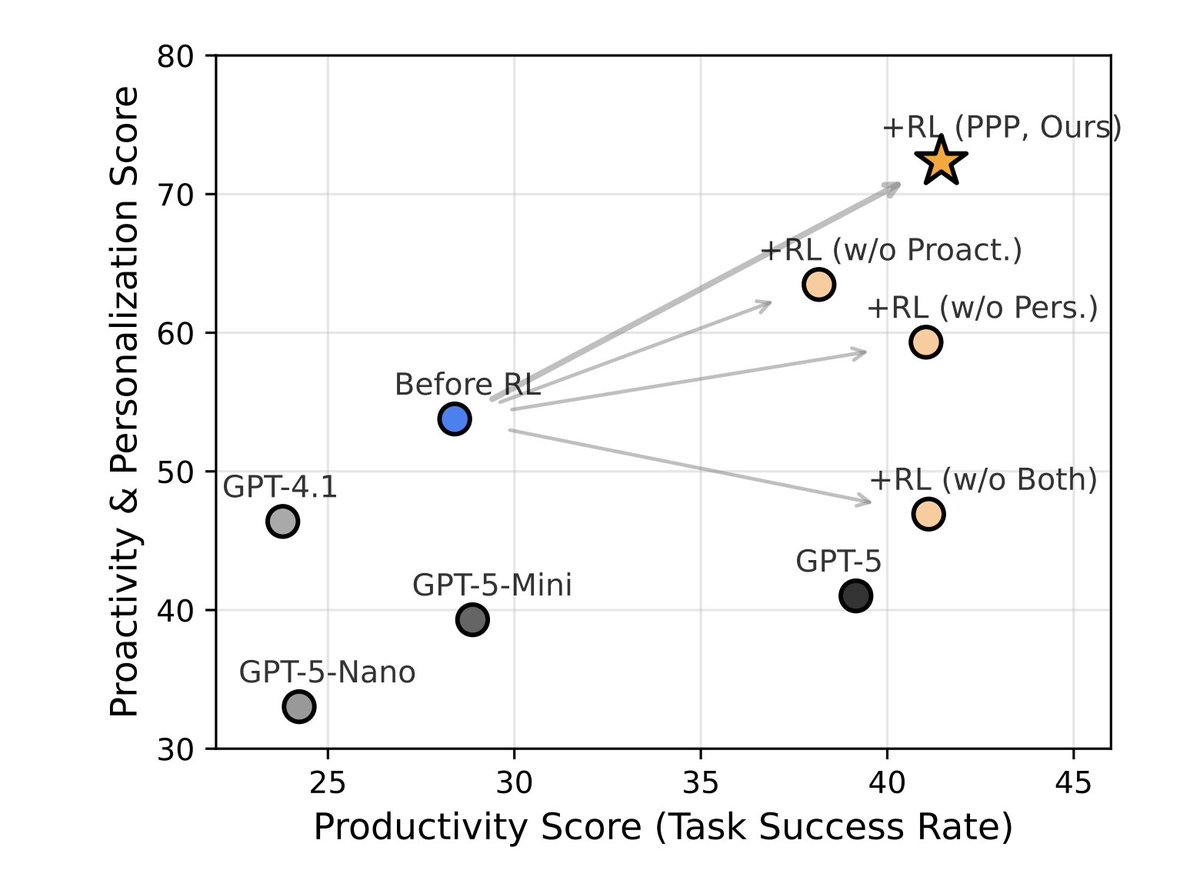
Creating user simulators is a key to evaluating and training models for user-facing agentic applications. But are stronger LLMs better user simulators? TL;DR: not really. We ran the largest sim2real study for AI agents to date: 31 LLM simulators vs. 451 real humans across 165 tasks. Here's what we found (co-lead with @sunweiwei12).
English