🚨 Breaking: Alibaba just killed the browser automation stack.
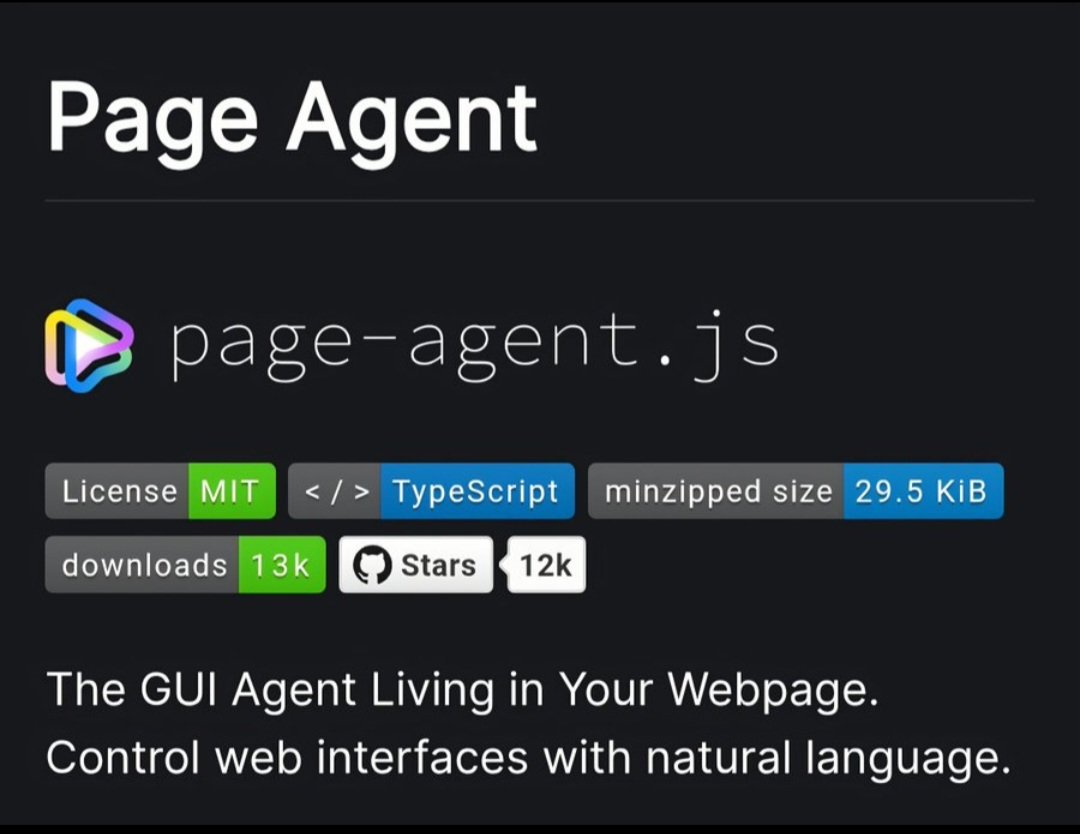
**page-agent.js** — a GUI agent that lives directly inside your webpage. No Selenium. No Puppeteer. No Chrome extension. No Python backend. Just one script tag.
It reads your DOM as text (no screenshots, no multimodal BS), brings your own LLM, and executes natural language commands like "fill out this form" or "click login" — right inside the page.
The use cases are genuinely insane:
→ Ship an AI copilot in your SaaS in literally lines of code
→ Turn 20-click ERP/CRM workflows into one sentence
→ Make any legacy web app accessible via voice or natural language
12k stars. MIT licensed. Built on top of browser-use internals — but without any of the setup overhead.
This is what "AI-native UX" actually looks like in practice
Link in comments👇
this is insane😳 developers spend weeks building apps...
writing code → fixing bugs → setting up backends → debugging deploys → repeat
and the moment requirements change, half of it breaks.
CatDoes just launched v4 — an AI agent that has its own computer in the cloud.
you describe your app. close the tab. go to sleep.
it writes the code, installs packages, runs tests, fixes its own errors.
you wake up. app is live.
it even monitors your production errors and fixes them when you ask.
no backend setup. no extra vendor. database, auth, storage — all included.
we're entering the era of describe → ship
this changes how products get built forever.
go check it out & support the launch 👇
This new SKILL.md standard might quietly become the “npm for AI agents.”
AI just got a universal skill system — and almost nobody is talking about it.
SKILL.md = a simple markdown file that turns AI into on-demand specialists.
Not prompts.
Not configs.
Actual reusable capabilities.
Here’s why this is a big deal 👇
1. Skills load only when needed
No more stuffing giant context.
Agents read name + description → load full skill → execute.
→ Faster
→ Cheaper
→ More reliable
2. One skill works across tools
Claude
Cursor
Copilot
OpenAI Codex
Gemini CLI
VS Code
Write once. Use everywhere.
That’s massive.
3. Progressive disclosure = smarter agents
Level 1: reads name + description
Level 2: loads skill body
Level 3: loads files on demand
AI now behaves like modular software, not a chatbox.
4. This unlocks "Skill marketplaces"
Imagine installing:
• review-pr → code review specialist
• growth-tweet → viral content writer
• bug-hunter → security scanner
• research-deep → analyst agent
AI becomes downloadable expertise.
5. Skills > prompts
Prompts = temporary
Skills = reusable infrastructure
This shifts AI from:
"ask better questions" → "build better abilities"
And that changes everything.
Soon workflows will look like:
Agent + Skills = Autonomous system
Not just chat.
Not just automation.
Composable AI intelligence.
The people building skills now
will control the AI ecosystem later.
This is early.
But not for long.
Bookmark this.
In 6 months, everyone will be talking about SKILL.md.
We gave an AI its own computer. It started shipping apps.
Describe what you want. CatDoes builds your mobile app or website on its own computer in the cloud. Installs the packages, runs the build, fixes its own errors.
Try it now at catdoes.com
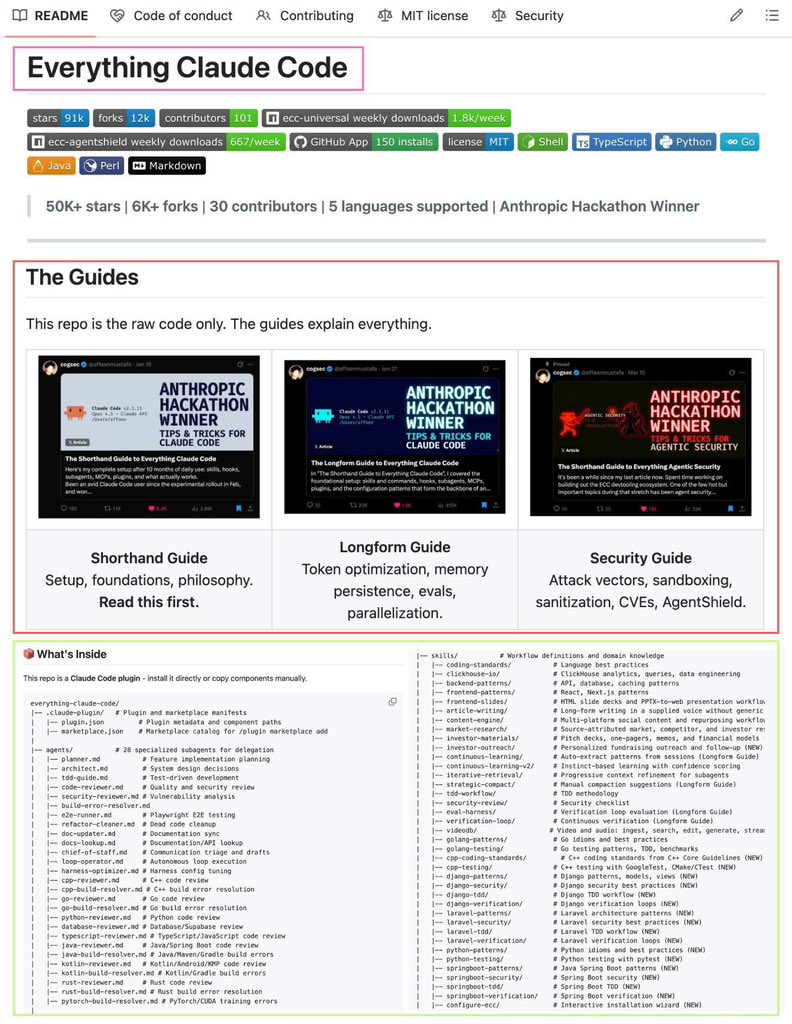
Most Claude Code setups fail before the first prompt.
Not because of skill —
because there’s no structure.
No CLAUDE.md
No skills
No hooks
No agents
No workspace memory
So Claude keeps guessing.
And you keep re-explaining.
Power users don’t rely on prompts.
They build an environment Claude can think inside.
This kind of setup turns Claude from:
“help me write this”
into
“ship this entire feature.”
If you're serious about Claude Code, save this.
You’ll want it when your workflow starts breaking.
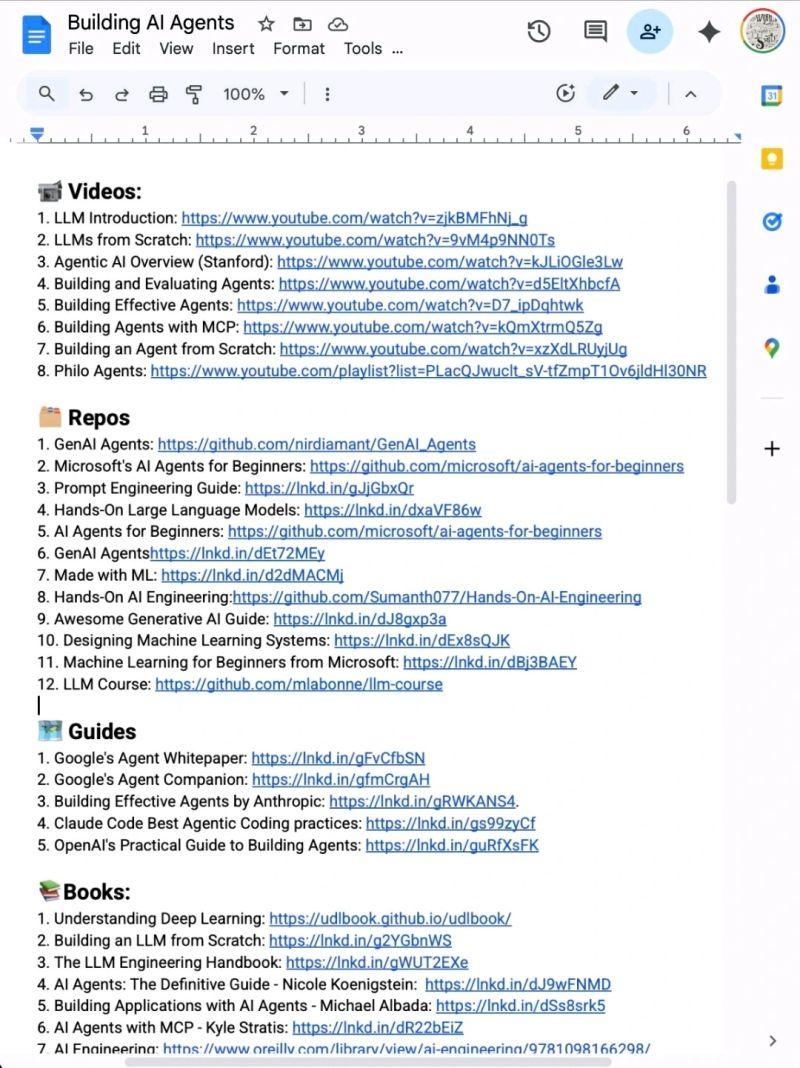
All Paid Courses (Free for First 4500 People)
𝗣𝗮𝗶𝗱 𝗖𝗼𝘂𝗿𝘀𝗲 𝗙𝗥𝗘𝗘 (PART - 1)
1. Artificial Intelligence
2. Machine Learning
3. Prompt Engineering
4. Claude,Chatgpt,Grok
5. Data Analytics
6. AWS Certified
7. Data Science
8. BIG DATA
9. Python
10. Ethical Hacking
(72 Hours only )
To get-
1. Follow me to get DM
2. Like + RT
3. Reply " All "
Most people think using Claude Code is about writing better prompts.
It’s not.
The real unlock is structuring your repository so Claude can think like an engineer.
If your repo is messy, Claude behaves like a chatbot.
If your repo is structured, Claude behaves like a developer living inside your codebase.
Your project only needs 4 things:
• the why → what the system does
• the map → where things live
• the rules → what’s allowed / forbidden
• the workflows → how work gets done
I call this:
The Anatomy of a Claude Code Project 👇
━━━━━━━━━━━━━━━
1️⃣ CLAUDE.md = Repo Memory (Keep it Short)
This file is the north star for Claude.
Not a massive document.
Just three things:
• Purpose → why the system exists
• Repo map → how the project is structured
• Rules + commands → how Claude should operate
If CLAUDE.md becomes too long, the model starts missing critical signals.
Clarity beats size.
━━━━━━━━━━━━━━━
2️⃣ .claude/skills/ = Reusable Expert Modes
Stop repeating instructions in prompts.
Turn common workflows into reusable skills.
Examples:
• code review checklist
• refactoring playbook
• debugging workflow
• release procedures
Now Claude can switch into specialized modes instantly.
Result:
More consistent outputs across sessions and teammates.
━━━━━━━━━━━━━━━
3️⃣ .claude/hooks/ = Guardrails
Models forget.
Hooks don’t.
Use hooks for things that must always happen automatically.
Examples:
• run formatters after edits
• trigger tests after core changes
• block sensitive directories (auth, billing, migrations)
Hooks turn AI workflows into reliable engineering systems.
━━━━━━━━━━━━━━━
4️⃣ docs/ = Progressive Context
Don’t overload prompts with information.
Instead, let Claude navigate your documentation.
Examples:
• architecture overview
• ADRs (engineering decisions)
• operational runbooks
Claude doesn’t need everything in memory.
It just needs to know where truth lives.
━━━━━━━━━━━━━━━
5️⃣ Local CLAUDE.md for Critical Modules
Some areas of your system have hidden complexity.
Add local context files there.
Example:
src/auth/CLAUDE.md
src/persistence/CLAUDE.md
infra/CLAUDE.md
Now Claude understands the danger zones exactly when it works in them.
This dramatically reduces mistakes.
━━━━━━━━━━━━━━━
Here’s the shift most people miss:
Prompting is temporary.
Structure is permanent.
Once your repository is designed for AI:
Claude stops acting like a chatbot...
…and starts behaving like a project-native engineer.
@korzhov_dm There's a difference between remembering someone and still being able to reach them
This is the first time that line has ever actually blurred in a real way
I'm hosting a FREE career Q&A session.
Ask me anything — breaking into AI, career transitions, building a personal brand, navigating corporate life, going independent, whatever's on your mind.
No pitch. No course. No upsell. No "stay till the end for a special offer."
Just real answers from 16+ years in enterprise tech and building a 715K+ audience from scratch.
Want in?
→ Follow me
→ Like + Repost this
→ Reply "I'M IN" below
I'll DM you the details.
Spots are limited because I want to actually answer everyone properly.
You type a prompt into ChatGPT.
~400 milliseconds and 14 infrastructure layers later, you get your answer.
Here's what happens in between:
→ Security gate checks your credentials
→ Traffic router picks the best server
→ Your words get converted to numbers (AI doesn't read English)
→ A hidden router picks which model handles your request
→ The AI "thinks" — one word at a time (95% of your wait happens here)
→ Safety filter scans the response before you see it
→ You get billed for both your question AND the answer
→ Everything gets logged
The part that surprises most people:
The AI thinking is 95% of your wait.
Everything else combined? ~16 milliseconds.
Oh, and the answer costs 3-5x more than the question.
This is how it works at OpenAI, Anthropic, Google, Mistral, and every major provider.
Full architecture visual below ↓
What part of this surprised you?
Claude Code's 512K-line source just leaked.
Everyone focused on the drama.
I focused on the memory architecture.
3 layers:
Layer 1: MEMORY.md — a pointer index, not storage. 150 chars/line. Always loaded.
Layer 2: Topic files — detailed .md files loaded on-demand only when relevant.
Layer 3: Raw transcripts — never reloaded. Just grep searched.
The wildest part?
"Skeptical Memory" — the agent treats its own memory as a hint, not fact. It verifies everything against the actual codebase before acting.
And if something can be re-derived from source code, it doesn't get stored at all.
This pattern is model-agnostic. Steal it.