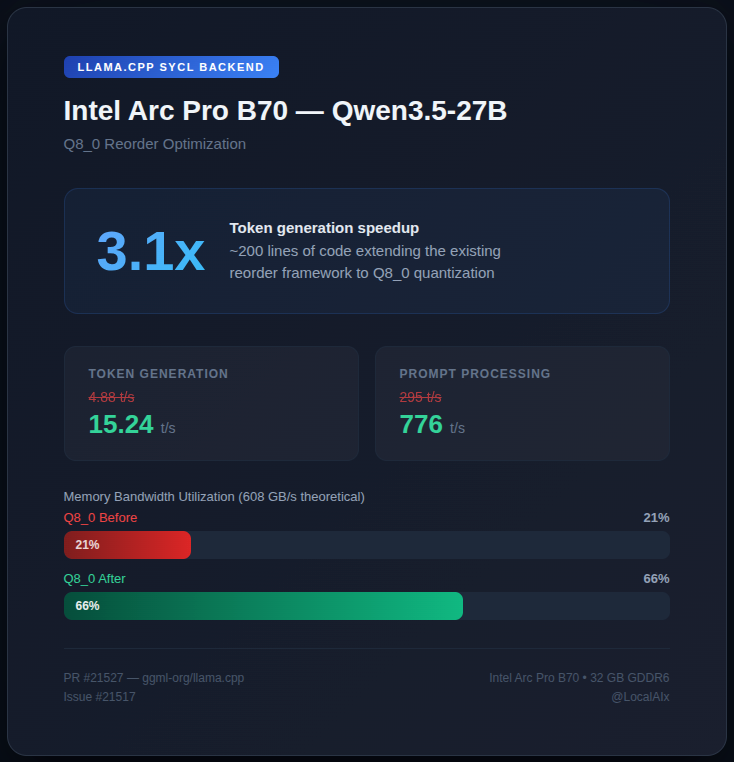
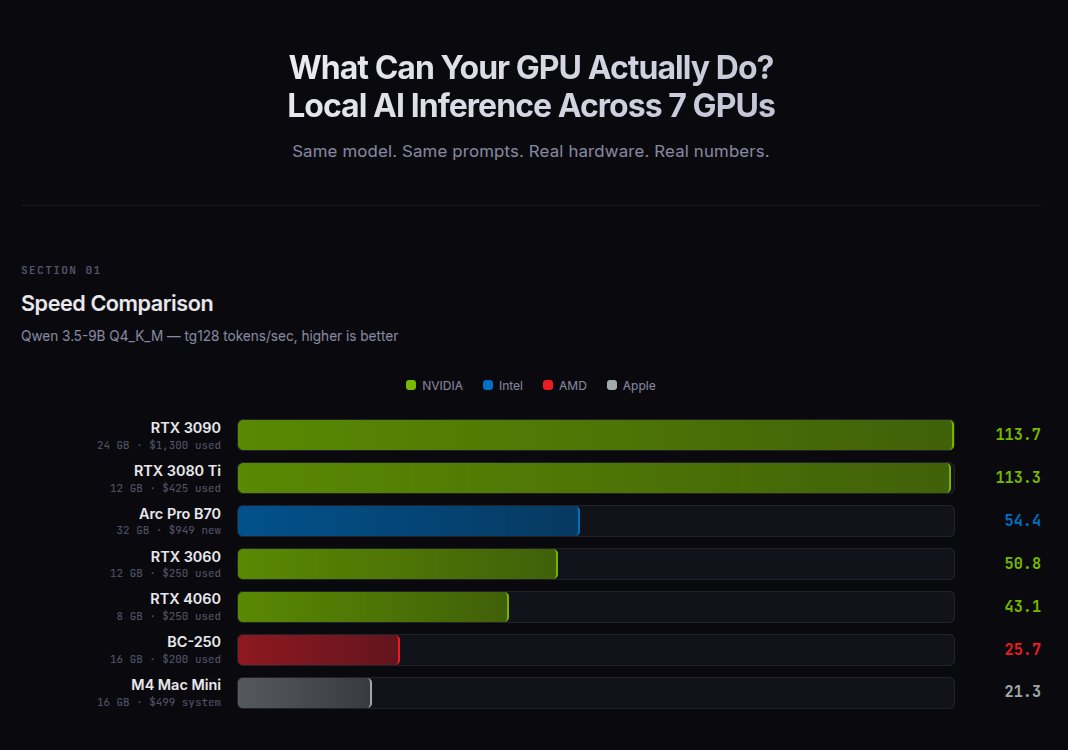
I ran the same 9B model on 7 GPUs from $200 to $1,300.
RTX 3080 Ti: 113 t/s ($425)
RTX 3090: 113 t/s ($1,300)
Arc Pro B70: 54 t/s ($949)
RTX 3060: 51 t/s ($250)
RTX 4060: 43 t/s ($250)
BC-250: 26 t/s ($200)
M4 Mac Mini: 21 t/s ($499)
The 3080 Ti matches the 3090 at 1/3 the price.
But both are capped at models that fit in VRAM.
More VRAM = bigger models = smarter AI.
The B70 runs a 35B model on one card. Two cards run 80B.

English