えの
37.6K posts


tinggal pake vpn jepang terus ganti country yang ada di page chatgptnya. Udah kelar
➳uchiha@uciuchiha
Gpt plus Akhirnya bisa juga, cuma Rp 1 Bayar pake GoPay
Indonesia





えの retweetet

Did this work? CTF saving humanity

Anthropic@AnthropicAI
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Claude models is not affected. We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible. Read our full statement: anthropic.com/news/fable-myt…
English
えの retweetet


えの retweetet

The Hidden Geometry of Trigonometric Functions and the Unit Circle.
English
えの retweetet

えの retweetet

1/ What if we treated LLM prompt engineering not as vibes, but as rigorous, validation-gated gradient descent?
By formalizing natural language skills as trainable parameter states, we can systematically optimize LLM agents with zero inference-time overhead. 🧵

English
えの retweetet

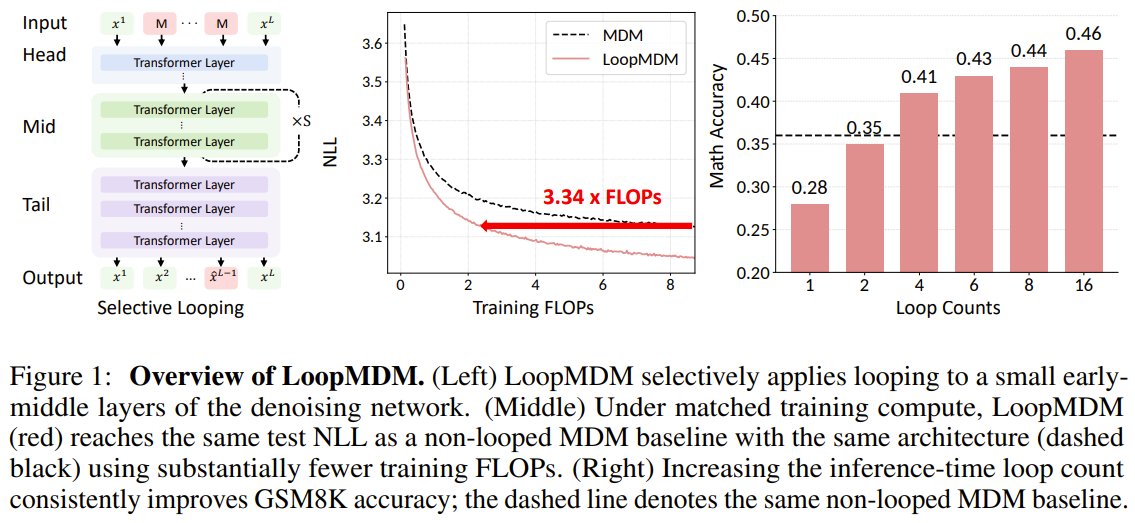
What if you could make AI language models smarter by reusing the same layers over and over?
Researchers from KAIST, KRAFTON, and UC Berkeley present LoopMDM(Looped Diffusion Language Models).
They selectively loop early-middle transformer layers in masked diffusion models—no extra parameters, just smart recycling of computation.
The result? LoopMDM matches standard models with 3.3x less training compute, then beats them on reasoning benchmarks like GSM8K by up to +8.5 points. It even outperforms deeper models trained with equal compute, and can scale performance at inference by looping more. Simplicity that punches above its weight.
English