Angehefteter Tweet
네프티
2.8K posts


네프티
@NeftyMinerva
과학, 수학, 그림, 퍼리, 역사, 대륙철학, 컴퓨터, 일렉트로니카 좋아하는 20대 고양이입니다 야옹~
Republic of Korea Beigetreten Haziran 2025
169 Folgt121 Follower
네프티 retweetet




네프티 retweetet
🐩 심심할떼 하는 교류롤렛 feat.벌칙많음
──────────────────
진진따리님은 알티한 트친에게 그림그려주기~🎨
gaeyou.com/t/?268764
ㅇ왓!! 대충.. 끄적여볼게욥..!
한국어
네프티 retweetet

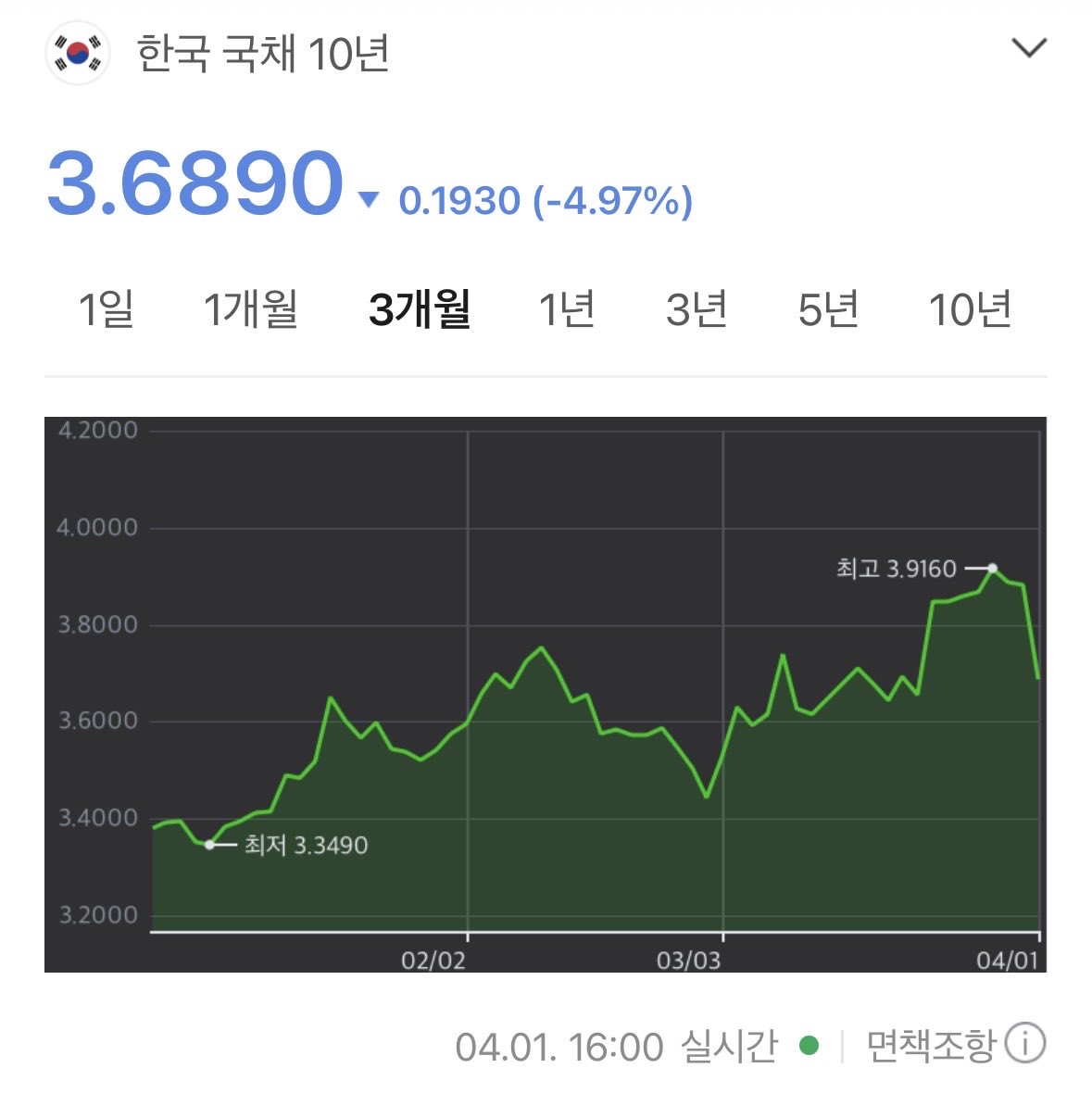
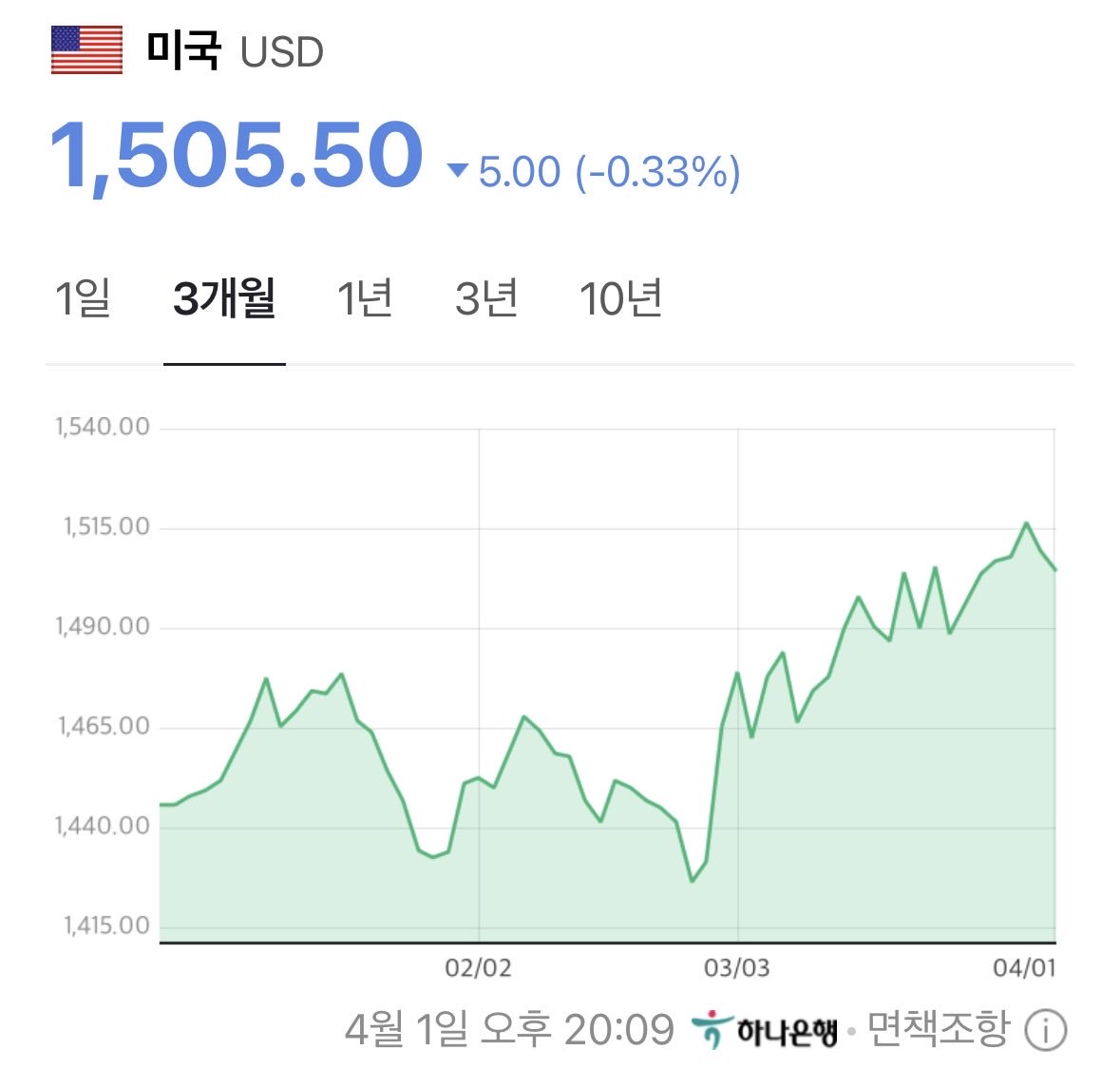
이거 아시나요? 오늘 주식이 오른 이유 중 하나
- 오늘(4월 1일)부터 한국 국채가 WGBI라는 글로벌 채권지수에 들어가기 시작함
- WGBI는 쉽게 말해 전 세계 주요 선진국 국채만 모아놓은 리스트임. 미국 영국 일본 같은 나라들이 여기 들어가 있었고 오늘부터 한국도 합류함
- 이 지수를 따라 자동으로 투자하는 글로벌 자금이 한국 국채를 사들이기 시작함
- 큰돈이 한꺼번에 국채를 사면 국채 가격이 오르고 금리는 반대로 내려감.
- 국채 금리가 내려가면 대출 금리와 회사채 금리도 따라 내려가서 기업들이 돈 빌리는 비용이 줄어듦
- 돈 빌리는 비용이 싸지면 반도체처럼 공장 짓고 장비 사는 데 돈이 많이 드는 기업들이 특히 유리해짐
- 외환시장도 안정되면서 원화 가치가 오르는 방향으로 움직일 것으로 예상됨
- 결국 금리 하락과 환율 안정이 동시에 오면서 외국인 입장에서 한국 주식이 더 매력적으로 보이게 됨
- 4월부터 11월까지 8단계로 나눠 진행되는 구조라 효과가 한번에 오는 게 아님.
- 오늘은 시작일 뿐이고 앞으로 8개월이 더 남았음
한국어
네프티 retweetet


네프티 retweetet

💸 일타강사 정승제가 EBS 강의를 15년째 계속하는 감동적인 이유
1. 본래 돈이 되는 강의만 골라서 하던 유명 강사 정승제는 거의 무료인 EBS 강의를 맡으면서 처음으로 마음이 정화되는 특별한 기분을 느꼈음
2. 그러던 중 "수익도 안 나는데 계속해야 하나"라는 현실적인 고민에 빠지게 되었지만, EBS 시상식에서 만난 학생들의 사연이 그의 마음을 완전히 돌려놓음
3. 한 학생은 어려운 가정 형편 때문에 오전에는 농사를 짓고 밤에만 그의 강의를 듣고 공부한 끝에 교대에 합격했다며 눈물로 감사를 전함
4. 또 다른 청각 장애 학생은 소리를 잘 듣지 못하지만, EBS 강의의 자막을 보며 공부한 덕분에 고려대학교 교육학과에 합격했다는 소식을 전함
5. 학생들의 진심 어린 눈물과 성공담을 들은 정승제 강사 역시 함께 울며, 그동안 했던 자신의 고민이 너무나 하찮았음을 깨닫게 됨
6. 이 경험을 계기로 그는 형편이 어려운 학생들을 위해 "평생 EBS에서 수업하겠다"는 숭고한 다짐을 하게 되었음
7. 그 약속을 지키기 위해 바쁜 일정 속에서도 벌써 15년이라는 긴 시간 동안 EBS의 대표 강사로 자리를 지키며 선한 영향력을 전파하고 있음
8. 고액의 수강료를 지불해야 하는 사교육 시장의 일타강사임에도 불구하고, 교육의 기회균등을 위해 헌신하는 모습이 많은 이들에게 큰 귀감이 됨
9. 단순히 지식을 전달하는 것을 넘어 누군가의 인생을 바꾸는 교육의 진정한 가치를 몸소 보여주는 멋진 행보임
10. 돈보다 소중한 가치를 발견하고 실천하는 그의 모습에 많은 네티즌들이 "진짜 멋지다", "이게 진정한 스승의 모습이다"라며 극찬을 보내고 있음

한국어


Mountain fuji?
Earth@earthcurated
What’s the first thing that comes to mind when you hear the words "Japan"?
Indonesia
네프티 retweetet

하버드 심리학 교수가 말하는 소름돋게 정확한 '인간관계의 진실'
누군가 당신을 대하는 태도는
그 사람의 그릇을 보여주는 것이지,
당신의 가치를 말해주는 게 아니에요
누군가 당신을 함부로 대하나요?
불친전하게 구나요?
그건 당신 탓이 아니에요
그냥 그들의 마음상태가 그만큼 어지럽고
어둡고 힘들다는 걸 보여주는 증거일 뿐이죠
이 사실을 이해하게 되면
불친절한 상대에게 휘둘리지 않게 됩니다.
당신의 마음 상태도, 인생의 주도권도
더는 흔들리지 않을 거에요
그리고 그런 사람을
그냥 놔두는 법을 알게되죠
이건 용서 같은 게 아니에요
오히려 그 사람을 용서할 필요조차
없는 수준에 이르는거죠
그 순간, 당신은 비로소 온전히 자유로워 질겁니다
상대의 마음 속 어지러움까지
내가 정리해줄 의무는 없습니다.
어떤 마음은 그 사람의 몫이고,
어떤 경계는 내 몫이에요
그걸 구분해내는 순간,
불필요한 죄책감도, 억울함도
조용히 제자리로 돌아갑니다.
한국어
우리 지역 당근에도 이상한 뉴스 들고와서 빚내서 복지해준다 뭐 그런 뉘응스 글들 많이 올라오는데…
알고봤더니 악당들에게서 몰수한 현금 일부분만 쓰는거였다.
플루토11호@Pruto11_
아니 이 븅신들이 진짜 빚내서 하는게 아니고 작년 4분기에 체납자 때려잡고,법인세 등등 한거를 편성한거야. 세금낸걸 다시 돌려주는거라고!! 그리고 총 예산중 6조 정도가 민생지원금이고 20조가 넘는 돈으로 수출 지원, 나프타+석유 비축 하겠다는데 기름을 사오라는게 뭔씹 그거 하고있다고!!
한국어



네프티 retweetet

미친 LLM 마법사(전문가)들이 이제 터보 퀀트 이론을 KV cache 뿐 아니라 Model 전체에 적용하고 있습니다.
즉, 과거엔 꿈도 못 꾸던 소비자향 GPU/Vram에서 모델들이 돌아갈 수 있게 됩니다.
그럼 이제 AI 하드웨어들은 끝이냐고요? 그럴리가 있겠습니까?
메모리 대역폭 + 연산 능력 + 충분한 공간의 삼위 일체 중 마지막 세번째의 금제가 조금 풀렸을 뿐입니다. 그리고 로컬 모델을 돌리는 데는 모델 파라메터 로딩과 KV cache만 필요한 게 아닙니다.
전 세계 모든 인구가 각자의 GPU를 원한다고 생각해보세요. 중고 시장의 GPU는 순식간에 사라질테고 미친듯한 디맨드가 요청되는 순간입니다.
am.will@LLMJunky
These absolutely insane LLM wizards are now experimenting with Turboquant not just to compress KV cache, but now, the entire model itself. This test showed a >50% reduction in memory footprint, allowing for Qwen 3.5-27B to be run on a single RTX 5060 @ 3.15bit precision - with no apparent degradation. This just goes to show that we're likely nowhere near full optimization for existing models. We are likely <1yr away from running big models on smol devices with minimal consequence. And during that time, they will only get better and better. What a time to be alive.
한국어