Angehefteter Tweet

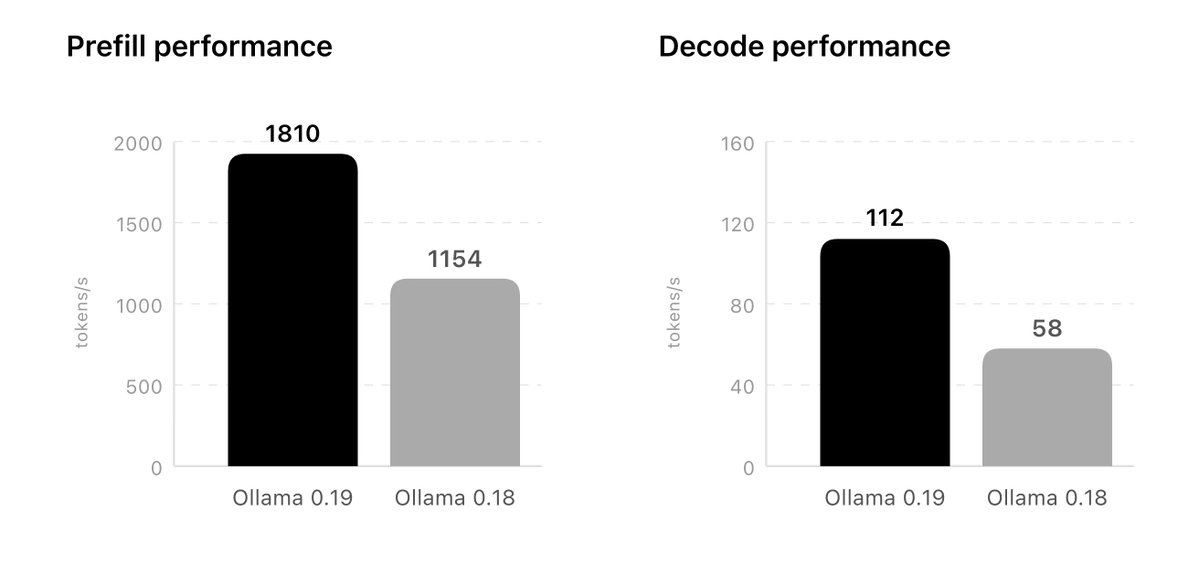
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework.
This change unlocks much faster performance to accelerate demanding work on macOS:
- Personal assistants like OpenClaw
- Coding agents like Claude Code, OpenCode, or Codex
English