Angehefteter Tweet

Today, we are emerging from stealth and launching PrismML, an AI lab with Caltech origins that is centered on building the most concentrated form of intelligence.
At PrismML, we believe that the next major leaps in AI will be driven by order-of-magnitude improvements in intelligence density, not just sheer parameter count.
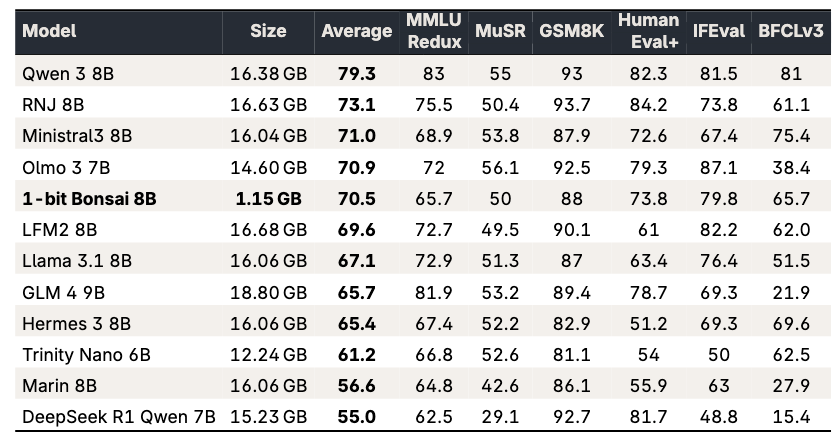
Our first proof point is the 1-bit Bonsai 8B, a 1-bit weight model that fits into 1.15 GBs of memory and delivers over 10x the intelligence density of its full-precision counterparts. It is 14x smaller, 8x faster, and 5x more energy efficient on edge hardware while remaining competitive with other models in its parameter-class.
We are open-sourcing the model under Apache 2.0 license, along with Bonsai 4B and 1.7B models.
When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately. We believe in a future of on-device agents, real-time robotics, offline intelligence and entirely new products that were previously impossible.
We are excited to share our vision with you and keep working in the future to push the frontier of intelligence to the edge.

English