@marmaduke091 Now we need a feature to store and load contexts :D .. and that's basically a memory now.
English
Andrej Szontagh
1K posts


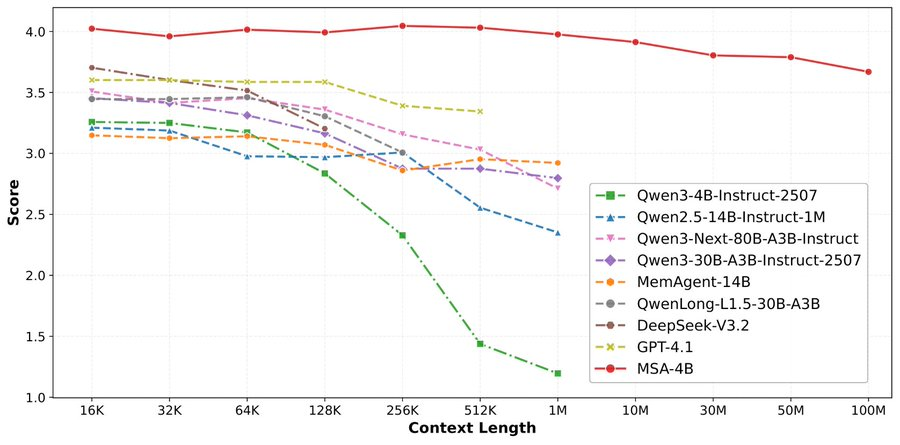
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA



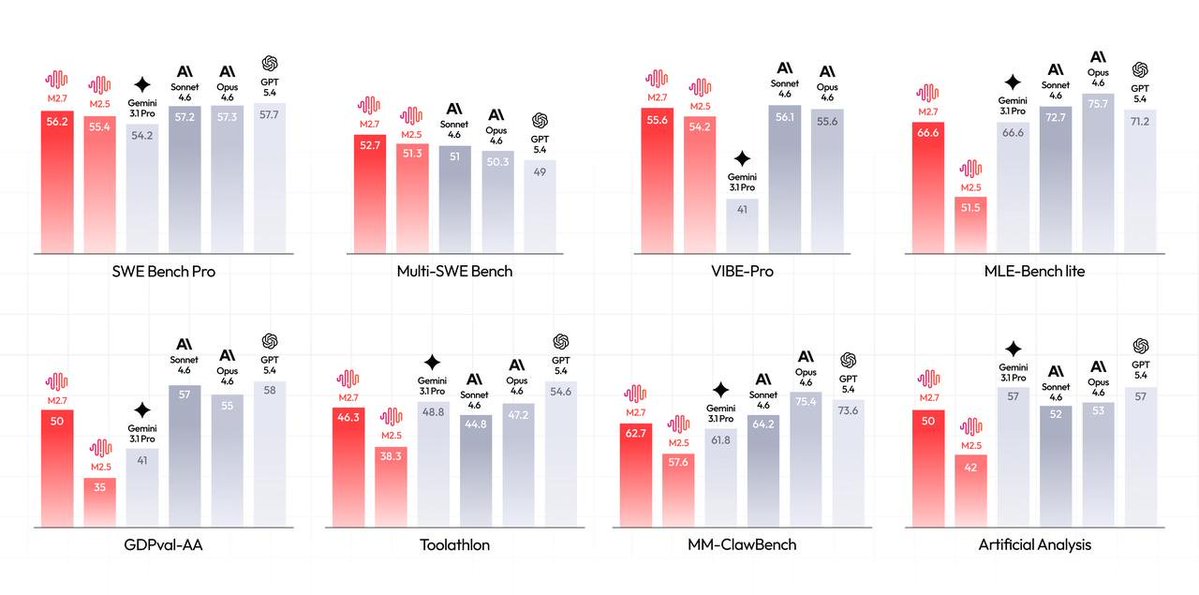
Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5 - Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents to 3-min on certain occasions. - Advanced Agentic Abilities: Trained for Agent Teams and tool search tool, with 97% skill adherence across 40+ complex skills. M2.7 is on par with Sonnet 4.6 in OpenClaw. - Professional Workspace: SOTA in professional knowledge, supports multi-turn, high-fidelity Office file editing. MiniMax Agent: agent.minimax.io API: platform.minimax.io Token Plan: platform.minimax.io/subscribe/toke…


Grok 4.20 is now officially out of Beta. It's now on Auto, Fast, Expert & Heavy.

After this whole debate about DLSS 5 I came to the conclusion that most of the people talking about it are completely unaware of what they don't know...they're on the peak of ignorance and don't even grasp how little they understand. They just heard generative AI and like Pavlov's dog they just start drooling thinking it's the same shit as unethical slop image generators...for the love of Christ...go and educate yourself before raging on the internet for no reason. DLLS 5 is not a prompt based generator...it's not creating stuff based on someone else's images and hallucinates results. It uses the information from the raster to build up a final render frame with the same information but with better lighting and shading... I'll even give you an example on how much of an impact better shading and lighting has. This is a character I've worked on not long ago. On the left you have a raster render, with some bad shaders. On the right you have a render with raytrace on, a much better shader for both hair and skin. They don't even look like the same person...do they? This is what DLSS5 is doing....getting a result like the one on the right(tbh a lot better) at a smaller cost than actually rendering it. Still the same geo, same textures, same light sources. Some of you will go and say the one on the left is better and it's the artist's vision. It's not...it's just the artist's limitation due to shading and lighting constrains. Every single artist out there would love to get the right result in real time.


What's your AI adoption level? (according to Steve Yegge)



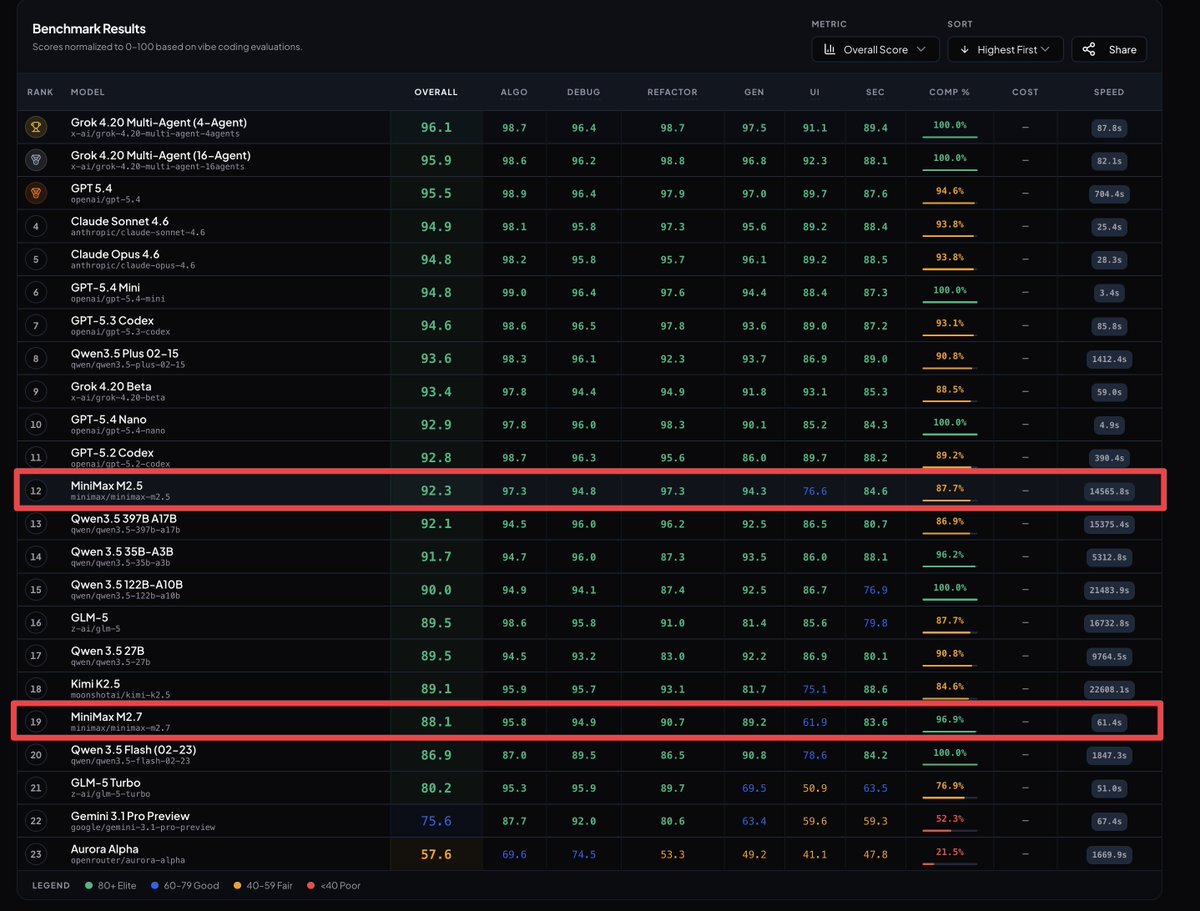



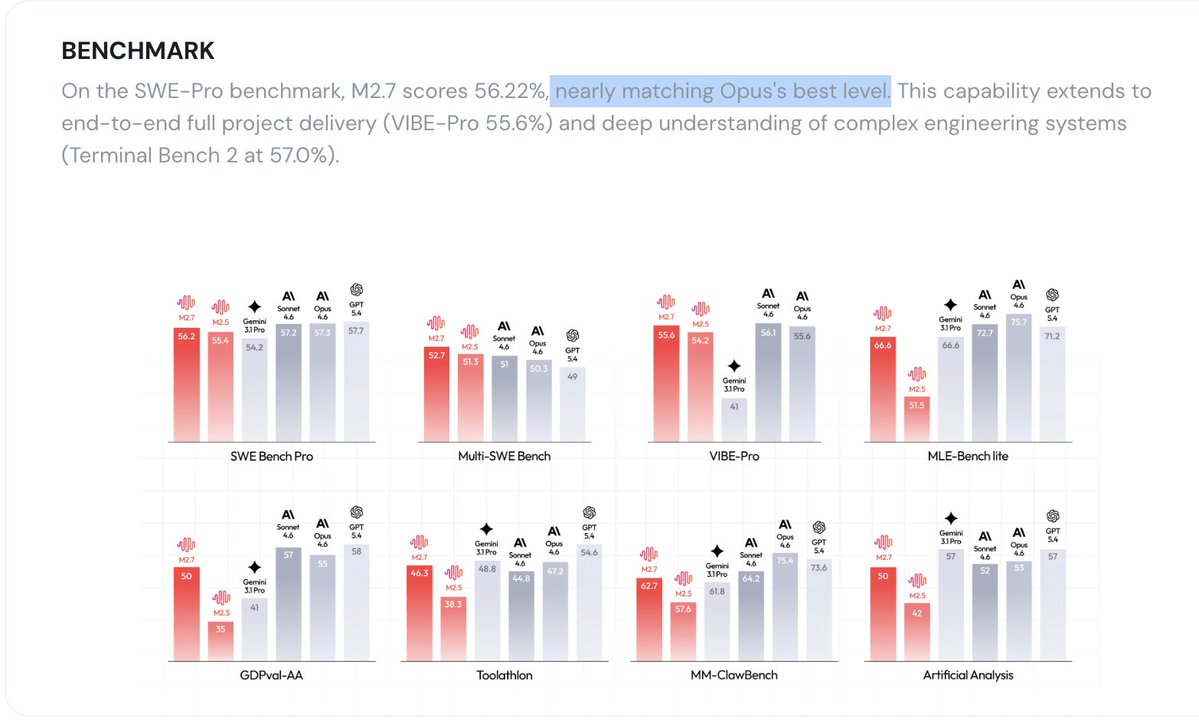

MiniMax-M2.7 just landed in MiniMax Agent. The model helped build itself. Now it's here to build for you. ↓ Try Now: agent.minimax.io

What opinion will get you in this position?



If DLSS 5 is ‘AI slop,’ but current in-market DLSS, FSR, frame gen, PSSR, etc. are fine, then your problem clearly isn’t AI. So what is it? Defend your position without virtue signaling. Replies are open.