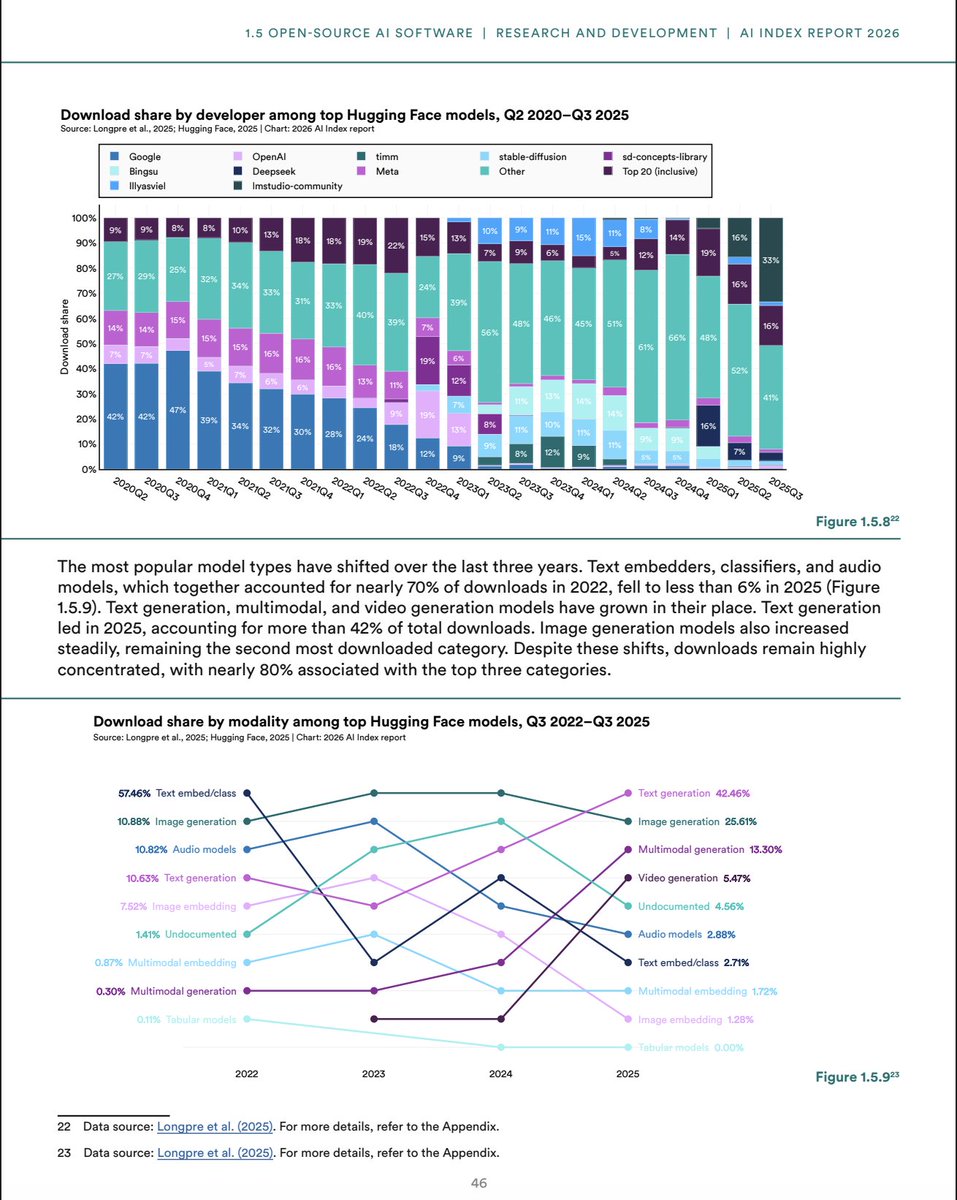
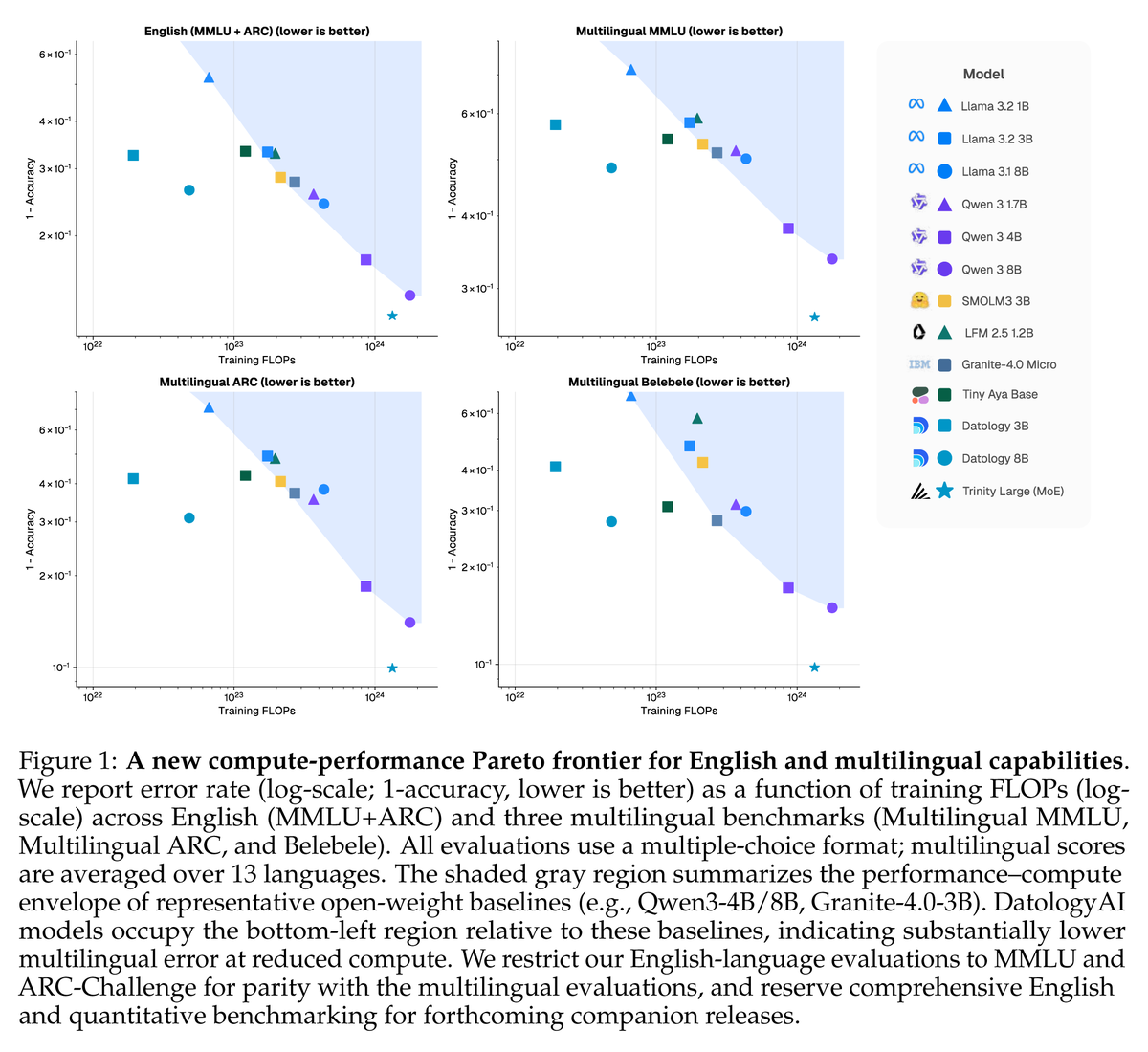
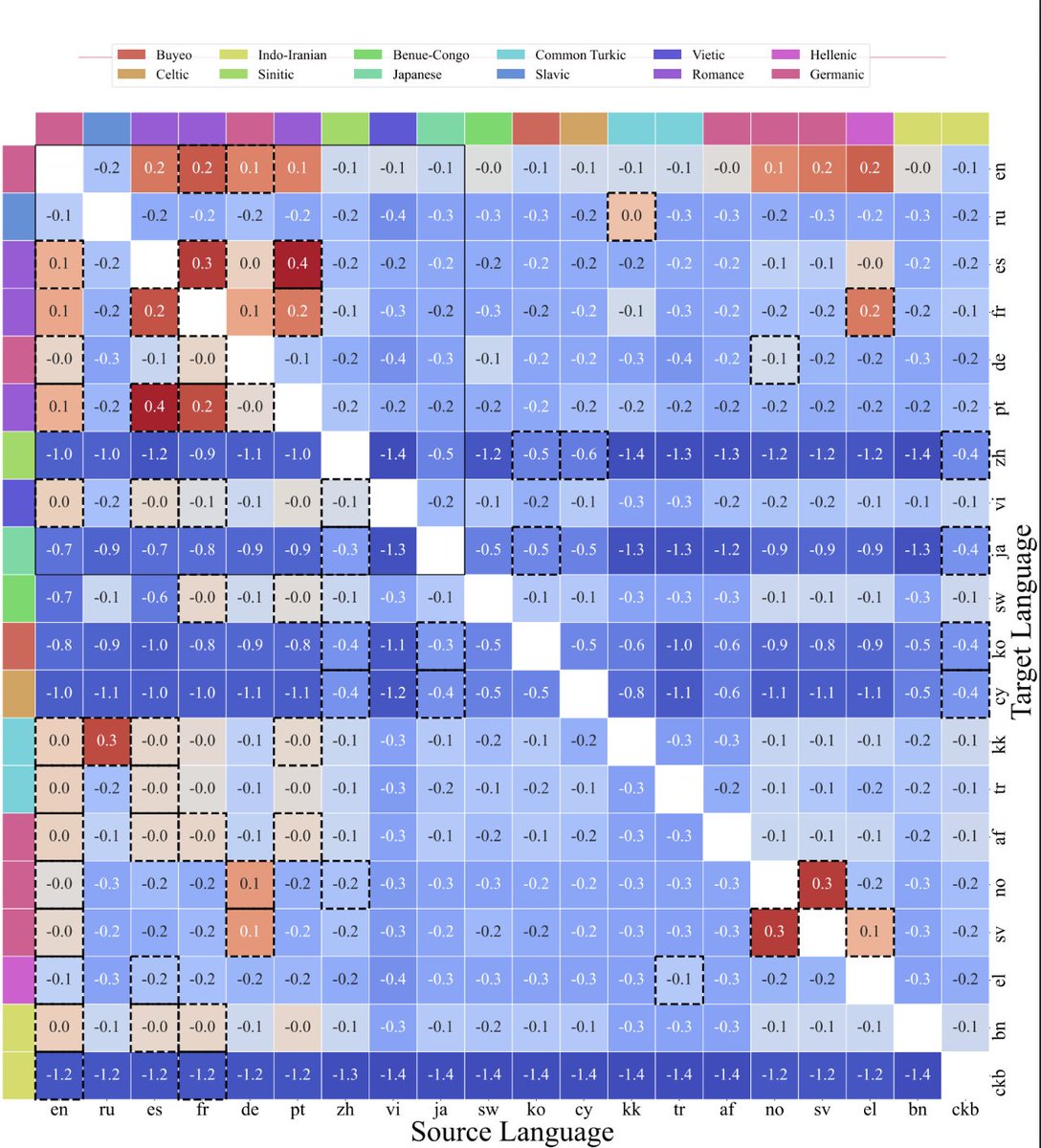
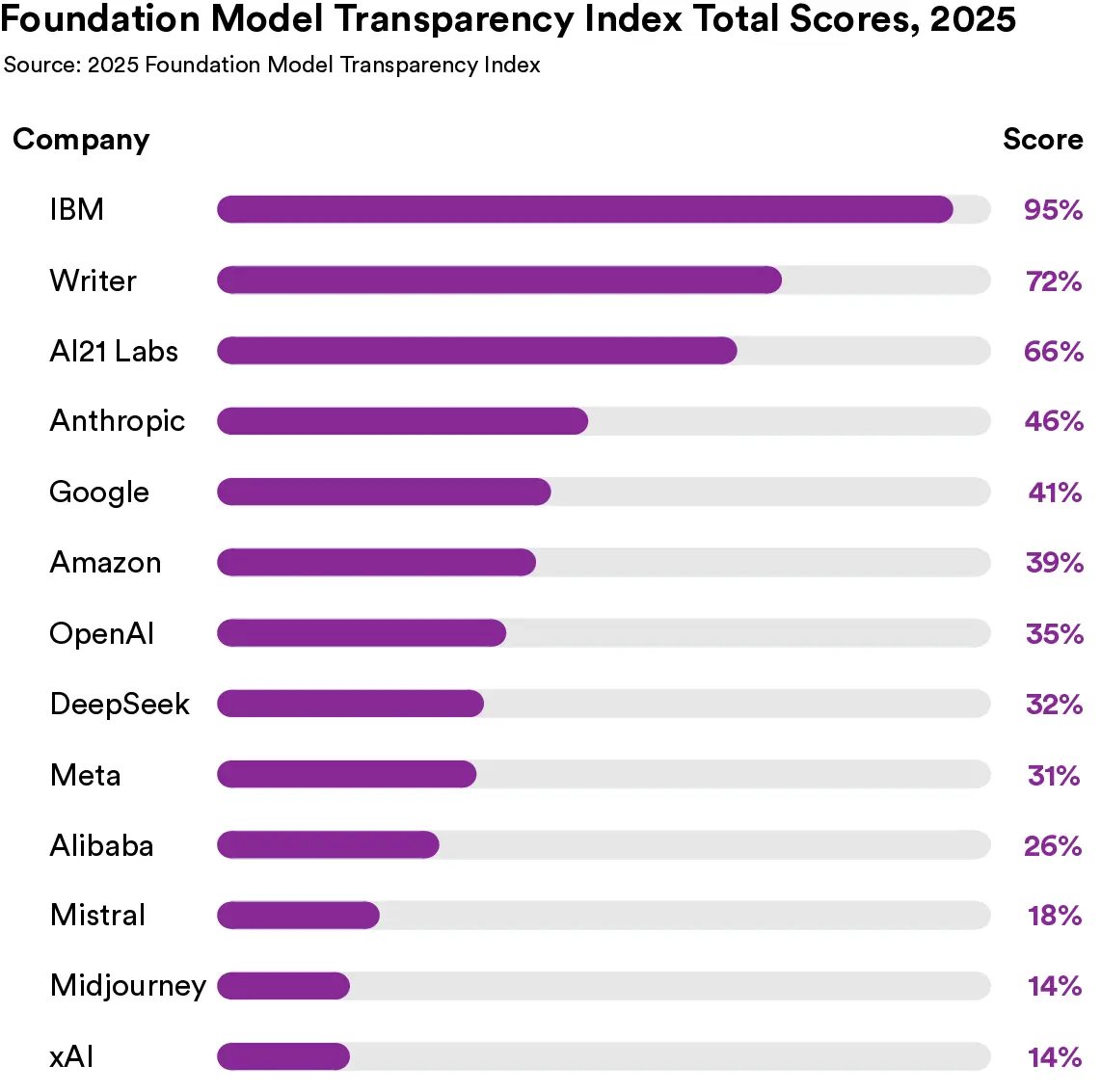
Angehefteter Tweet

Who is winning the open AI race?
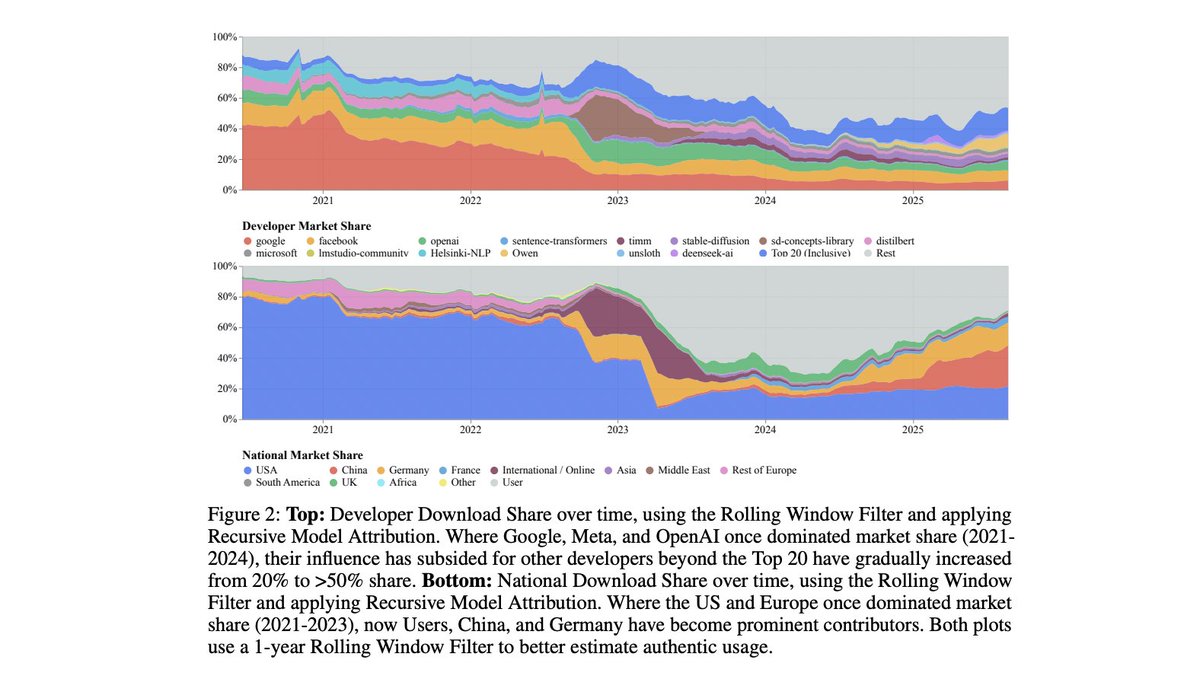
Our new study "Economies of Open Intelligence" maps 2.2B @huggingface downloads across 851k models (2020→2025).
1) Power is rebalancing (US big tech ↓; China + community ↑)
2) Models got big & efficient (MoE, quant, multimodal surge)
3) Intermediaries now matter (adapters/quantizers steer usage)
4) Transparency is slipping
/🧵

English