
Simon Smith
5.8K posts

Simon Smith
@_simonsmith
EVP Generative AI @klickhealth
Beigetreten Ağustos 2023
750 Folgt3.4K Follower

Another one for projects: Allow me to save conversations in a project to sources, which I can do in my personal account, but not yet in my Enterprise account.
English
With OpenAI prioritizing enterprise, here's my wishlist as someone helping to oversee ChatGPT Enterprise deployment in a 1,600-person company:
1. Close biggest gaps with Claude
- Improve design, especially frontend and presentations
- Decrease verbosity and excessive response formatting
- Add Cowork competitor
- Improve UI around thinking summaries and document previewing (Claude's artifact pane is excellent)
- Make it easier for people to steer the personality to something more Claude-like if they want it, without adding Claude's sycophancy; for example: give people a wizard to interact with ChatGPT until they're happy with its responses, then save that as custom instructions
2. Improve project functionality
- Add source document syncing like in personal accounts
- Add project archiving
- Add project searching
- Add manual way to decide what projects go in the sidebar, as in Claude with starred projects
- Make it easy for people to generate presentations, audio overviews, video overviews, reports, and similar outputs from project content and conversations in a way that prevents users from having to create separate ChatGPT and NotebookLM projects with the same content
3. Lean into record mode more
- Add record mode to Windows desktop app
- Automatically suggest activating recording for video conference meetings
- Make full transcripts easily available and exportable
- Improve speaker identification (especially for the person whose computer record mode is running on; that should be easy, since the input to their mic is usually them)
- Make it easy to recover from an accidentally disrupted transcription
- Make it easy to take action on a recording, like sending a contact report, or creating a requirements document, or creating a statement of work
- Stop treating record mode as a low priority because it's a differentiator right now and very useful!
4. Facilitate easier skill creation and management
- Recognize that skills can substantially expand ChatGPT's utility within an organization and helping companies leverage them should therefore be a huge priority
- Identifying and prioritizing skills to create, organizing skills, versioning skills, and everything else related to creating and managing a skills library will have huge value to companies and should get a lot of attention accordingly
5. Make it easier to deploy and manage agents
- The vision for Frontier is awesome, and very much aligned with how we're thinking about the agentic future; now we need it realized and made available!
- Make it easy for individuals to create and deploy their own personal agents and automations that are RELIABLE, including at complex multi-step tasks
- Make it easy for organizations to create and deploy agents that function effectively like employees
- Make it easy for companies to set up some kind of agent management system so people can be assigned responsibility for overseeing different agents and their continuous improvement
6. Reduce distractions
- Let people configure their left navigation
- Focus on making ChatGPT the easiest tool for people to use to harness the most power from AI, whereas the current "+" menu has so many options it's totally confusing what people should be using when
- Deprioritize all the experiments that make ChatGPT seem totally unfocused relative to competitors; hone in on high-value business use cases and let the consumer market benefit from what's built for businesses, rather than vice-versa
7. Improve media generation for businesses
- Let ChatGPT Enterprise customers use Sora, ideally integrated into ChatGPT, with more business-oriented features
- Improve image generation options such as adding more aspect ratios in ways that make image generation more useful for businesses
Those are the things that come to mind right now. I'm sure there are others and hope that people add comments to this post that help OpenAI shape ChatGPT into an even better product for businesses.
English
Very preliminary data on ChatGPT ads shows that for this limited set of advertisers, chatbot lead quality beats social display but not paid search, but is currently more cost-effective than both.
HOWEVER, cost is a function of demand, so "cheaper" to me right now is meaningless. OpenAI set largely arbitrary prices, while the other channels set prices based directly on demand.
Also, the fact that lead quality was worse for chatbot ads than paid search ads is a red flag. Chatbot-based clicks are supposed to have high intent. Here it looks like they may have higher intent than display ads, but lower intent than paid search ads.
This is all very preliminary, though, and it's not clear what properties were included in these buckets for the comparisons, such as whether they refer only to Google paid search ads or broader Google ad channels.
English
The only ChatGPT app I consistently (though still rarely) use apart from data integration apps is Apple Music to make playlists. But Atlas is my main browser, so I use EVERY website and web app now inside Atlas.
Frequent use cases include researching claims of an X post, asking questions about an arXiv paper, searching the web for product reviews before a purchase without leaving the product page, giving me feedback on something I've written before posting it, and making light edits directly in apps like Google Sheets.
I see people saying OpenAI will abandon Atlas as it prioritizes enterprise business, but I don't think that's going to happen, because Atlas is very useful for giving every employee an AI assistant on every website and web app a company uses.
English
Why is there simultaneously a big shift to using agents and a big shift to writing articles on X, versus in Markdown files in public repos published via static site generators? Feels like a contradiction to publish in such a walled garden as X.
English
Dispatch looks cool, but my issue right now is that I have Claude Desktop logged in with my work account, and Claude on iOS logged in with my personal account. Unless I'm willing to regularly change logins, or get a separate Mac or iPhone, I can't take advantage of this.
Felix Rieseberg@felixrieseberg
We're shipping a new feature in Claude Cowork as a research preview that I'm excited about: Dispatch! One persistent conversation with Claude that runs on your computer. Message it from your phone. Come back to finished work. To try it out, download Claude Desktop, then pair your phone.
English
I don't post on Substack much, but I do have a Substack with several articles. I also have an old GitHub-hosted Jekyll site. Now I'm thinking of ditching the former and reinvesting in the latter. Way easier for agents to consume and help me maintain the content.
Why won't everyone on Substack do this? Network effects? My networks are way, way bigger in other channels, but maybe for some people it's the reverse. Monetization? Maybe, but what happens when agents are the majority of web users?
English
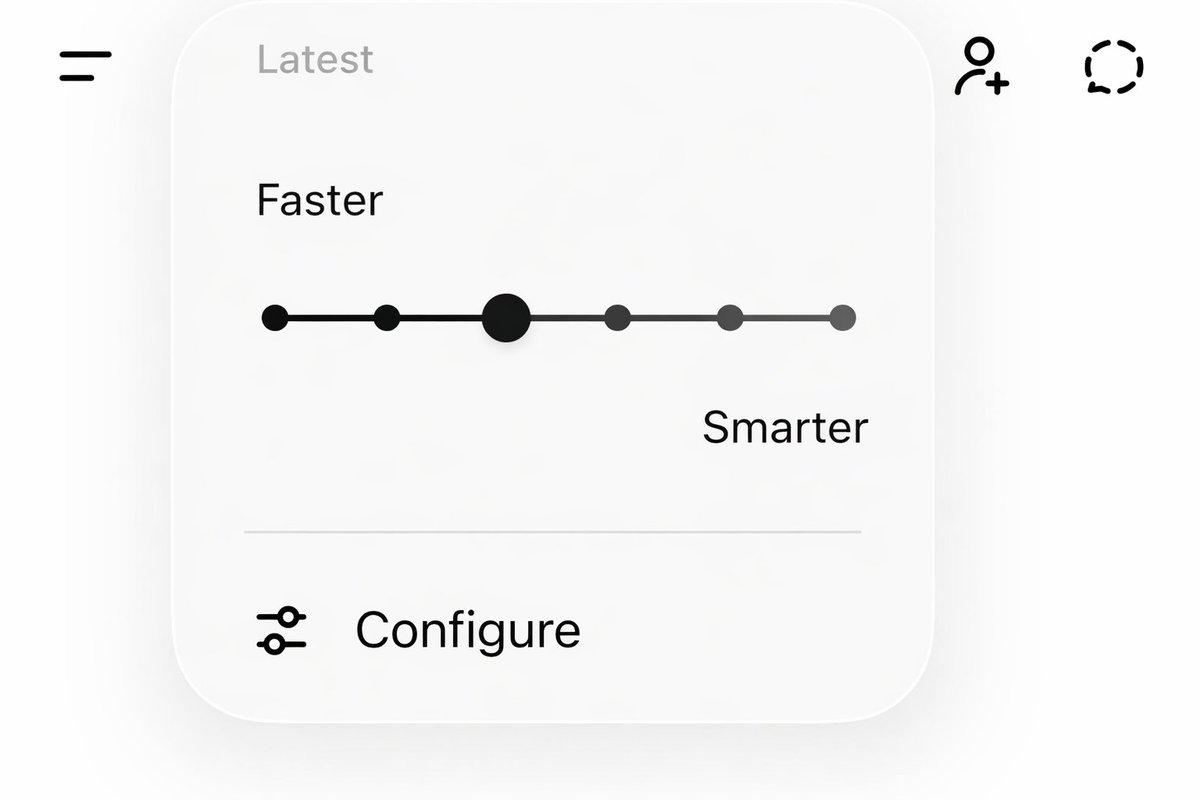

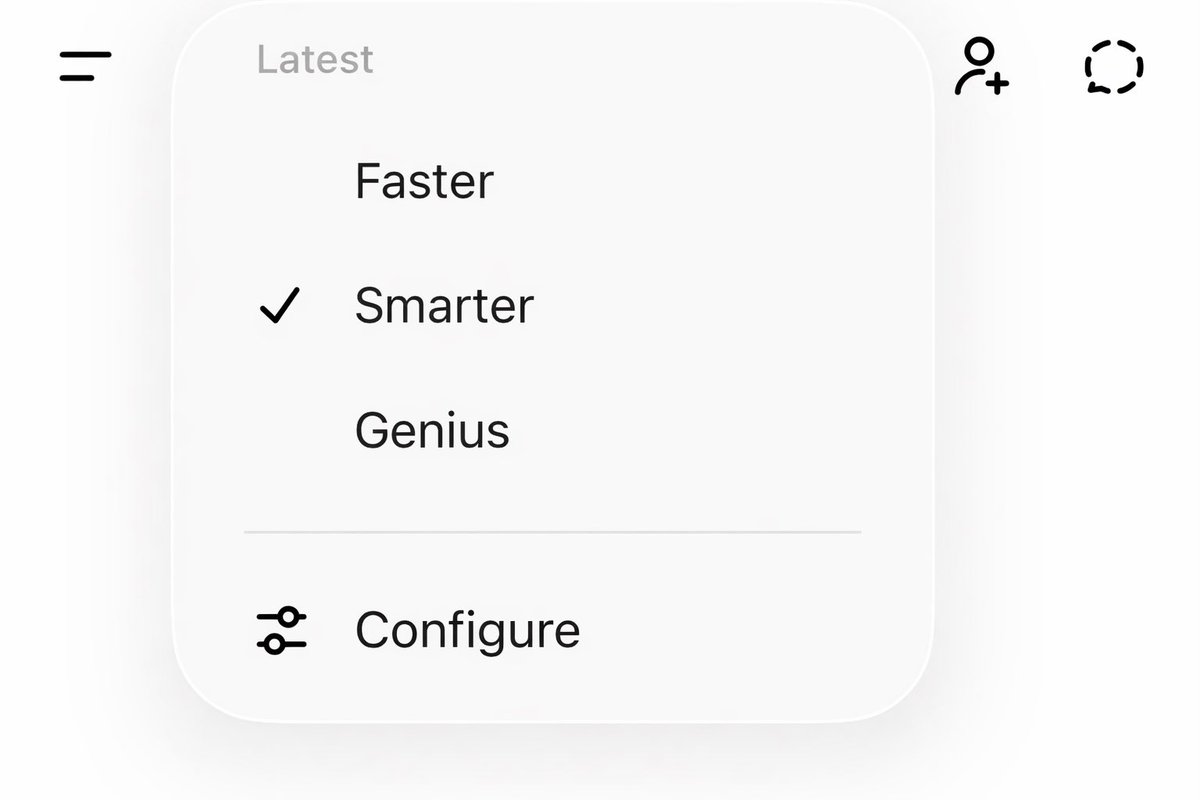
@_simonsmith still not working - who would ever pick smarter over genius?
English
We finally got the model simplification promised with the release of GPT-5. It’s very intuitive. However, I propose that OpenAI simplify the naming further: Faster, Smarter, Genius. Because Instant isn’t, all the models Think, and “Pro” is confusing due to Gemini naming and the implication that the other models aren’t for professional use.
English
This isn't released for me in ChatGPT, but Suvansh is from OpenAI. I would love to see this simplification and the ability to configure model choices. Would love granular configuration too. Like: Thinking model for Atlas sidebar, but Instant model for Atlas searches.
Suvansh Sanjeev@SuvanshSanjeev
it has long been said that model naming is AGI-complete at long last
English
Third AI business builder I'm tracking. So far, we have @polsia, @intelligenceco's Cofounder, and now Durable. Am I missing any? Vending-Bench 2 scores are on track for human-level business performance within a year. There's a battle to be the Claude Code of entrepreneurship.
James Clift@jamesclift
Introducing Durable. The first AI business builder that replaces your 9-5 income. RT + comment “Durable” and we'll build your business for FREE.
English
More thoughts about OpenAI’s enterprise pivot: Does it mean the ad tests so far haven’t been great, that revenue there looks less promising? Does it mean lower priority for consumer hardware, or a pivot to make hardware more business focused?
English
@signulll Disagree on Atlas. Very useful for us as a ChatGPT Enterprise company to deploy a single tool that lets people use AI across every single web app we license. Claude's Chrome extension is good for agentic tasks and debugging, but not as seamless an experience as Atlas.
English

let's simulate what sama & mark chen are going through for the next few weeks on what to prioritize & what to chop shall we? this will be the walmart version of it lmao.
openai has 29 "products" in the portfolio.
- chatgpt
- chatgpt search
- deep research
- chatgpt agent
- chatgpt atlas
- chatgpt pulse
- sora
- codex
- image generation / images
- voice in chatgpt
- projects
- canvas
- tasks
- shopping research / commerce in chatgpt
- gpt store / gpts / apps
- chatgpt business
- chatgpt enterprise / team / edu packaging
- atlas for enterprise
- oit's vepenai api platform
- responses api
- realtime api
- agents / agentkit
- agents sdk
- web search api/tooling
- image generation api
- codex cloud / developer codex surfaces
- computer-using agent (platform/model layer)
- operator (legacy/transitioning standalone identity)
- let's say 4 hardware devices jony ive's team is working on (this probably does not get killed)
now obviously most of these fit into the enterprise & coding territory. so what do you keep vs kill?
most likely to be killed / deprioritized:
atlas
pulse
gpt store (at least put in sunset)
shopping & commerce
sora (as a “hero product”)
merge & consolidate everything else into chatgpt app.
intense focus:
codex
agents
enterprise workflows
English
This is great to hear, actually. ChatGPT Enterprise has many weaknesses right now that leave an opening for competitors. Among them:
- GPT-5.4 is a big improvement, but is still too verbose, terrible at design, and not as personable as Claude Opus 4.6. Custom instructions can help, but most users don't spend time tweaking their custom instructions, so they just think it's worse than Claude and prefer the latter.
- Design is a big one, so I'll note it again. Claude is so much better at all forms of design, be it charts, reports, PowerPoint presentations, or website front ends. This pulls a lot of people into Claude and then they find it more personable and enjoyable to use and don't want to leave.
- The Codex app is fantastic, but Claude Cowork meets a need amongst non-coders for powerful desktop agentic coding. Users don't have to worry about things like dependencies, they just get added into the virtual machine magically. Once people start using Cowork, they find it hard to go back to ChatGPT Desktop.
- You can't use Sora in ChatGPT Enterprise, and the image generator in ChatGPT has fewer aspect ratio options than Nano Banana in Gemini. So, two things that should give ChatGPT an advantage over Claude end up being less compelling. If you're a company like us that has both Google Workspace and ChatGPT Enterprise, the ability to use video and have more options for image aspect ratios in Gemini pulls you to Google's orbit.
- NotebookLM takes a lot of people out of ChatGPT when they want to summarize lots of information into digestible outputs like presentations and podcasts. OpenAI could build the ability to generate these kind of artifacts from projects, which would already have lots of the documents we upload into NotebookLM separately. This seems like a missed opportunity.
- Projects are lacking some key features. For one thing, when you have a lot of projects, it's hard to sort through them in the left sidebar. You should be able to star projects and archive projects like you can in Claude. The document syncing that's now in ChatGPT personal accounts should come to Enterprise. We need a page to go to see all our projects and sort through them.
- GPT-5.3 Instant is a relatively weak model, and if people don't know to switch to GPT-5.4 Thinking, they often just think ChatGPT is dumb, and then are impressed when they try a new model launched with fanfare like a Gemini 3.1 Pro or whatever.
- It's great to have skills in ChatGPT Enterprise now, but unlike Claude, we can't point ChatGPT at a plugins marketplace and suck up plugins and skills from a GitHub repository. This makes it hard to manage skills centrally and version control them across the organization.
- The artifacts pane that Claude uses to preview stuff is great, much better than what's in ChatGPT currently. That may be a personal bias, but I think people like seeing output on the right, and interacting with a model on the left.
- Record mode on the ChatGPT desktop app is such a useful thing to have for businesses, yet it hasn't seemed to get much investment since it launched. For example, it would be great to have ChatGPT suggest triggering record mode when you start a meeting in Zoom or whatever.
Those are some of my thoughts, but not an exhaustive list.
Andrew Curran@AndrewCurran_
The WSJ is reporting that OpenAI is about to take a hard turn into enterprise.
English
@emollick Agents can manage other agents via code. I don't think they're ignoring managers. It's just that in future, most managers will be AI agents managing other AI agents, and they are working on that.
English

I get why AI labs are so focused on software development (it helps them get recursive improvement, and also they are coders so they think coding is the most vital thing), but there are 9.5x more managers than there are coders & efforts to build tools for them are very nascent.
English
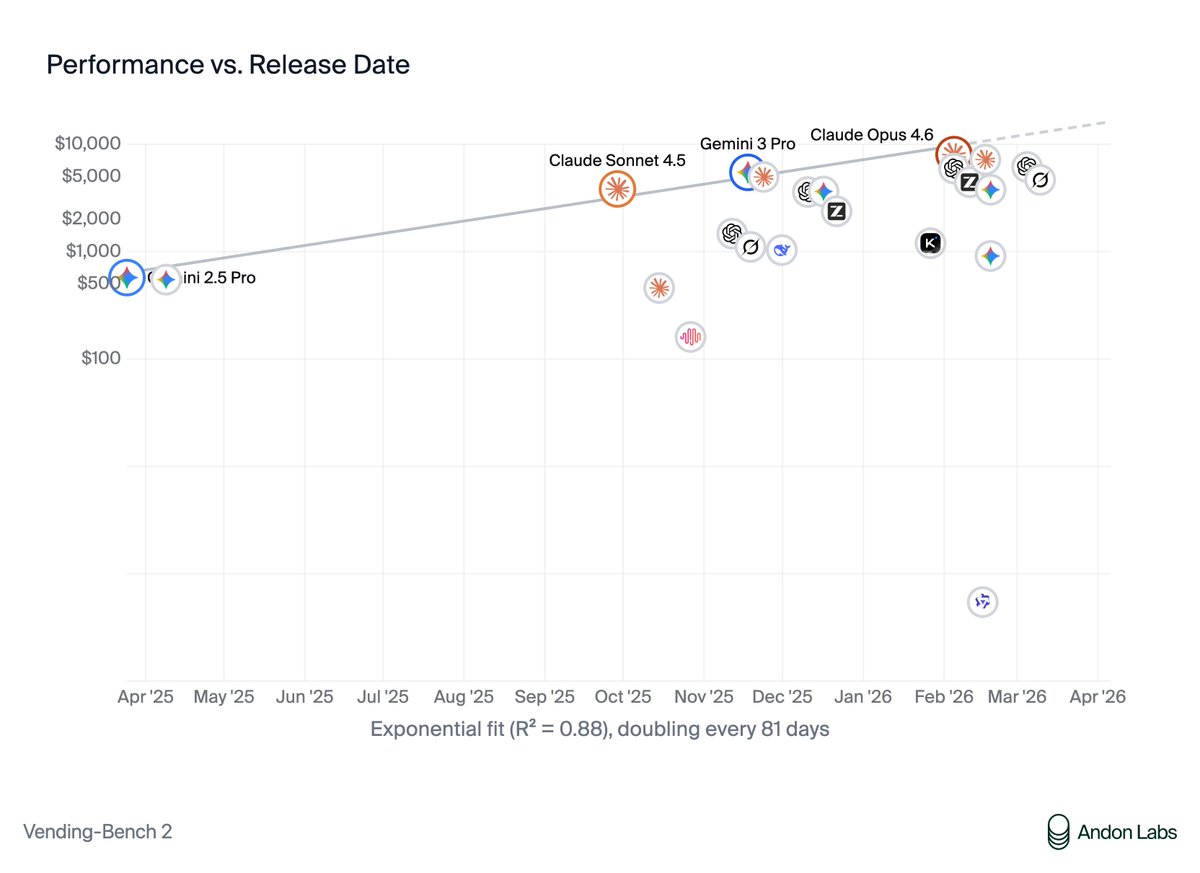
Prediction: Within a year, 90% of new businesses will be started by AI. We're in a similar place for entrepreneurship as software engineering a year ago, the "vibe entrepreneurship" era. And we're progressing fast.
Anecdotally, you can see this now in the rise of vibe entrepreneurship platforms like @polsia and @intelligenceco's Cofounder, as well as agent orchestration platforms built in the shadow of OpenClaw.
Quantitatively, you can see it in the doubling rate of @andonlabs' Vending-Bench 2. The top earnings double every 81 days. The best model is now about 3 doublings away from a good human score. That's roughly 8 months.
This doesn't mean AI will be able to start every company, just like it can't write every piece of software. And it won't be able to do every function within a company as well as a human.
But it will be better than the average human at starting and running a typical business that doesn't require excessively specialized knowledge.
We should watch Vending-Bench 2 closely. It could become the METR time horizon for AI entrepreneurship.
Though the best benchmark may simply be the models' actual financial performance in the real world.
English
@petergostev This is great! Can you also do a filtered view showing the same results but for only head-to-heads amongst top-10 models at each point in time? I imagine the one you shared actually underestimates AI capabilities because it includes head-to-heads of poorly scoring models.
English

Arena gives an option for users to vote 'both bad' against the two responses that users get, this combined with the longest running benchmark in the industry, we get this lovely unique view of the model capabilities getting better through time
Arena.ai@arena
How often are users unhappy with the answers that top AI models give? This can give us a real world view of how the frontier shifts throughout time. We have looked back to 2023 and traced back how often users rated both responses in Battle Mode to be bad (limited to Top 25 modes at any given time). We see three eras: - Pre-reasoning: Responses were rated as ‘both bad’ >15% of the time and the trend was not reducing - Early reasoning: Models like o1-preview started to noticeably shift the performance, reducing the rate to ~10% - Advanced reasoning: Continued reduction in the % of ‘both bad’ rankings with increasingly advanced models The metric is not close to saturation, meaning that even among models in the Top 25, there are still ~9% of responses that users rate as ‘both bad’ and the models are not meeting expectations of users in terms of quality.
English
Number of "both bad" outputs for AI models has consistently declined on Arena. But I imagine this underestimates improvement and it would look even better if filtered to only head-to-heads amongst, say, top-10 models over time. Anyone at Arena want to try that filtered view?
Arena.ai@arena
How often are users unhappy with the answers that top AI models give? This can give us a real world view of how the frontier shifts throughout time. We have looked back to 2023 and traced back how often users rated both responses in Battle Mode to be bad (limited to Top 25 modes at any given time). We see three eras: - Pre-reasoning: Responses were rated as ‘both bad’ >15% of the time and the trend was not reducing - Early reasoning: Models like o1-preview started to noticeably shift the performance, reducing the rate to ~10% - Advanced reasoning: Continued reduction in the % of ‘both bad’ rankings with increasingly advanced models The metric is not close to saturation, meaning that even among models in the Top 25, there are still ~9% of responses that users rate as ‘both bad’ and the models are not meeting expectations of users in terms of quality.
English