Benchmark retweetet
Benchmark
10.9K posts


Benchmark
@benchmark
Benchmark focuses on early-stage venture investing in consumer, marketplaces, open-source, AI, infrastructure, and enterprise software.
Beigetreten Haziran 2009
491 Folgt97.2K Follower

Benchmark retweetet

With the IBM’s $11B acquisition of Confluent officially closing, I want to say congrats to the entire team for navigating the tricky course
from open source Kafka support
to open core
to single-tenant cloud
to multi-tenant cloud
and all the ensuing GTM changes along the way
and 5 (chaotic) years as a public co.
The company relentlessly built >$1B business (actual revenue not last wk x 52 :-)) under the incredible leadership of @jaykreps and fantastic execution from the team.
On a personal note I've been lucky enough to serve on the board from Day 1 to Day End through our investment @benchmark. It was my first investment and I learned so much along the way.
Thank you to Jay, @nehanarkhede and @junrao for choosing to work with us in 2014 and the adventure along the way!
Rob Thomas@robdthomas
Agents need real-time data…
English
Benchmark retweetet
By approaching the problem differently, this small team continues to push towards real deployments at an astounding rate.
I've had the great fortune of working with @coatue_thomas on a number of companies, most notably an early bet he made on Cerebras. Huge get for all.
Tony Zhao@tonyzzhao
We raised $165M at a $1.15B valuation to stop doing demos. 2026 is about 1) deployment and 2) research. We will start shipping Memo with our new frontier models in a few months. Our series-B is led by Coatue, with Thomas Laffont joining the board. ->🧵
English
Benchmark retweetet
Breaking up prefill (processing the prompt) and decode (generating the response) has been theorized for a while as they have different compute requirements.
Now we have the silicon to do it - AWS Trainium for prefill, and Cerebras for decode.
Super fast AND cost effective.
Amazon Web Services@awscloud
We're teaming up with @cerebras to build the fastest possible inference. Coming soon to Amazon Bedrock, we’re delivering inference performance an order of magnitude faster than what’s available today by connecting AWS Trainium3 for compute-intensive prefill with Cerebras CS-3 to power decode. Learn more about the partnership. go.aws/3Pzcota
English
Benchmark retweetet

New episode of Uncapped with @MaxJunestrand from Legora and my partner @chetanp.
Every time I'm with Max I come away thinking "this is what it takes to build an AI native software company."
He's one of my favorite founders, hope you enjoy.
(0:00) Intro
(0:31) Legora's origin story
(9:05) Building an AI-native company
(18:16) No sacred cows, the models will be amazing
(27:36) Winning pilots and global expansion
(36:43) Starting in Europe
(47:15) Stockholm culture and "blodsmak"
English
Benchmark retweetet

AI can only fulfill its potential in the enterprise if every employee is given the tools to become AI-native. We believe Gumloop is platform to make the vision of the AI-native enterprise a reality and are thrilled to lead the Series B!
Max Brodeur-Urbas@MaxBrodeurUrbas
gumloop raised a $50m series b led by benchmark here's a video we had fun making about the journey back to work.
English
Benchmark retweetet

gumloop raised a $50m series b led by benchmark
here's a video we had fun making about the journey
back to work.
English
Benchmark retweetet

From Benchmark leading their seed round less than 2 years ago to a $5.5b valuation, Max and the entire Legora team have been focused on delivering the best AI products to lawyers around the world. Remarkable velocity, incredible progress, and huge things ahead!
Legora@WeAreLegora
$550M Series D led by @Accel. $5.55B valuation. One year into our U.S. expansion, we’re doubling down: accelerating across America and building AI with the lawyers who use it every day. Grateful to our customers, partners, and team. More: legora.com/blog/series-d
English
Benchmark retweetet
Max and the team at Legora are exceptional, so happy about all their well deserved success.
Building an application layer AI company at this scale and speed is insanely hard given how quickly AI is changing. They’re doing it the right way and I couldn’t be more bullish on them.
etn.@etnshow
BREAKING: Swedish start-up @WeAreLegora has raised a $550M Series D funding round at a $5.55B valuation to fuel US growth. CEO & Co-Founder @MaxJunestrand says: “Over the past year, the pace of adoption in the U.S. has exceeded our expectations, as leading firms and in-house teams move decisively from experimentation to embedding AI across their organisations". The round was led by @Accel with participation from existing investors @benchmark, @BessemerVP, @generalcatalyst, @ICONIQCapital, @Redpoint, and @ycombinator.
English
Benchmark retweetet
Turner and I covered a wide range of topics including the history of software and why the AI application vs SaaS shift mirrors the SaaS vs On-Prem disruption. Plus: investing in AI applications, the dynamics in the AI application market, and more. Hope you will listen!
Turner Novak 🍌🧢@TurnerNovak
New @ThePeelPod with @chetanp We talk Manus, the history + future of software, why incumbents should make big AI acquisitions, why investors are begging for AI companies to go public, and inside @Benchmark’s latest investing strategy. Thanks @Numeral and @FlexSuperApp for sponsoring this episode. 0:08 Inside the $2.5B Manus acquisition 6:24 Manus' three main use cases 11:08 Taking heat on Twitter 15:10 Starting to tweet about software in 2018 22:50 The history of application software 29:15 Benchmark’s 25x Fund 7 31:33 How incumbents got too dominant by 2020 31:48 Going all-in on AI software in 2022 39:31 Why Benchmark didn’t invest in the AI labs 40:48 How cloud companies beat on-prem incumbents 44:33 Why AI companies will beat legacy cloud incumbents 50:04 SaaS companies should make big AI acquisitions 57:35 Why incumbents have not bought more AI companies 1:04:43 Public markets are starving for AI companies 1:10:14 Inside Benchmark’s fund strategy 1:14:14 Benchmark’s history of non-traditional VC rounds 1:17:56 Is the 20% ownership model outdated? 1:19:20 Chetan’s rebirth as a consumer investor 1:22:39 What Benchmark looks for in founders 1:25:01 AI coding and AI software gross margins
English
Benchmark retweetet

Today we’re releasing Greptile Agent v4, our best code review agent yet.
It’s catches more tricky bugs than v3, while also having far fewer false positives.
We're also updating our pricing to help us support power users.
English
Benchmark retweetet

🔥 Hear Harrison's hot takes in this latest podcast with VentureBeat 🔥
- LangChain's origin story: from `langchain` to agent engineering platform serving half of the Fortune 10
- Why OpenClaw works where AutoGPT failed
- LangChain Deep Agents unpacked: planning, subagents, file systems, prompting
- Skills vs. tools vs. subagents
- Context engineering: what the LLM sees vs what developers see
- File systems for context management vs. AutoGPT's approach
YouTube ➡️ youtube.com/watch?v=53gPwk…
Spotify ➡️ open.spotify.com/show/4Zti73yb4…

YouTube

English
Benchmark retweetet

It's becoming clear that every software company needs to become an agent company. That’s because software is just a sequence of decisions based on user inputs, and good decisions require the flexibility of intelligence.
Even if your product needs high performance / high reliability, you will eventually use agents and should prepare for that. When agents get 10x faster/more reliable, are you still not going to integrate? What about 100x?
We knew agents would one day be embedded in our search algorithm. A year ago agents were slow and stupid. But the trend was clear. Today we announced Exa Deep → search redesigned to use agents + our instant search, which makes it extremely high quality while minimizing latency.
Again the trend is clear - we know agents will continue advancing in accuracy/speed. And so the percentage of products that want this agentic endpoint will increase. This is probably true for your software company as well.
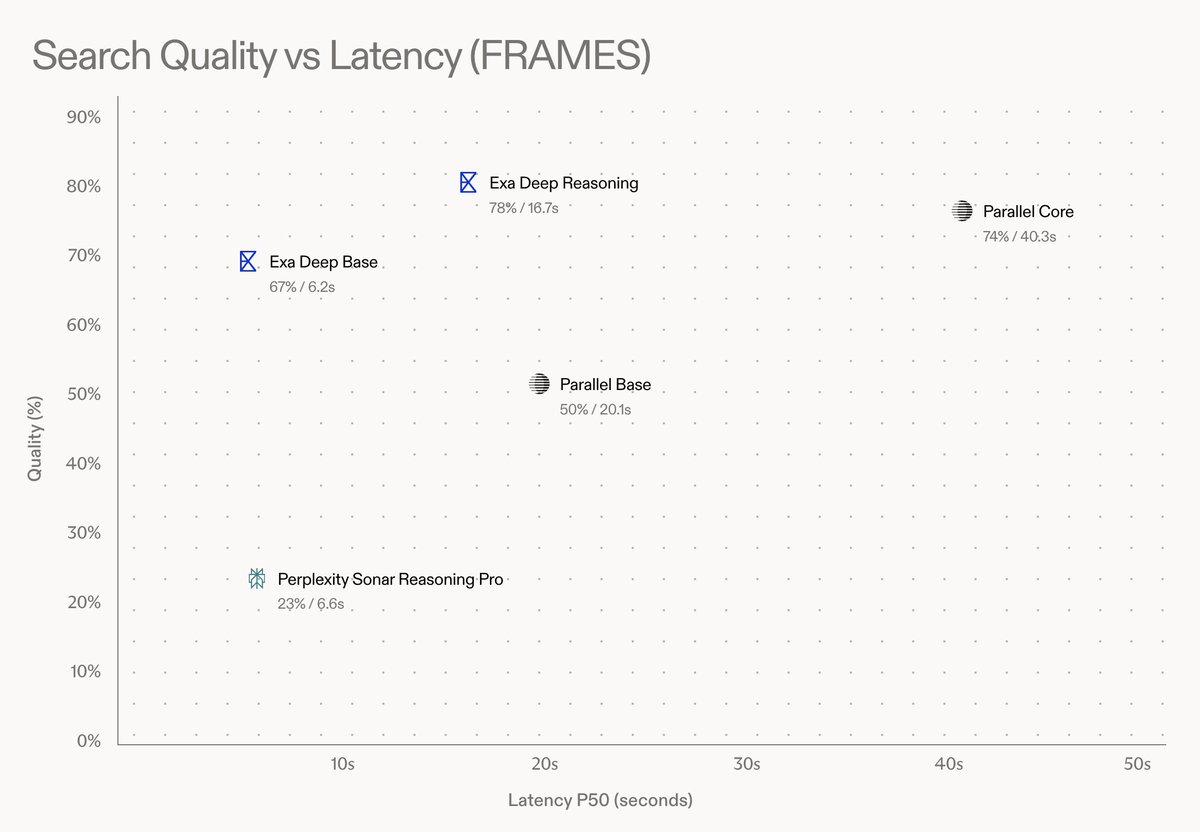

Exa@ExaAILabs
Introducing Exa Deep: putting an agent inside every search For each query, an agent runs in a loop until it gathers all information, then returns structured output. Evals show Deep is Pareto optimal at 4-60s latency, ideal for quick, cost-efficient research!
English
Benchmark retweetet

Benchmark retweetet

Thank you @johncoogan and @jordihays for having me on @tbpn last week!
It was exciting to share some of the things we've been working on.
Applied Compute@appliedcompute
"Everyone's talking about continual learning. That's entirely where this space is going to go." The Applied Compute platform is architected around that premise: build memory and intuition from fragmented data across your entire org, train reasoning models directly on top of it, and close the loop. A model is just one piece. An agent is where it runs, what tools it has, how permissions and auth are handled, how humans guide and instruct it, and the observability around it all. Every interaction should be treated as a training signal so the system can compound over time. Thanks for having us @tbpn
English
Benchmark retweetet

People don't realize the length the fomo team goes to provide the best experience for our traders/users
Don't take my word for it, see us continually showing up and we will continue to earn your trust with time
We are leveling up a ton of our systems including VIP/customer support, fraud detection, and trading execution
Bull market, bear market, any market we will be here and continue to build the best trading platform ever seen
English
Benchmark retweetet

The G2 Best Software Awards mean a lot to us because they’re based directly on customer reviews. In the 2026 Awards, DeepL is ranked in the top-6 German software tools, the top-50 EMEA software tools and the top-32 tools for managing content worldwide.
Thank you to everyone who takes the time to share their experience of DeepL!
#G2BestSoftwareAwards #BestContentTools #BestTranslationSoftware
English
Benchmark retweetet

In 2025, $17B+ in crypto was stolen by scammers. AI‑enabled scams pulled in 4.5× more revenue per operation.
If bad actors are using AI, defenders should too.
We’re proud to expand our relationship with OKX as they adopt Chainalysis Alterya to stop fraud before it happens.
Read more here: chainalysis.com/blog/okx-adopt…

English
Benchmark retweetet

Traditional PSP models haven’t kept up with how money moves. That’s why we built Payments, an integrated PSP for fiat and stablecoins.
For too long, teams have stitched together multiple vendors just to operate across converging rails, shifting regulations, and rising user expectations.
Modern teams need one API that lets them:
- Move money across ACH, Wire, RTP, FedNow, Push-to-Card, and stablecoins
- Launch payment products in days, not weeks, with compliance, accounts, and ledgering built in
- Keep shipping product without re-integrating every time a new rail emerges
That one API is Payments.
See how we make building money movement products easier than ever below, then dive deeper into Payments here: go.moderntreasury.com/40uy8sn
English
Benchmark retweetet

A tool-calling model with access to just a filesystem can also learn how to perform non-technical tasks (in this case, legal tasks) outside of software engineering. With a well-crafted grader that nudges the model in the right direction, a model can cleanly learn how to pick up new skills, from how to use the PDF parsing tools effectively to navigating legal documents, really drawing out latent capabilities learned from pretraining.
It's been great working with @mercor_ai on a state-of-the-art legal model! A big part of our recipe is high quality environments to train on.
Applied Compute@appliedcompute
We partnered with @mercor_ai to post-train custom models on high-quality expert data from fields like law, investment banking, and consulting. Our latest model ranks #1 on the APEX-Agents leaderboard in corporate law and #4 overall. Domain-specific post-training on high-quality, organization-specific data can systematically close the gap between general AI competence and expert-level reliability, making capable enterprise agents practical and affordable for knowledge-intensive industries. appliedcompute.com/case-studies/m…
English