Angehefteter Tweet

Insane. We got close to Opus 4.5 at home >70 tokens/s
cyysky@cyysky
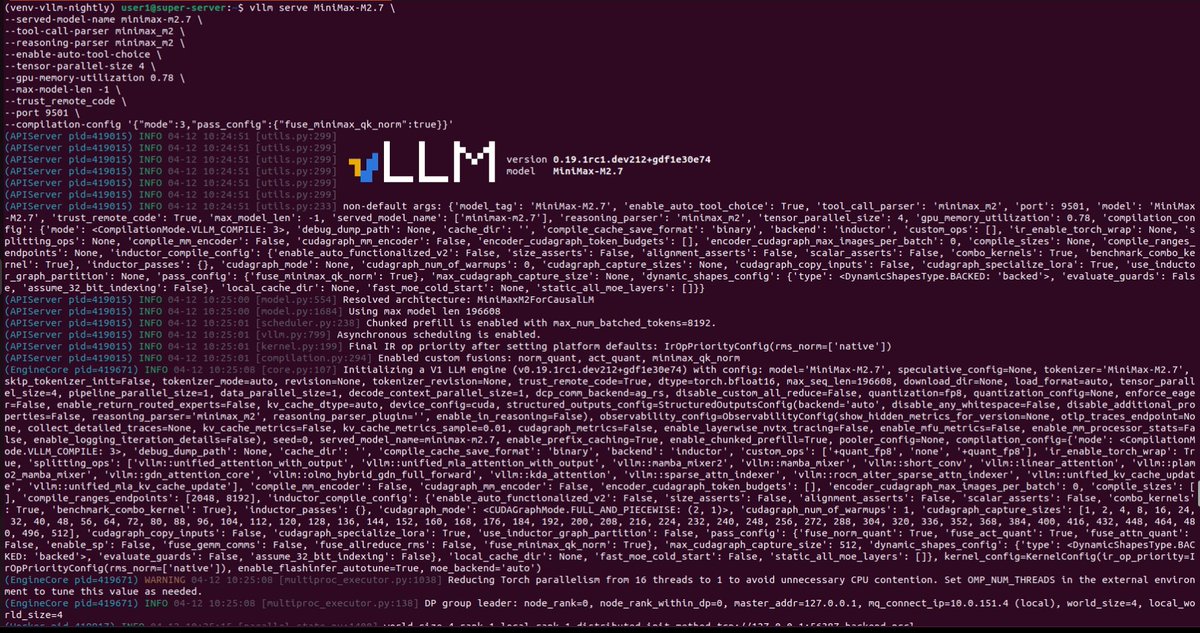
@cedric_chee MiniMax 2.5 full precision FP8 running LOCALLY on vLLM x 8x Pro 6000 🔥 Hosting it is easier then I thought, it just reuse the same script for M2.1. Time to do the vibe coding test! Generation: 70 tokens-per-sec and 122 tokens-per-sec for two conneciton Peak Memory: 728GB
English