
N 🟩
791 posts


check out the latest amazing work by @fede_intern and @diego_aligned.
they have found a way to make verifiable ai affordable and usable with open source models.
of course already with a paper and code for anyone to review.
i'm incredibly lucky to be able to work with this crazy and brilliant people.
and there is more to come!
Fede’s intern 🥊@fede_intern
LLMs now make critical decisions in hospitals, defense, banks, and governments. Yet nobody can verify which model actually ran, or whether the output was tampered with. A provider or middleman can swap weights, silently requantize the model, alter decoding, inject hidden prompts, do supply chain attacks, or change the deployment surface without the user knowing. This problem is already serious. It will become critical. We think this needs a practical solution, not just a theoretically clean one. CommitLLM is designed to be deployable on existing serving stacks now: the provider keeps the normal GPU serving path, does not need a proving circuit, does not need a kernel rewrite, and does not generate a heavy proof for every response. In practice, two families of approaches dominated the conversation before this work: fingerprinting, which can be gamed, and proof-based systems, which are theoretically strong but too expensive for production inference. We built CommitLLM to target the middle ground. The core idea is to keep the verification discipline of proof systems, but specialize it to open weight LLM inference. The cryptographic core is simple: Freivalds style randomized checks for the large linear layers, plus Merkle commitments for the traced execution. Then a lot of engineering work is needed to make that line up with real GPU inference. The key trick is this. A provider claims `z = W × x` for a massive weight matrix. Normally you would verify that by redoing the multiply. Instead, the verifier samples a secret random vector `r`, precomputes `v = rᵀ × W`, and later checks whether `v · x = rᵀ · z`. Two dot products instead of a full matrix multiply. In the current implementation, a wrong result passes with probability at most `1 / (2^32 - 5)` per check. A full matrix multiply, audited with two dot products. Most of the transformer can then be checked exactly or canonically from committed openings. Nonlinear operations such as activations and layer norms are canonically re executed by the CPU verifier. The one honest caveat is attention: native FP16/BF16 attention is not bit reproducible across hardware. CommitLLM verifies the shell around attention exactly, then independently replays attention and checks that the committed post attention output stays within a measured INT8 corridor. So attention is bounded and audited, not proved exactly. That means the protocol already gives very strong exact guarantees on the parts that matter operationally most. If an audited response used the wrong model, the wrong quantization/configuration, or a tampered input/deployment surface, the audit catches that exactly. That includes things like model swaps, silent requantization, and provider side prompt or system prompt injection. Today the implementation and measurements are strongest on Qwen and Llama. But the protocol itself is not meant to be Qwen or Llama specific: we expect it to generalize across open weight decoder only families. What still has to be done is the engineering work to integrate and validate more families explicitly, and we are already working on that. On the measured path, online generation overhead is about 12 to 14% with the provider staying on the normal GPU serving path. The heavier receipt finalization cost is separate and can be deferred off the user facing path. The main systems costs are RAM and bandwidth, not proof generation. The full response is always committed, but only a random fraction of responses are opened for audit. Individual audits are much larger, roughly 4 MB to 100 MB depending on audit depth. The important number is the amortized one: under a reasonable audit policy, the added bandwidth averages to roughly 300 KB per response. After too many weeks without sleep, I’m proud to show what I built with @diego_aligned: CommitLLM. Thanks Diego for your patience. I've been calling you at random hours. The code and paper still need some cleaning and formalization. We’re already in talks with multiple providers and teams that have cryptography related ideas on how to improve it even more. We’re really excited about this and we will continue doubling down on building products in AI, cryptography and security with my company @class_lambda. If governments, hospitals, defense and financial systems are going to run on LLMs, verifiable inference is not optional. It is infrastructure. I will be explaining this in more details in the days to come and I will show how to test it and run it.
English


For those who missed the first mint, another chance is coming.
1111 Penguin Z Free Mint soon on $ETH
Drop your EVM wallets

English



Had an opportunity to speak about @SentientAGI 🩷
Always making open-source AI win
Thx for the invite @Unibase_AI @0xzoe_im 🙏🏻


English
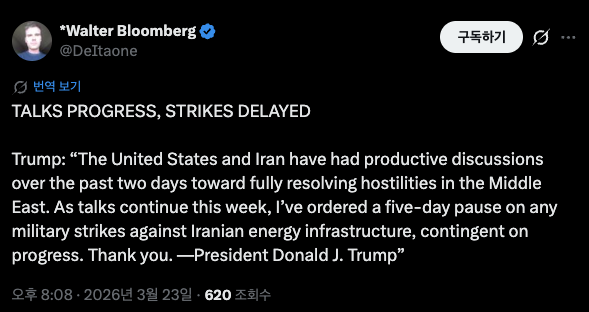
모건 스탠리, 현물 비트코인 ETF 신청 제출
@MorganStanley SEC에 현물 비트코인 ETF를 위한 S-1 신청서를 제출하고 업데이트했으며, 모건 스탠리 비트코인 트러스트를 출시할 계획을 추진중.
#모건스탠리 #현물 #비트코인

한국어
트럼프는 진짜 대단하네요...
🇯🇵 일본 기자
이란과의 전쟁을 시작하기 전에 왜 우리에게 말하지 않았나요?
🇺🇸 @realDonaldTrump
우리는 기습을 원했어요.
일본만큼 기습에 대해 잘 아는 나라는 또 있을까요? 진주만에 대해 왜 나에게 말하지 않았나요?
마지막에 다카이치 표정이 ㅋㅋㅋㅋ
#트럼프 #다카이치
한국어

인생 함박 스테이크 맛집 찾음
일본에서 살다온 친구가 일본에서 핫한 함박 집이라고 가자고함. 개인적으로 함박을 별로 선호하지 않아서 시큰둥 했지만 친구픽을 믿는 편이라 속는셈치고 가봄
근데 오늘 먹어보고 ㄹㅇ 감동함. 우리가 지금까지 먹었던건 진짜 함박이 아니었음. 한국인들은 그동안 사기를 당했던거임
한줄요약 : 꼭 가보세요
히키니쿠토코메 도산
서울 강남구 선릉로155길 21 2층
naver.me/531ezIH6

한국어

I'm giving away 4 whitelists for @OrdTorches 🥳
> Follow @jgonzalezferrer @OrdTorches
> Like the post below ❤️
⏰ Winners in 48h
OrdTorches@OrdTorches
Mint Announcement! Date: 19.03.26 Price: 0,00049 One more surprise before mint. 🪂 Collabs start now -> DM @0x6Paths
English
( ˃᷄˶˶̫˶˂᷅ ) 💗@ethena 화이트라벨!
약 2개월 만에 3개의 Stablecoin 총 공급량 $140M+ 달성
w/
@JupiterExchange
@megaeth
@SuiNetwork

한국어


@Pedgypenguin 0x26112ad891f1a64ba2722bae303b40dff85a843b
Please Please Please pudgy Penguins ~~~
English
4,444 Pedgys are coming to ETH for FREE
drop your EVM wallets

English

