Angehefteter Tweet

English
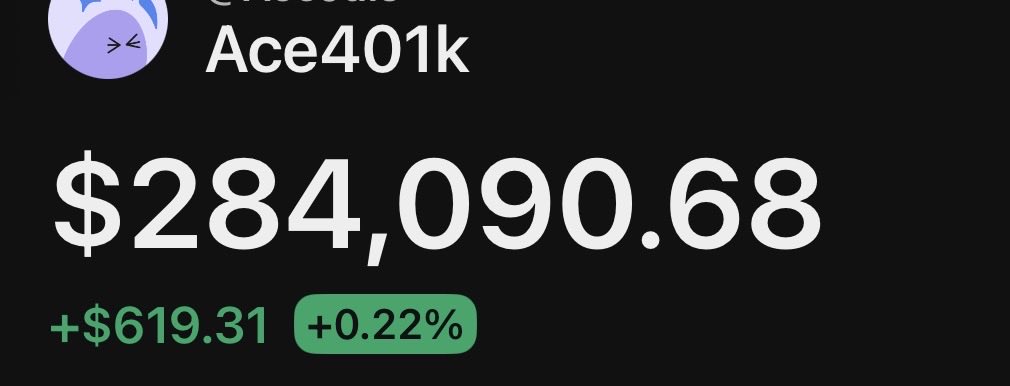
Yves crypto
3.5K posts

@cryptoyves1
professional MOD/project manager / check #Brothersmarketing for good services

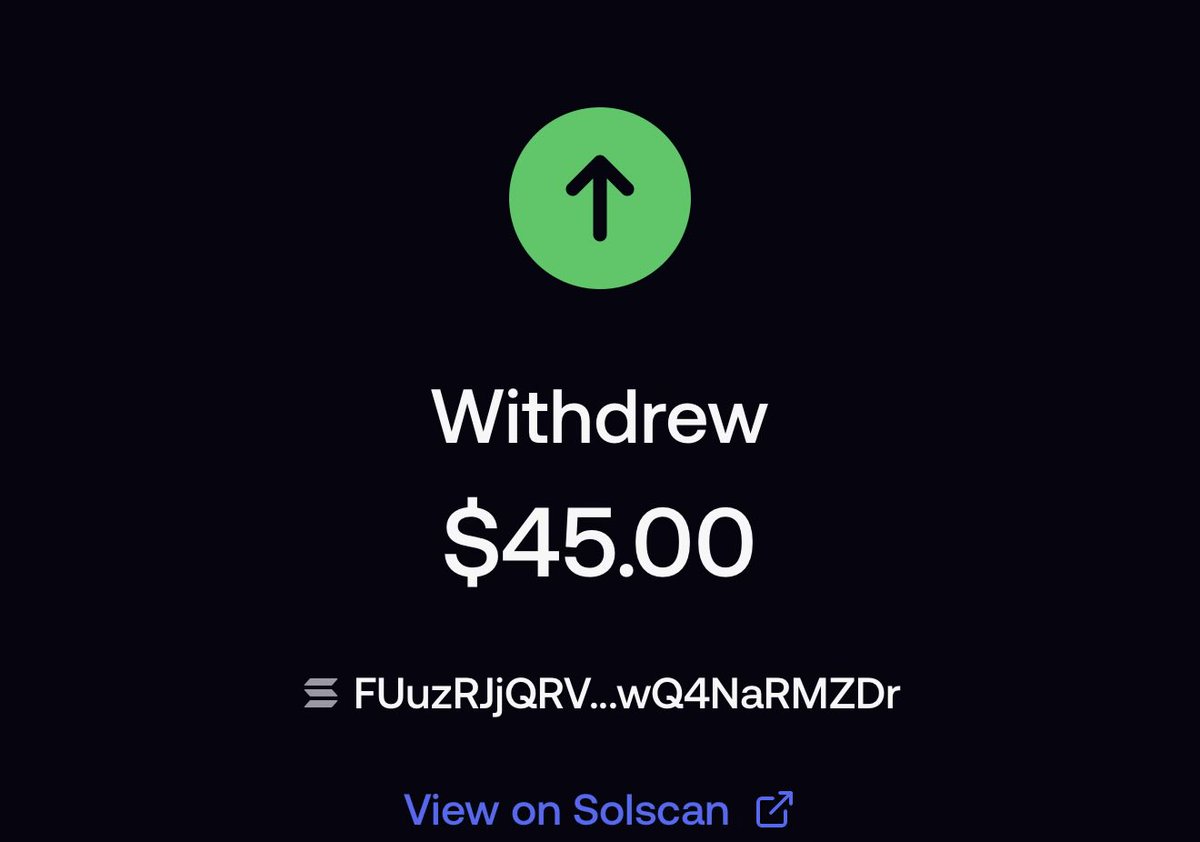
@AceAgain_ Ggs Ace Kindly send me a sol so I can go again into the trenches FUuzRJjQRVxnLvW6Dfp9k3MVpZZfx9jnTbwQ4NaRMZDr







TIME's new cover: The dire wolf is back after over 10,000 years. Here's what that means for other extinct species ti.me/4jlJB54