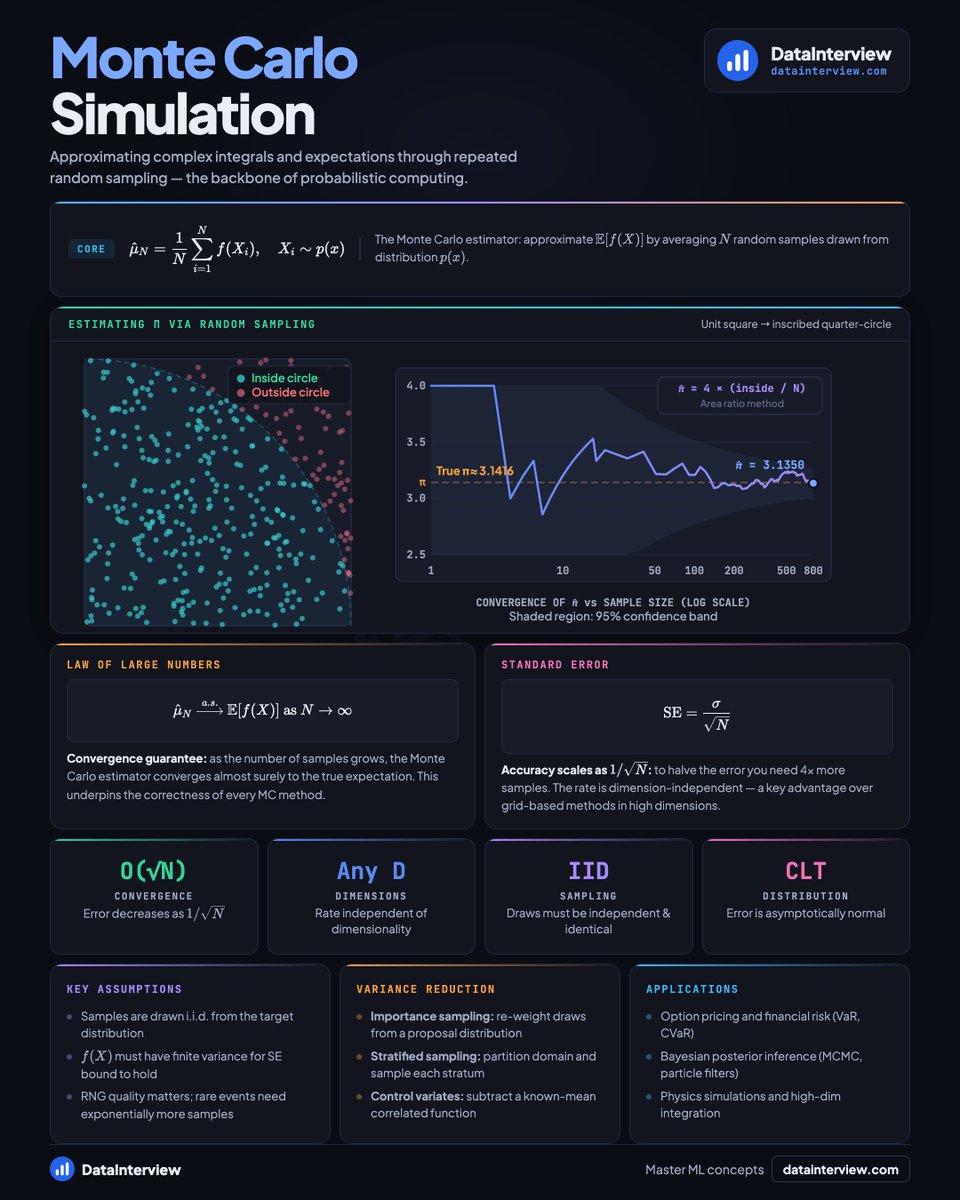
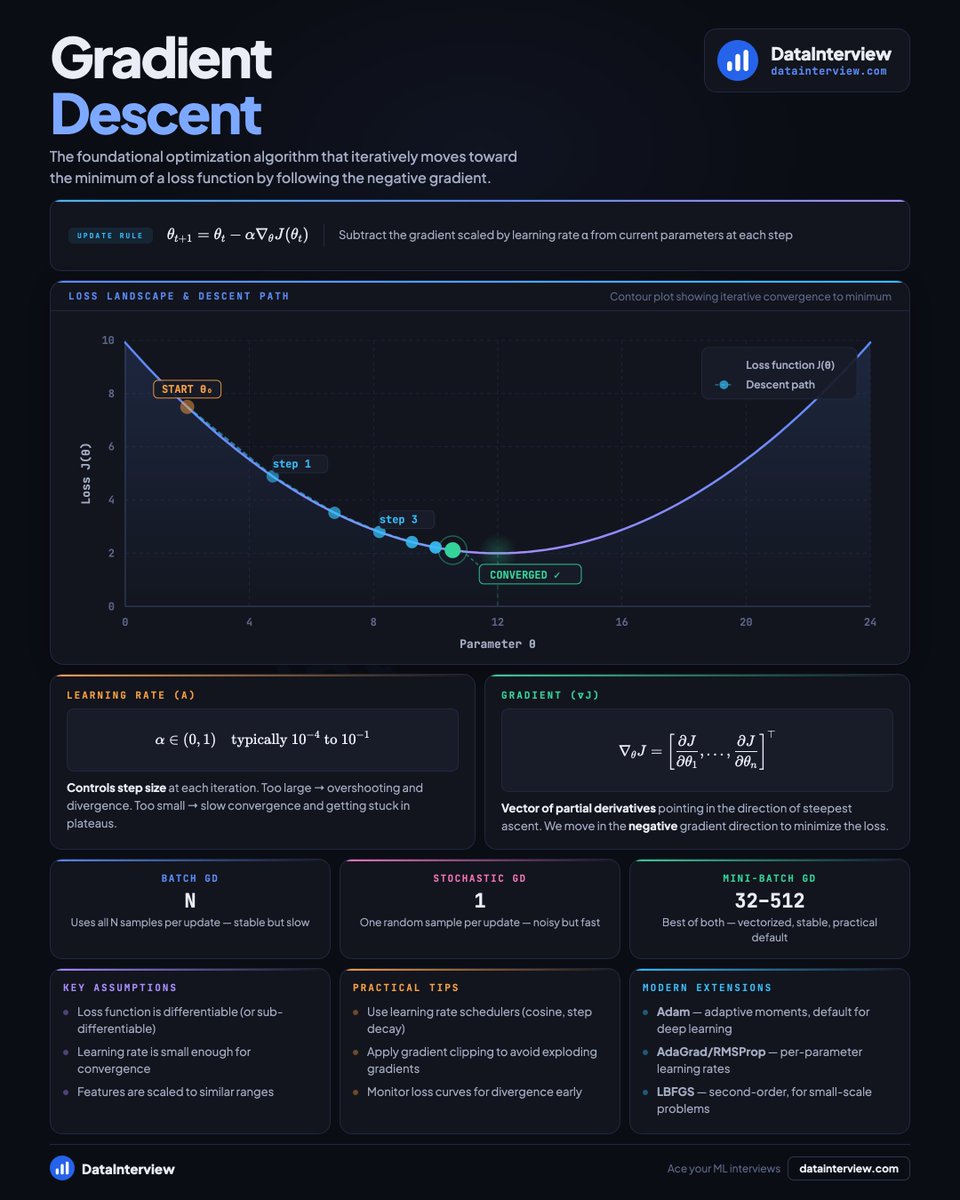
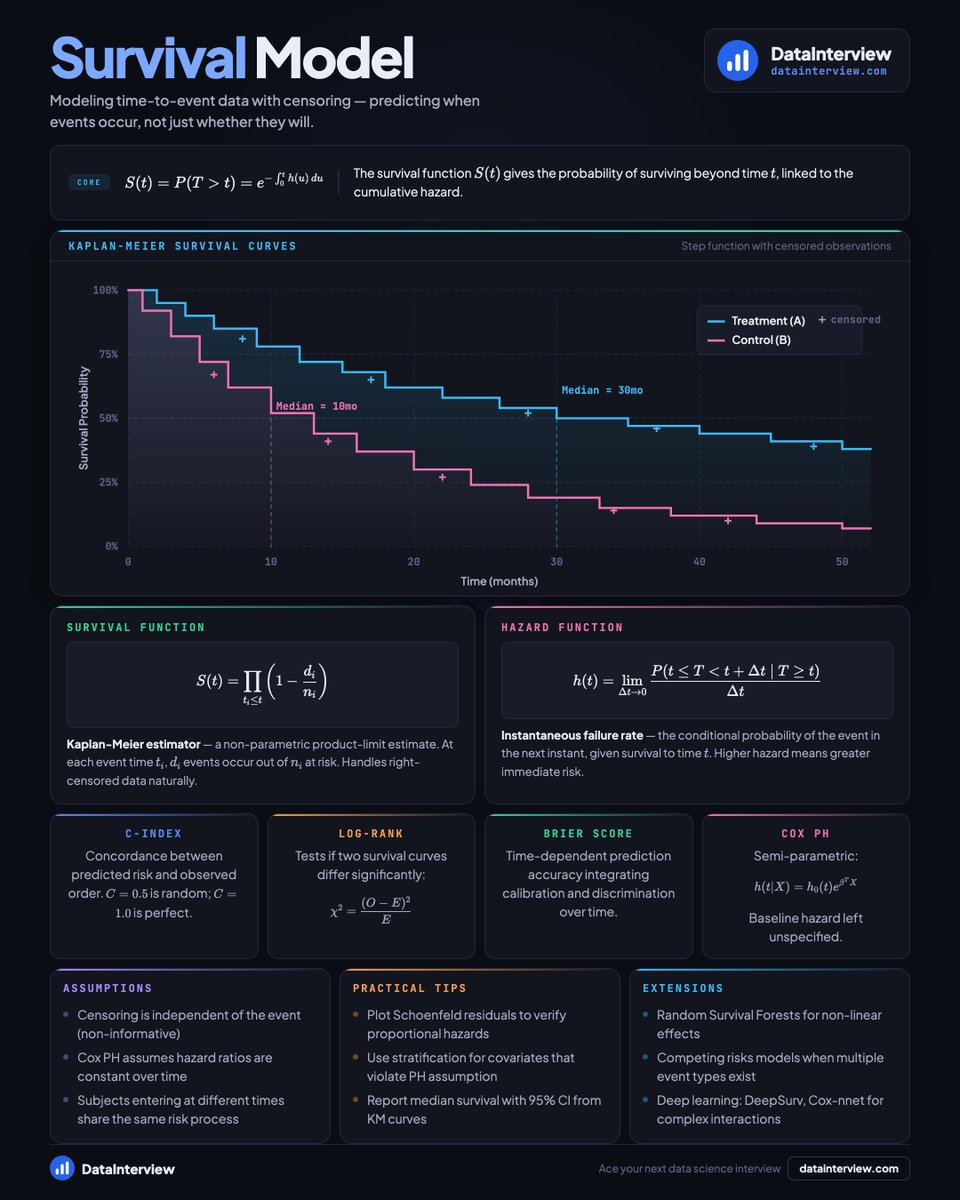
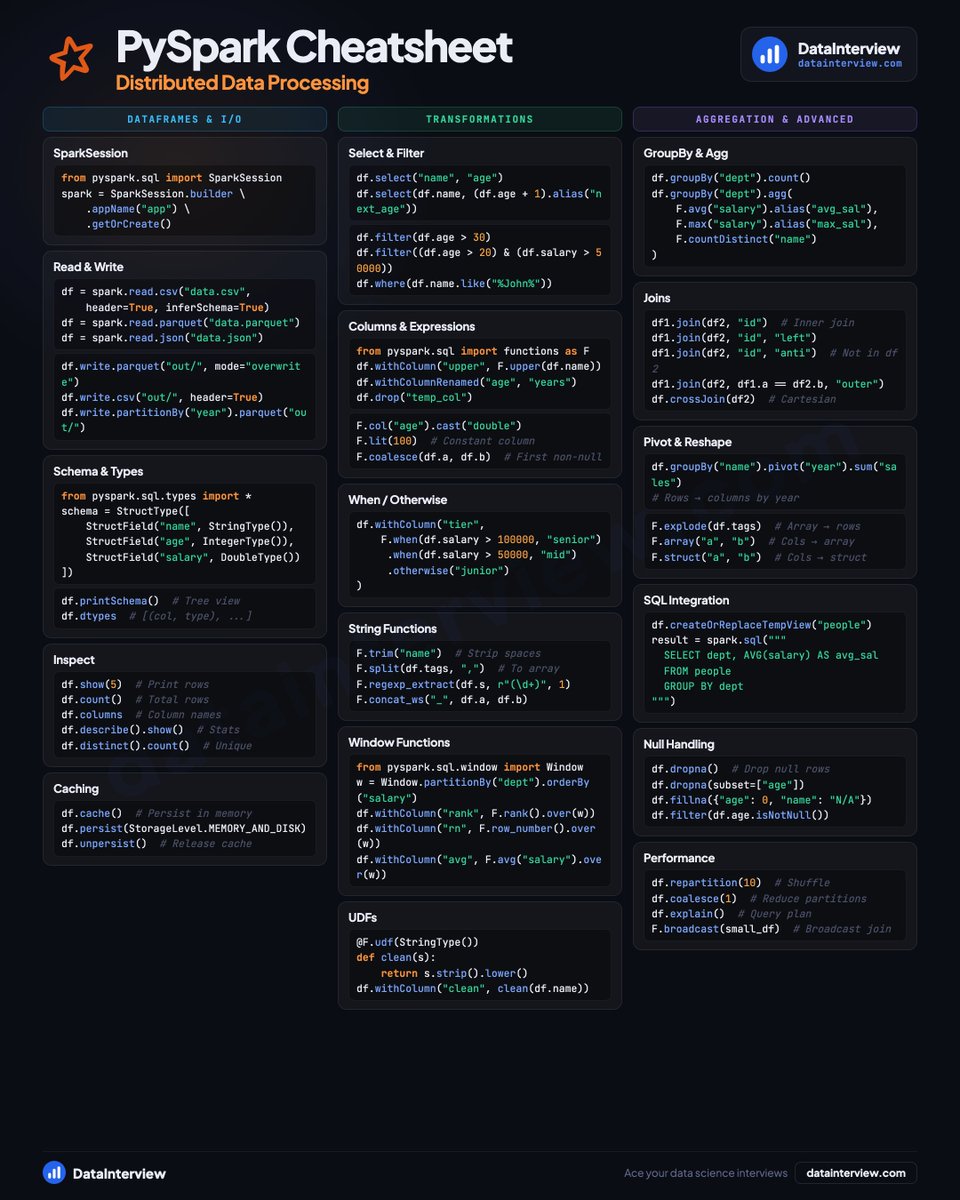
Here's a PySpark cheatsheet for data engineering interviews.
👋 Let's explore together ↓
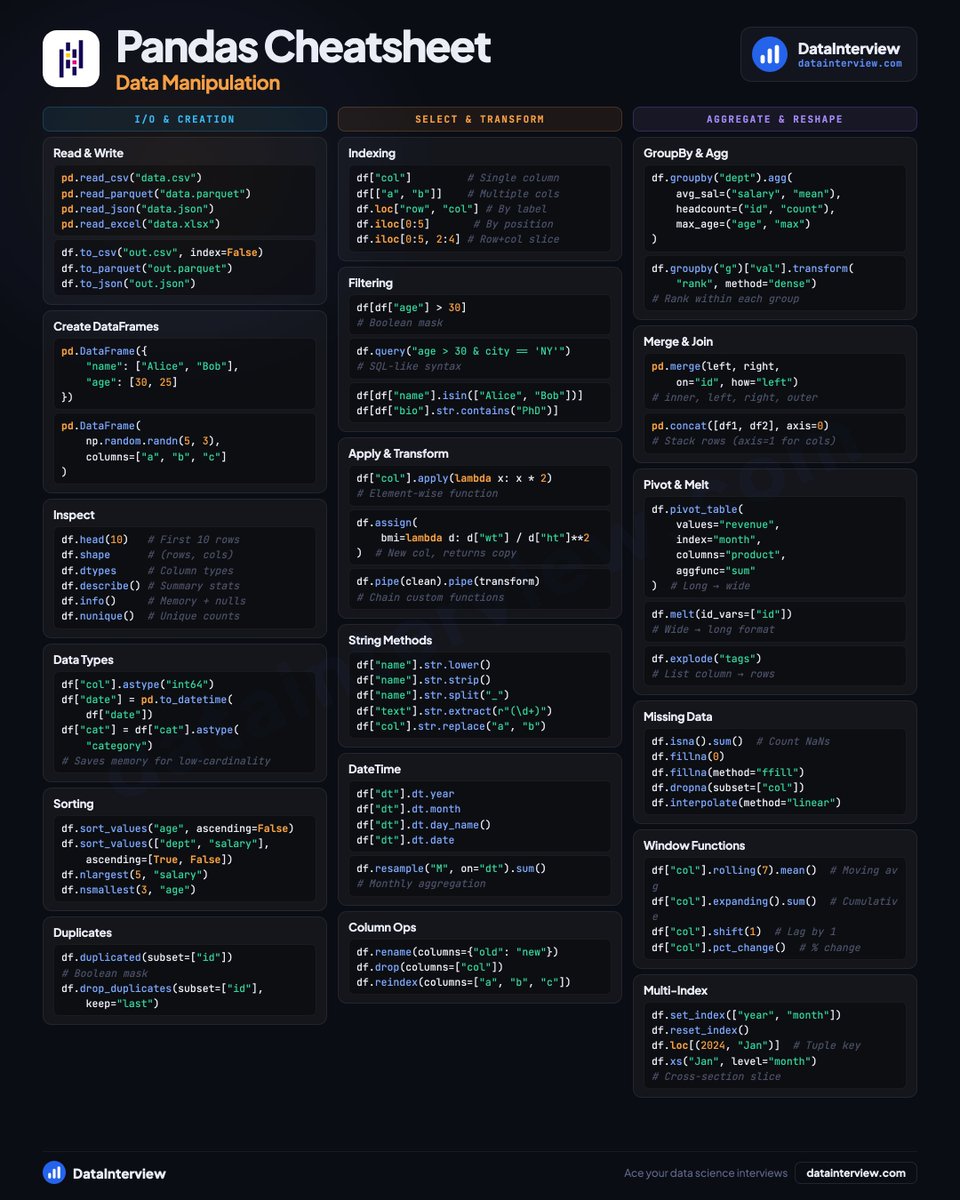
📦 𝗗𝗮𝘁𝗮𝗙𝗿𝗮𝗺𝗲𝘀 & 𝗜/𝗢
• SparkSession setup and configuration
• Read CSV, Parquet, JSON files
• Schema definition with StructType
• Inspect with .show(), .columns, .dtypes
• Caching and persistence levels
🔀 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻𝘀
• Select, filter, and .where() queries
• Columns and expressions with F.col()
• .withColumn(), .when/.otherwise
• String functions and regex extraction
• Window functions (row_number, rank, lag)
• UDFs for custom logic
⚡ 𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻 & 𝗔𝗱𝘃𝗮𝗻𝗰𝗲𝗱
• GroupBy with named aggregations
• Joins (inner, left, anti, cross)
• Pivot, explode, and reshape
• SQL integration with createOrReplaceTempView
• Null handling (dropna, fillna, coalesce)
• Repartition and broadcast joins
Save this for your next interview.
👉 Land Data, Quant, AI jobs on datainterview.com
English