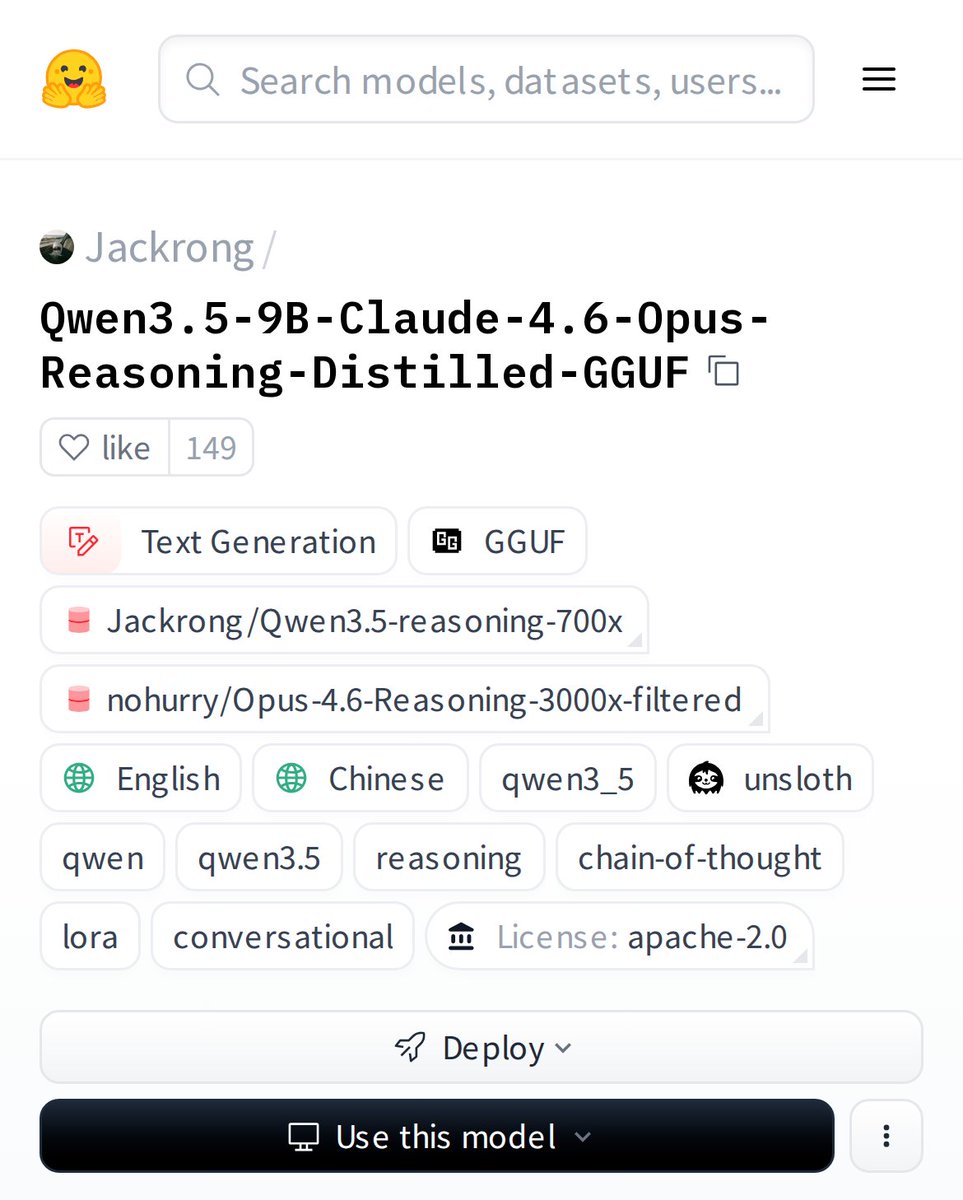
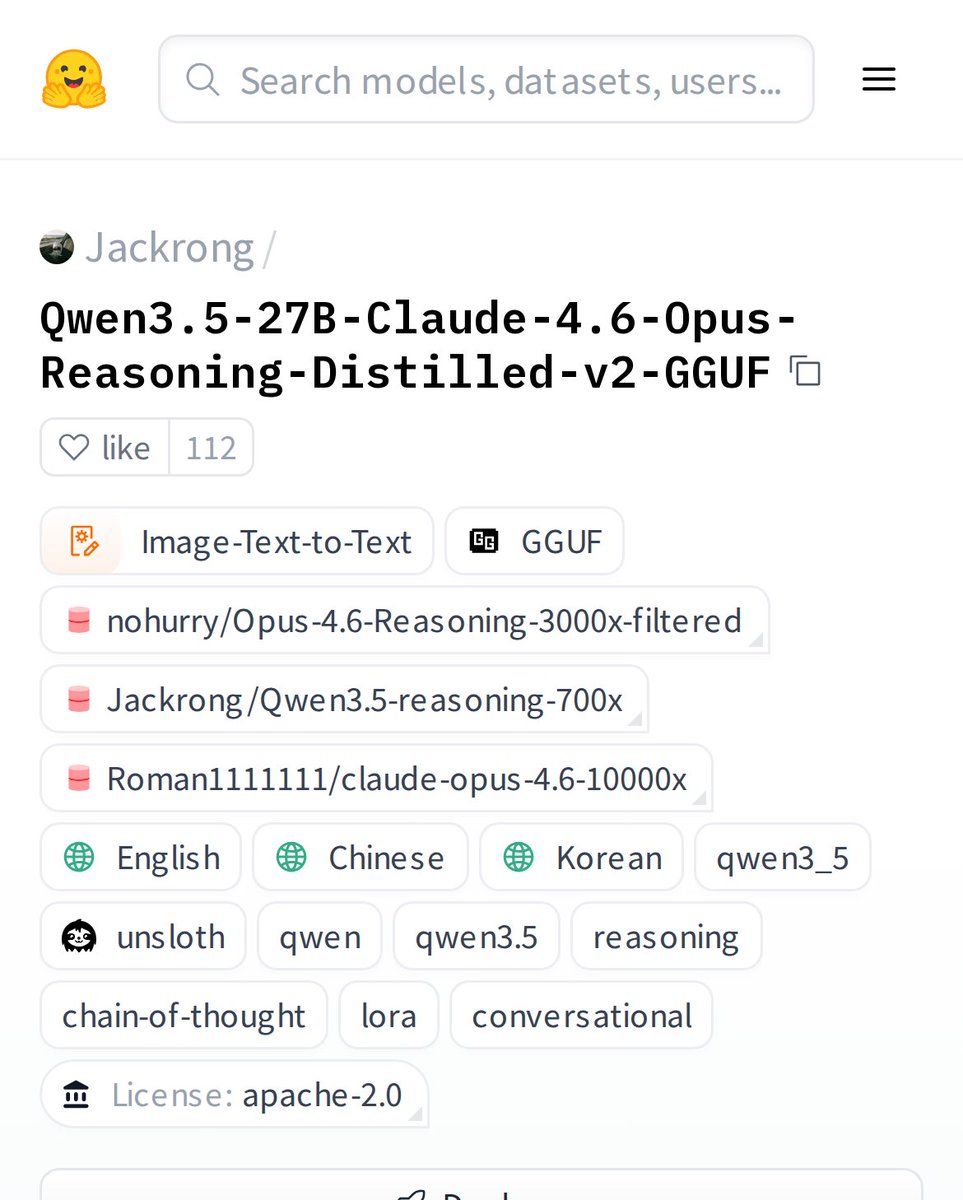
Safwan Shaheer retweetet

Google dropped the TurboQuant paper yesterday morning. 36 hours later it's running in llama.cpp on Apple Silicon, faster than the baseline it replaces.
the numbers:
- 4.6x KV cache compression
- 102% of q8_0 speed (yes, faster, smaller cache = less memory bandwidth)
- PPL within 1.3% of baseline (verified, not vibes)
the optimization journey:
739 > starting point (fp32 rotation)
1074 > fp16 WHT
1411 > half4 vectorized butterfly
2095 > graph-side rotation (the big one)
2747 > block-32 + graph WHT. faster than q8_0.
3.72x speedup in one day. from a paper I read at dinner last night.
what I learned along the way:
- the paper's QJL residual stage is unnecessary. multiple implementations confirmed this independently
- Metal silently falls back to CPU if you mess up shader includes. cost me hours
- "coherent text" output means nothing. I shipped PPL 165 thinking it worked. always run perplexity
- ggml stores column-major. C arrays are row-major. this will ruin your afternoon
everything is open source. the code, the benchmarks, the speed investigation logs, the debugging pain, all of it.
github.com/TheTom/turboqu…
paper to parity in 36 hours. what a time to be alive.

English