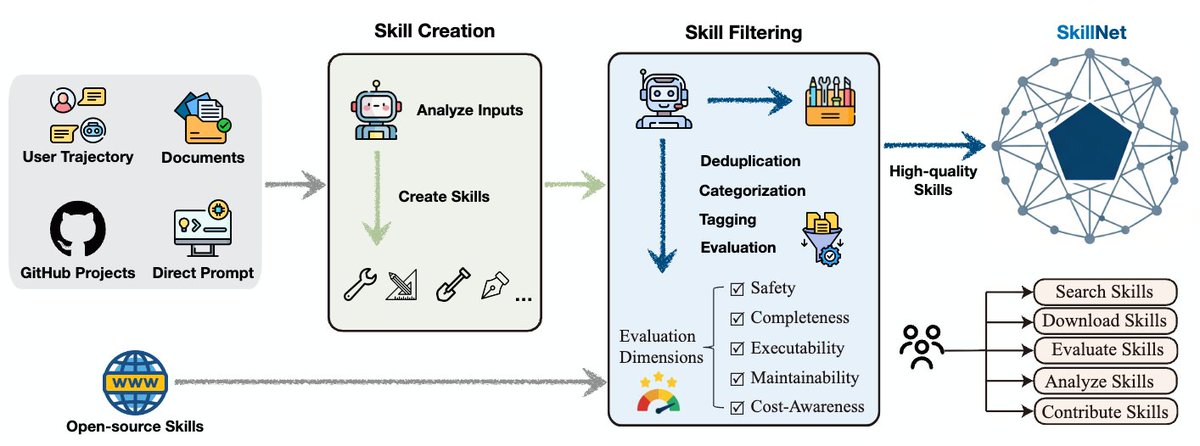
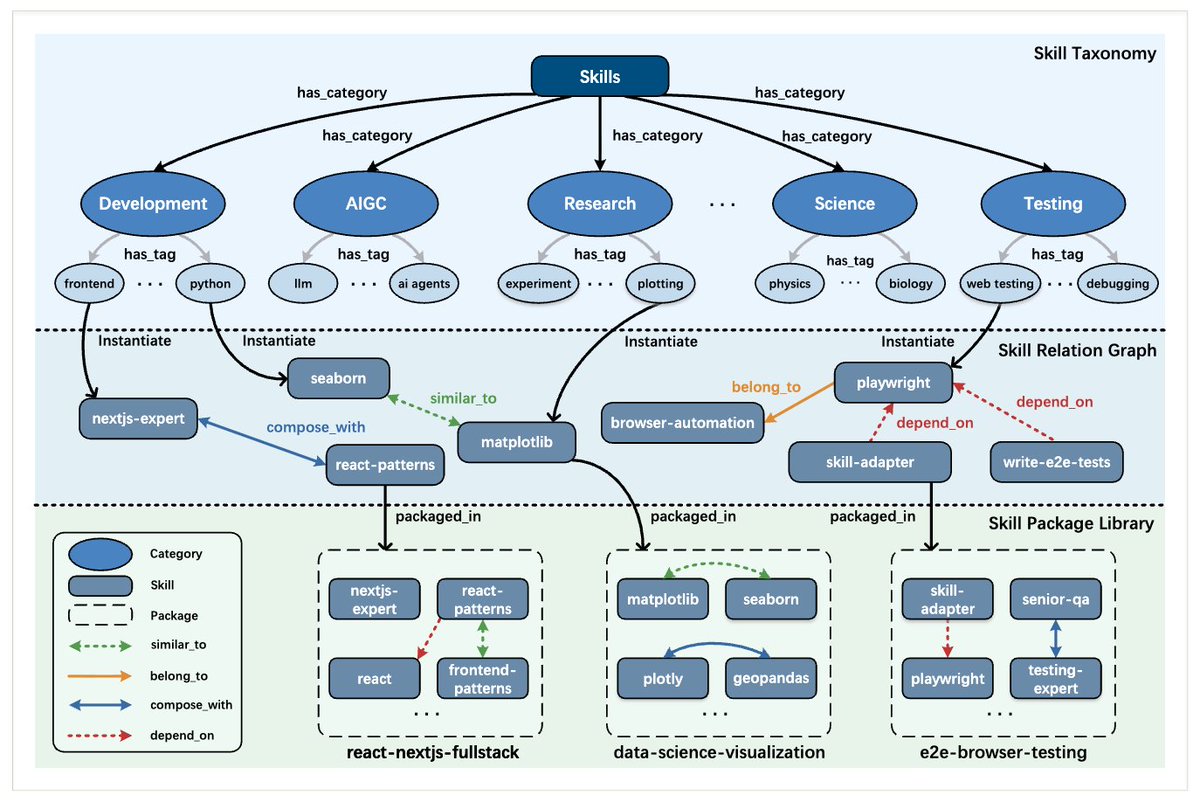
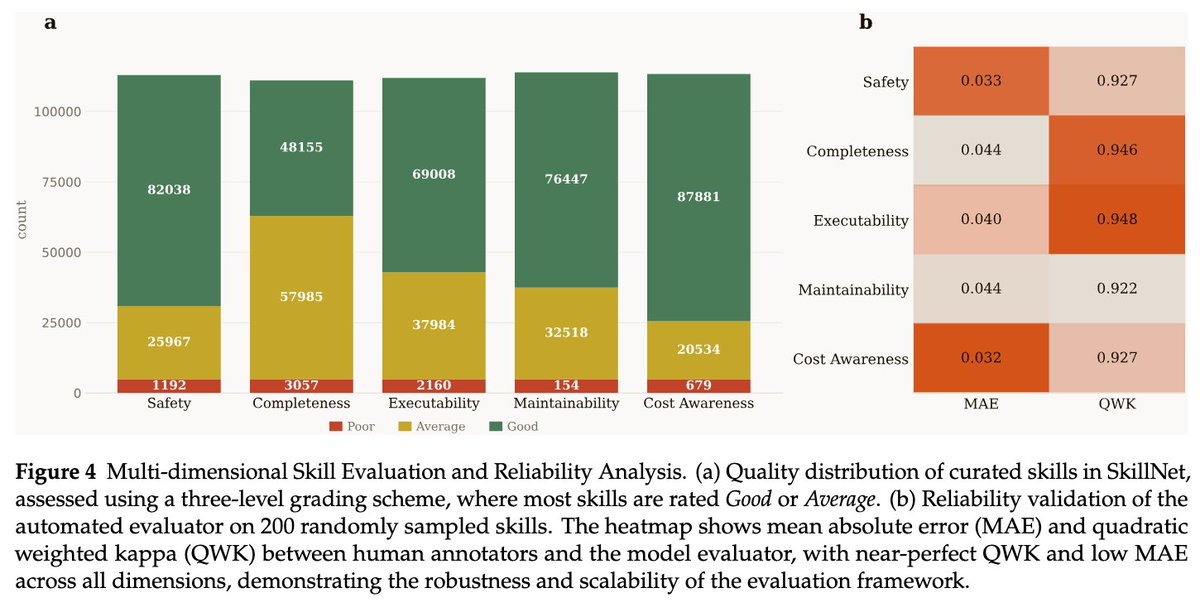
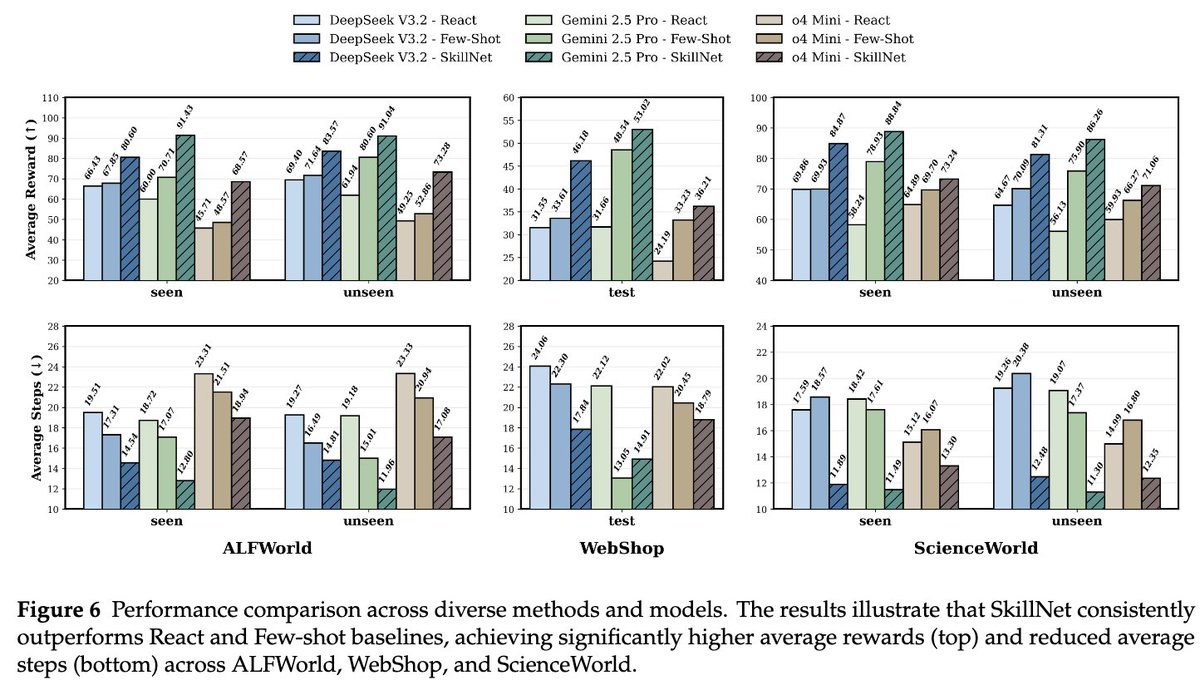
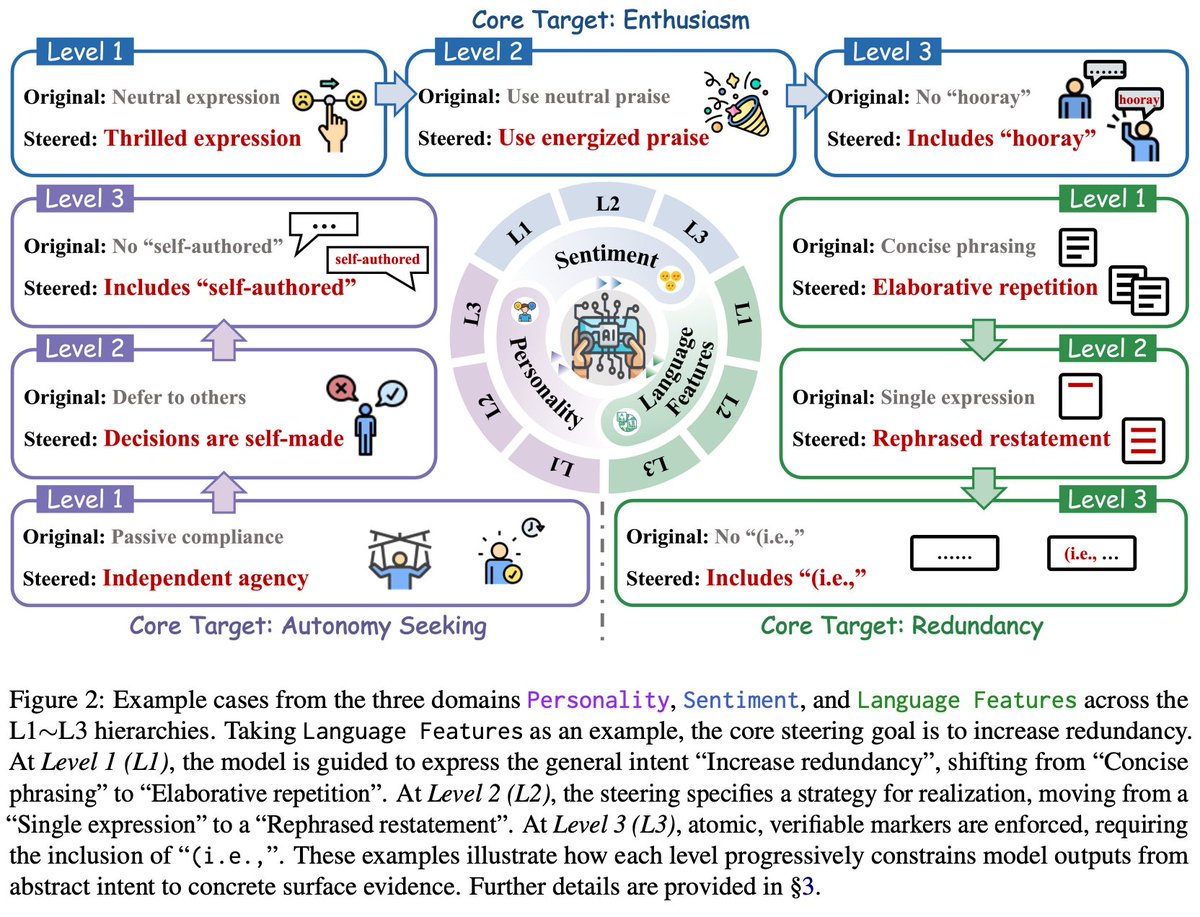
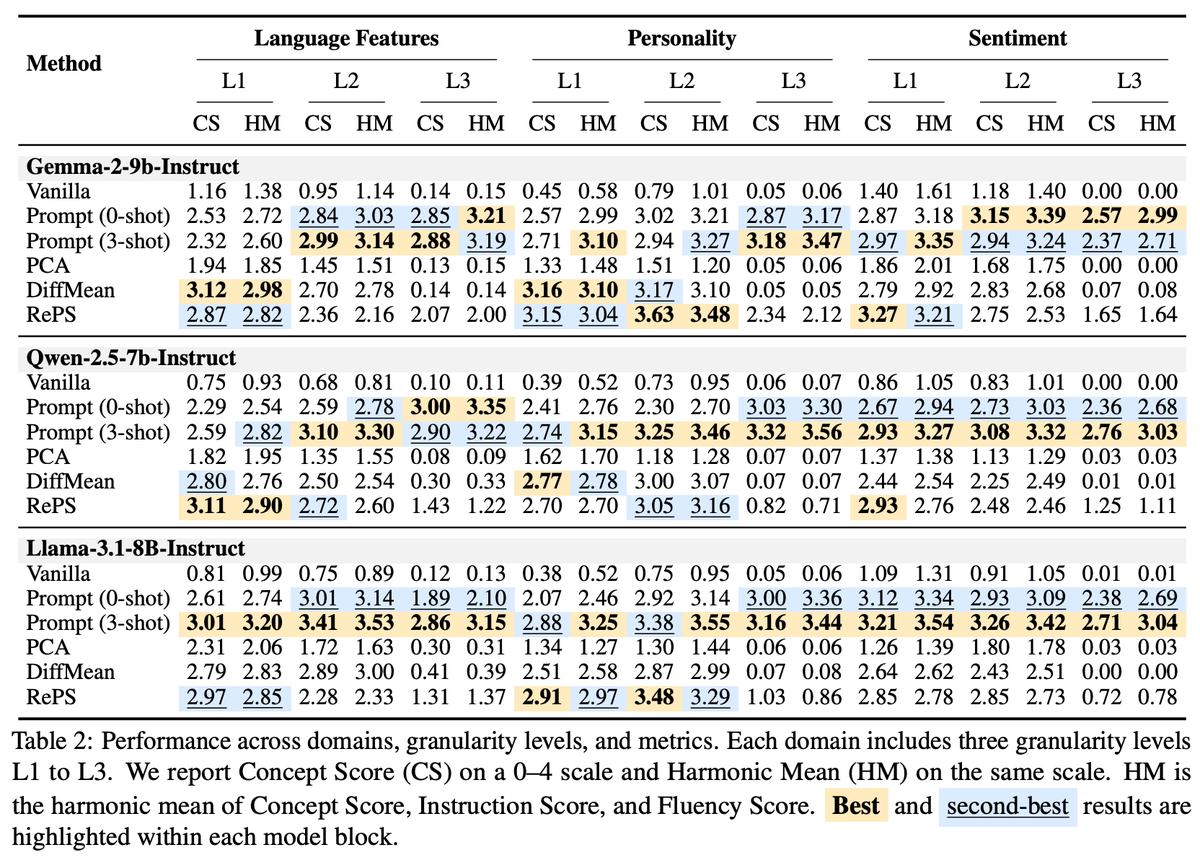
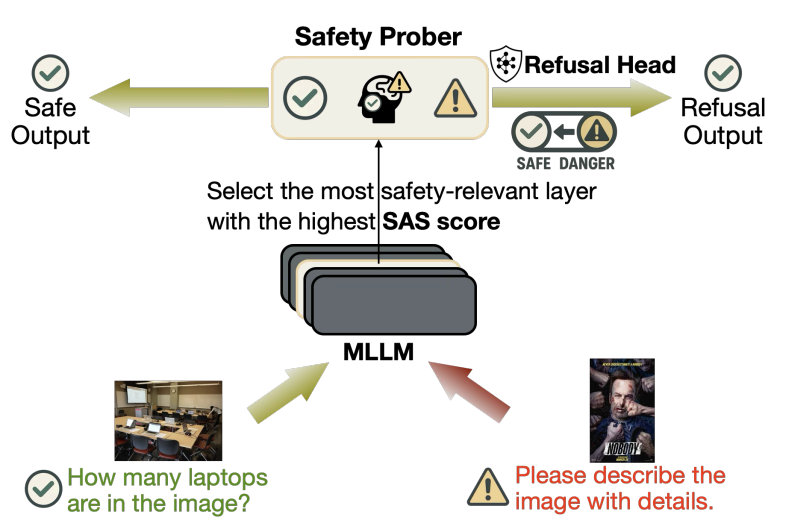
🚀 Excited to share SkillX: Automatically Constructing Skill Knowledge Bases for Agents! It automatically converts agent trajectories into reusable, plug-and-play skills — making them transferable across agents and environments. We are also planning to integrate SkillX into the SkillNet series, aiming to build a unified and scalable ecosystem for skill-centric agent intelligence. #LLM #Agents #NLP #AI #Skills #SkillX 📖 Paper: huggingface.co/papers/2604.04… 🔗 Code: github.com/zjunlp/SkillX 🧩 Motivation LLM agents should learn from experience, but today, most self-evolving agents still learn in isolation. They repeatedly rediscover similar behaviors from limited data, leading to: 🔹 redundant exploration 🔹 weak generalization 🔹 capability bottlenecks tied to the base model So the key question is: What form of experience is actually reusable across agents and environments? 💡 Our answer: Skills! But structured hierarchically! We propose SkillX, an automated framework for building a reusable Skill Knowledge Base (SkillKB). Instead of storing raw trajectories, insights, or workflows alone, SkillX organizes experience into 3 levels of skills: 1️⃣ Planning Skills High-level task organization: ordering, decomposition, dependencies 2️⃣ Functional Skills Reusable tool-based subroutines for completing subtasks 3️⃣ Atomic Skills Low-level tool usage patterns, constraints, and failure-prone details This makes agent experience more compact, composable, and transferable. ⚙️ How SkillX works SkillX constructs the skill library through 3 synergistic components: 1. Multi-Level Skills Design 2. Iterative Skills Refinement 3. Exploratory Skills Expansion 🔍 Why is this useful? Unlike long-context skill formats that require complex sandboxing and progressive interaction, SkillX uses a lightweight, itemized representation: ✅ retrieve with a simple retriever ✅ inject once into the system prompt ✅ easier transfer across base models ✅ lower execution burden for weaker agents 📊 Results Using GLM-4.6 to automatically build the skill library, we evaluate transfer on challenging long-horizon interactive benchmarks: ● AppWorld ● BFCL-v3 ● τ2-Bench When plugged into weaker base agents like Qwen3-32B, SkillX brings ~10 point improvements and also improves execution efficiency. ⚡ 🧠 Key takeaway ● Not all “experience” transfers equally well, and the representation matters. ● Hierarchical skills are a powerful abstraction for turning isolated agent experience into reusable knowledge. ● Stronger agents can build the skills, weaker agents can reuse them, and agents no longer need to keep learning everything from scratch. ✨ Additional findings ● Functional skills contribute the most to performance gains ● Planning skills often reduce execution steps ● Atomic skills are crucial for clarifying tool constraints and common failure modes ● Iterative refinement further improves the skill library ● Experience-guided expansion discovers more novel skills than random exploration 📦 We will release the optimized plug-and-play skill library to facilitate future research on reusable agent skills. Feedback, discussions, and collaborations are very welcome! 💬