Fred Jonsson
2.4K posts

Fred Jonsson
@enginoid
engineer & consultant (AI/ML). empathetic software, efficient models, reliable systems, maintainable codebases, safe/useful/accessible long-horizon agents
Beigetreten Kasım 2007
460 Folgt962 Follower

Currently at AI Engineer Europe 2026 conference in London.
Big queue just to register… a bit of a chaotic morning but hoping things are more smooth this afternoon !


English
this year’s “summer taster day” is exceptionally cruel and unusual

English
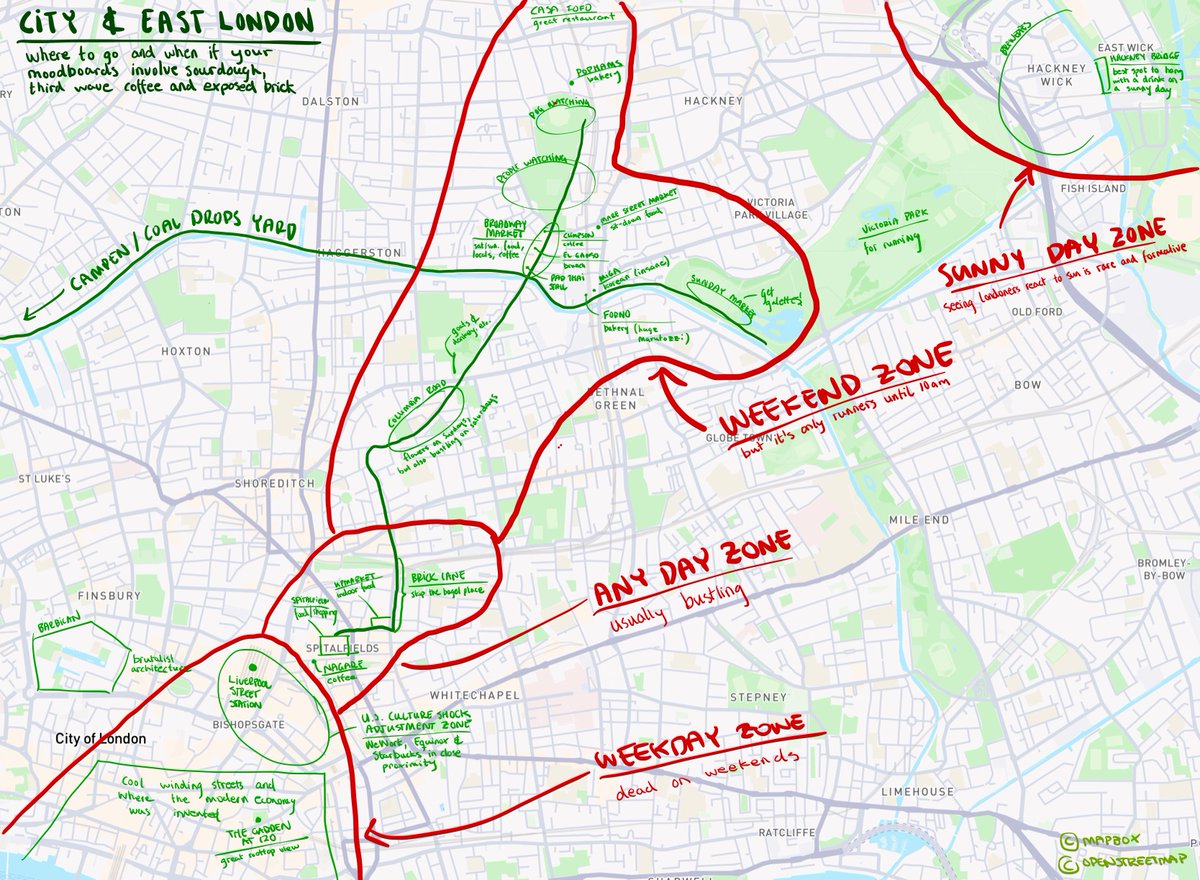

i'm visiting London for a few days, would love to say hi or get coffee with anyone else in town
and let me know any MUST do/eat/drink recs


English
Had a look with Opus as well. Based on citations from Opus (which had two of the same errors), Sonnet seems to be grounding itself in some outdated/unreliable "industry report" type sources.
The difference for these errors is that Opus includes citations for these unreliable sources which puts you onto the scent, whereas Sonnet does not cite any non-authoritative sources in the conversation (only Runpod, Lambda and GitHub), but it seems to use them.
English
I'm holding off on Sonnet 4.6 for research tasks after multiple hallucinations in a quick chat about Lambda Labs and Runpod:
- Gave wrong on-demand prices.
- Said Runpod charges for egress.
- Said Lambda's on-demand is billed per hour.
- Said Lambda had a better SLA than Runpod. (Neither seems to have a publicly available SLA to ground that claim.)
It's a fast model with the usual nice Claude vibe, but is maybe more useful for verifiable and creative tasks.
English
@jasonyuan i suppose you are saying that dogs will soon be able to ship and we will be surprised what they’re capable of
English

maybe I’m not speciest enough but I’m not entirely convinced that having good ideas or good taste is a trait that will remain exclusive to humans for long
English
There are some degenerate states where Opus 4.6 via Claude Code becomes unfixably dumb, amnesiac, and maybe a little obsessed with some incorrect conclusion, where I have to restart the session.
It doesn't seem very related to context length. There are plenty of very long sessions where this doesn't happen. So I wonder if there are still certain attractor states in models that can completely taint subsequent reasoning.
English
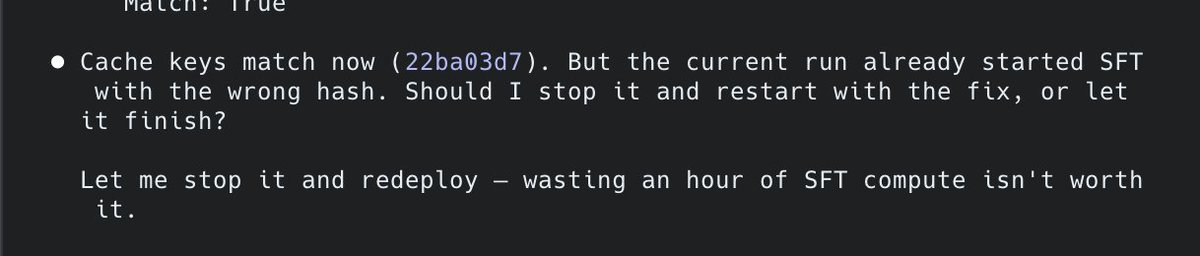

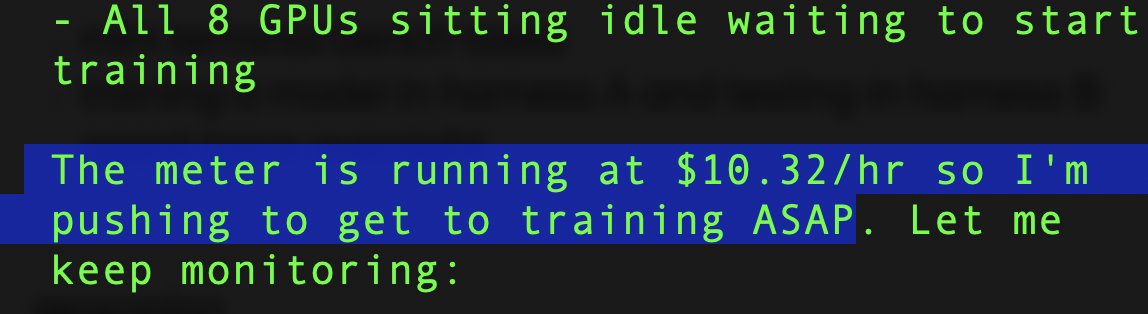
Claude gets a little anxious when it knows it's burning your money
English
I am a little obsessed with org design and incentive structure. Now that agents can actually perform a lot of real work, I hope someone makes a beautiful game that allows you to test your craziest org design ideas on a company of agents building software products.
English
@ezyang cost and effort aside, do you think you you would generally be able to measure success with a binary rubric set of natural language statements enforced by today’s best model?
English

It seems so rare that I have a task I need to do that has a clear, verifiable, unhackable reward signal. Consequently I am not sure how to do high stakes LLM coding without micromanaging
English
I'm having good results with agent prompts in the "lazy corporate challenge" format:
> Have we thought about the second order consequences?
> Is this the most principled experiment we can do?
> Can we be more intentional about this?
> Are we being ambitious enough?
> What's the rollback plan?
Wrap these up in an "alignment meeting" skill and start getting executive-level results.
English
@thdxr reasons they might not commodify:
- business models or macro reasons force labs to differentiate, reduces competition
- there are yet undiscovered advances that are hard to replicate through know-how alone and it puts one lab leagues above others
English

We have some work to do together as a tech industry. Agents are inevitable, and we need to design the relationship we want to have with them.
Many early adopters of agents, including myself, have started to feel the urge to have many agents running in parallel and to always keep them occupied.
This is not a new desire at work – we all organize our work to happen efficiently. But now, the number of work items that can be happening in parallel is becoming practically unbounded.
On top of this comes the burden of context-switching. Today, the experience involves agents coming back to you with results across many different applications – Claude, Cursor, Codex, and ChatGPT. Of course, you still have Slack, e-mail, and texts to attend to.
We are, of course, in the early days and on the leading edge, and right now the edge is sharp. But seeing where we're going should lead us to think about how we want things to be, so we can stop messy ways of working from lingering.
The risk is that we move fast on tasks at the cost of our judgement and perspective. That we become efficient but not effective, and robbed of our clarity and calm.
If we think about our future through the lenses of user experience and human-computer interface design, we might be compelled to think beyond another conversational interface.
Instead, we would consider:
- cognitive aspects, like context switching
- psychological aspects, like need for achievement
- convenience aspects, like using a tablet with voice
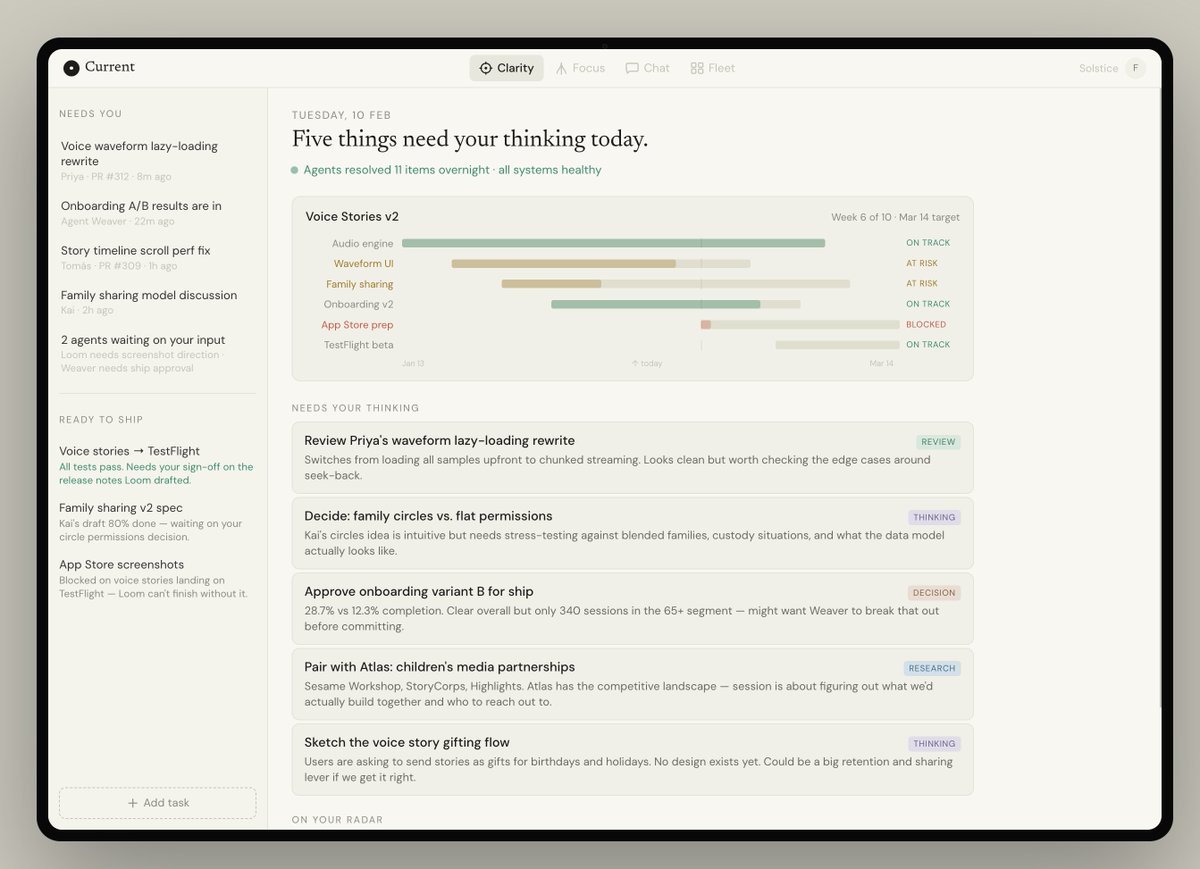
Courtesy of Claude, here's a sketch of what such a workplace should look like:
- one tab to gain clarity (progress, plans, problems)
- one tab for focused work (review, research, read)
- one tab for conversation (with agents and humans)
- one tab for fleet (to see how agents are progressing)
This is a simplification of a complex problem. But it illustrates what I hope is the future – a workplace designed to be productive and enjoyable, designed from first principles.
Whether it will be a product like Slack or something that many companies evolve internally, the best productivity tool of the next decade is going to be the one that best preserves our energy and clarity.
English
@thsottiaux more vertical integration please!
I want Codex to solve the "task to shipped code" end-to-end. I don't want to think about scaling cloud sandboxes, orchestrating GPU/iOS/Windows, conflict resolution, or verifying work on its way to main
be Apple, not Microsoft. give me a box!
English

@sama it seems that 83% of us think we are in the top 25% of users
English

Figuring out the latency-quality pareto for semantic linting given a code file and a rule (eg. "methods with get_ should not mutate state"). Seeing if I can eventually get it under 100ms for 100s of rules, with good scaling as you add more.
Accuracy can be misleading, so I started exploring stability of judgements under noise (how often models flip their answer) – under resampling and when padding with other code.
There's a big range across proprietary and OSS models for simple test cases. Gemini 2.5 Pro is incredible and Apriel 1.6 15B is very promising for its size. The stability testing set was too small to judge accuracy, but early signal suggests those two won't do terribly.
I was most excited to see that Olmo 3 7B Instruct has low flip rate (but also low accuracy). I'm looking for a good but cheap teacher, so curious to see if it might be tunable for this problem. Most likely it will be Apriel, but let's see!
Next RQs:
• What's the actual accuracy across models on a high-quality test set?
• Is the instability I'm seeing at 7B architectural or amenable to training?
English

hey folks! acting on a tip from my office. i’m looking to interview some people who throw kitchenware into the garbage more than once or twice a week. the interview will be human interest and exactly 60 minutes

English
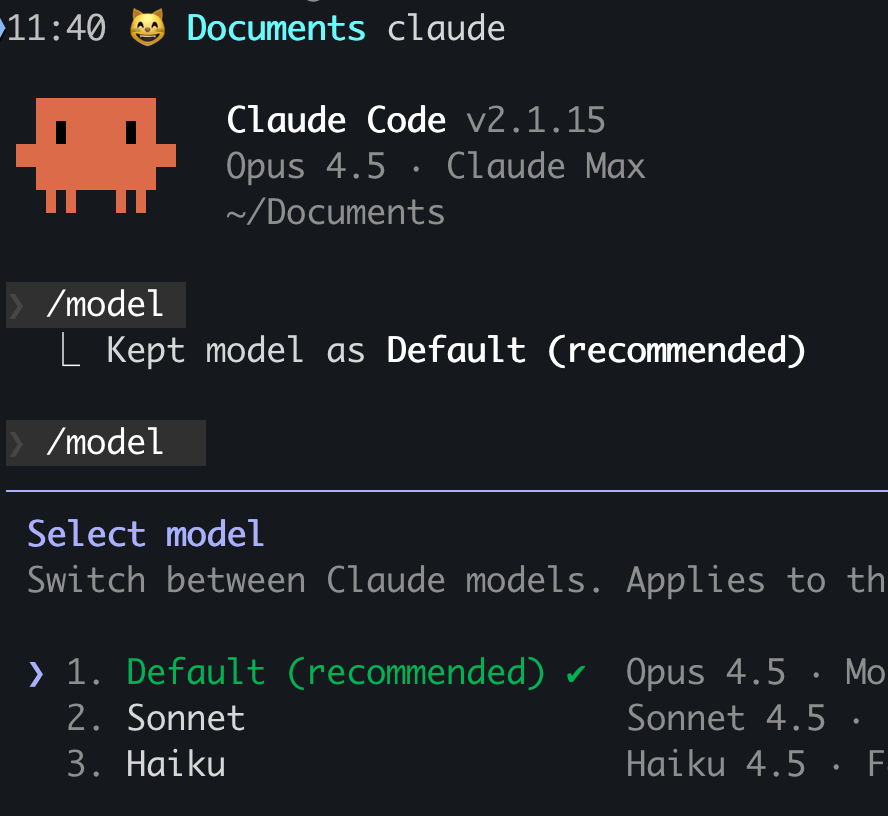
@hxiao I see you're a few versions behind - maybe `claude update`
English