0xGerbot retweetet

50 years ago today, this first-ever shot for ‘STAR WARS’ was captured.

English
0xGerbot
4.2K posts


@gerbot_
I like building stuff, securing stuff, and hacking stuff* *Stuff = apps


Job interview: "Any management experience?" Me:

✍️ "It has been a strange journey for Arsenal supporters to go from fans of a venerable old club to a bunch of insufferable pearl-clutchers," writes George Chesterton. Read why George, as a lapsed Arsenal supporter, finds Arsenal fans insufferable ⤵️ telegraph.co.uk/football/2026/…
South Korea's giant dachshund sculpture, nicknamed Sunshine, is a hyperrealistic, ‘breathing’ art installation
Hey, do you like extra spicy noodles?

First look at Michael Mando as Scorpion in ‘SPIDER-MAN: BRAND NEW DAY’.




How Chelsea signed a star team with hidden payments 🔺 £47.5m paid to 12 individuals or corporate entities 🔺 Involved deals for Hazard, Luiz, Matic, Ramires, Willian 🔺 Why have some names been redacted? 🔺 Why did Chelsea escape stronger punishment? bbc.co.uk/sport/football…
A nanobot picks up a lazy sperm by the tail and inseminates a waiting egg in it

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…

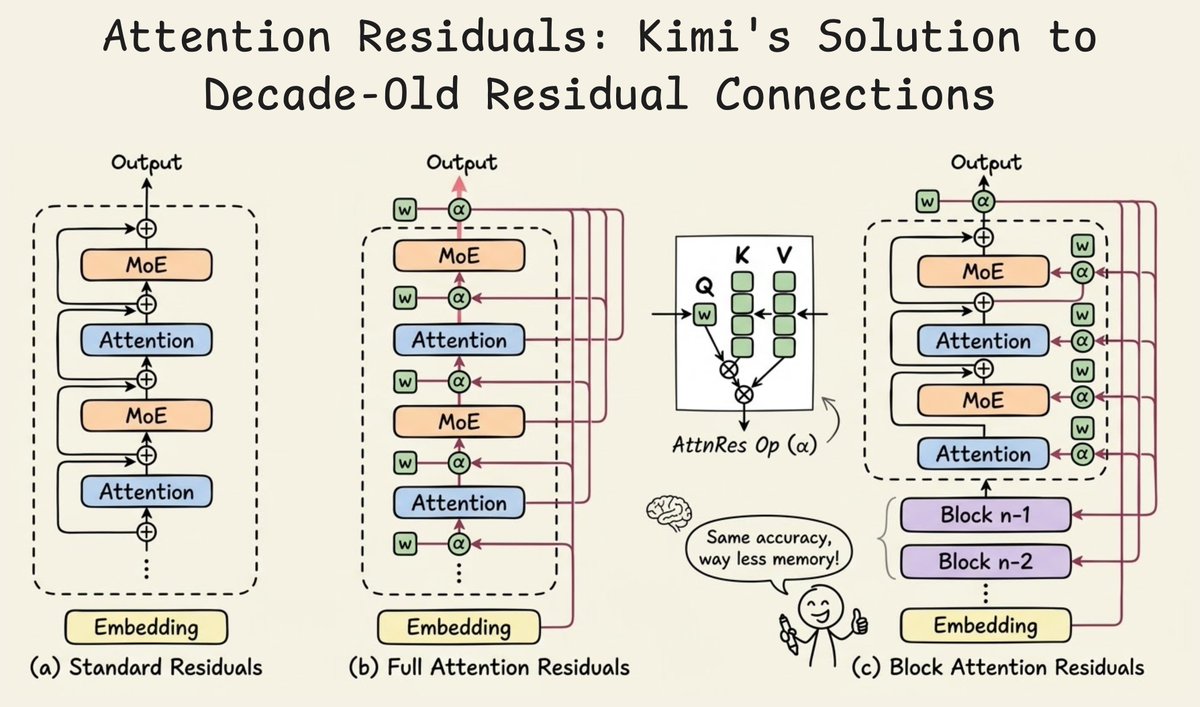
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…

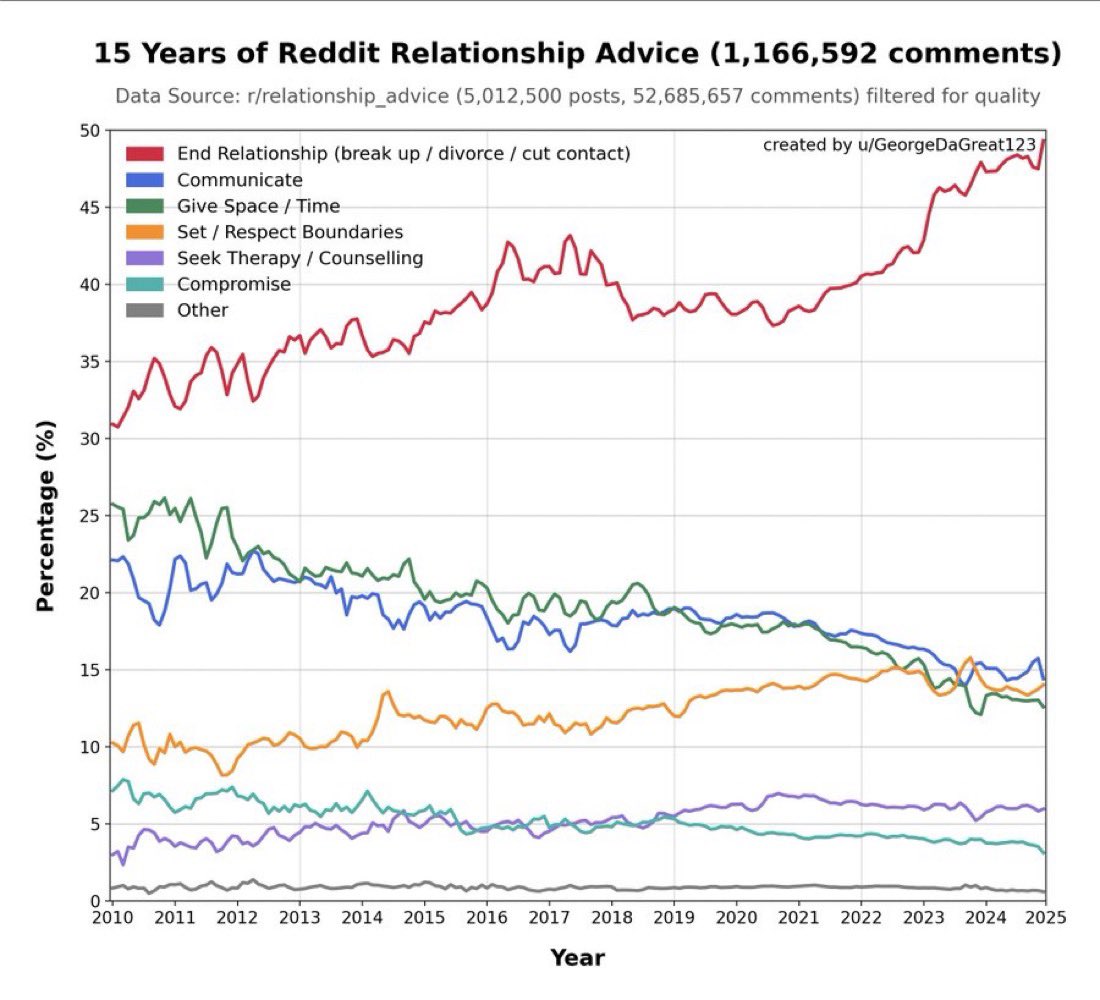
LLM that keeps telling people to break up because it’s been trained on relationship advice subreddits





