@petergostev Note Amazon Ads revenue. It is fun how folks who didn’t read their SEC filings claim Amazon is about AWS lol
English
Evi
4.8K posts

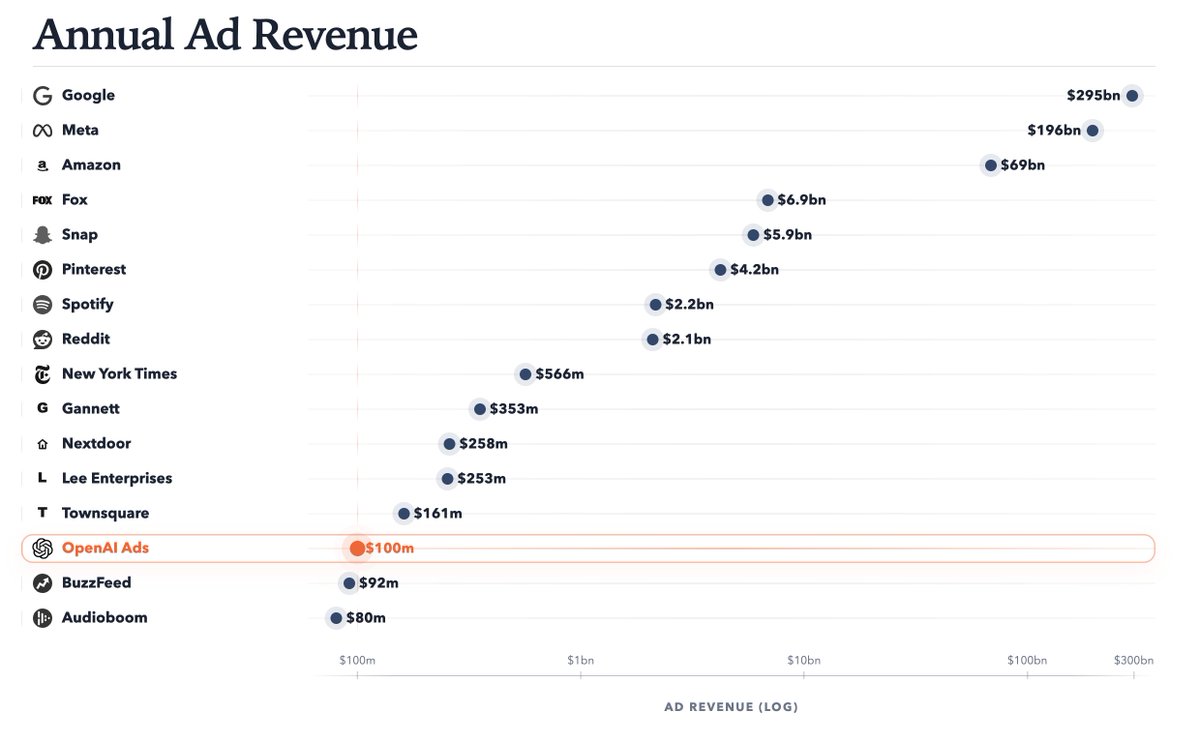
New: OpenAI has surpassed $100m in ARR from its ads pilot, which launched 6 weeks ago. It's expanded to 600+ advertisers and plans to launch self-serve advertiser access in April. theinformation.com/briefings/excl…



Earlier this week, we published our technical report on Composer 2. We're sharing additional research on how we train new checkpoints. With real-time RL, we can ship improved versions of the model every five hours.


Codex is already really good and my daily driver. But they really need to fix how terrible GPT-5.4 regardless of reasoning effort is at design/UI. It's seriously really bad. Hopefully this means it gets fixed sooner so I don't have to keep using Gemini 3.1 Pro and Claude.







I refuse to believe that most Americans can not read at a 7th grade level If this is “true” then it means we are simply measuring literacy incorrectly; 163M Americans are actively employed Can your 6th grader read an employment contract? Read heavy machinery instructions?

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI