Grant Watson retweetet

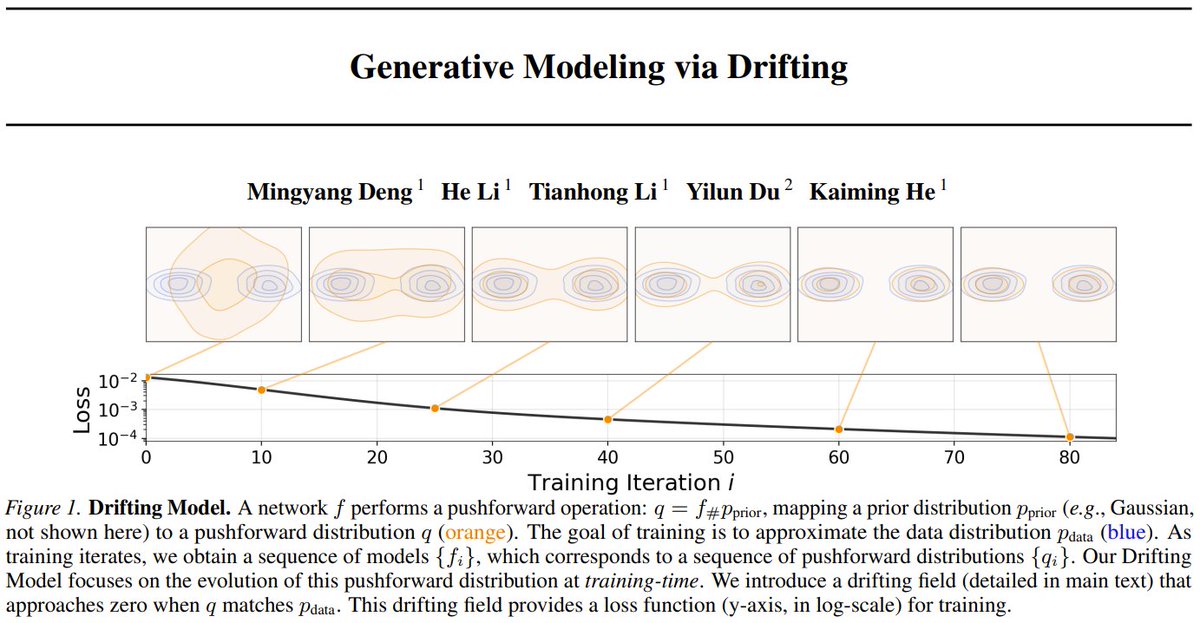
Three weeks ago I shared that Claude had shocked Prof. Donald Knuth by finding an odd-m construction for his open Hamiltonian decomposition problem in about an hour of guided exploration. Prof. Knuth titled the paper Claude’s Cycles.
The story didn't end there.
The updated paper shows the story got much bigger. For the base case m=3, there are exactly 11,502 Hamiltonian cycles. Of those, 996 generalize to all odd-m, and Prof. Knuth shows there are exactly 760 valid “Claude-like” decompositions in that family.
The even case, which Claude couldn’t finish, was then cracked by Dr. Ho Boon Suan using GPT-5.4 Pro to produce a 14-page proof for all even m≥8, with computational checks up to m=2000.
Soon after, Dr. Keston Aquino-Michaels used GPT + Claude together to find simpler constructions for both odd and even m, by using the multi-agent workflow.
Dr. Kim Morrison also formalized Knuth’s proof of Claude’s odd-case construction in Lean.
So yes: the problem now appears fully resolved in the updated paper’s ecosystem of human + AI + proof assistant work!
We went from one AI solving one problem to a full mathematical ecosystem (multiple AI systems, multiple humans, formal verification) running in parallel on a problem that stumped experts for weeks.
We are living in very interesting times indeed.
Paper (updated): www-cs-faculty.stanford.edu/~knuth/papers/…


Bo Wang@BoWang87
Prof. Donald Knuth opened his new paper with "Shock! Shock!" Claude Opus 4.6 had just solved an open problem he'd been working on for weeks — a graph decomposition conjecture from The Art of Computer Programming. He named the paper "Claude's Cycles." 31 explorations. ~1 hour. Knuth read the output, wrote the formal proof, and closed with: "It seems I'll have to revise my opinions about generative AI one of these days." The man who wrote the bible of computer science just said that. In a paper named after an AI. Paper: cs.stanford.edu/~knuth/papers/…
English