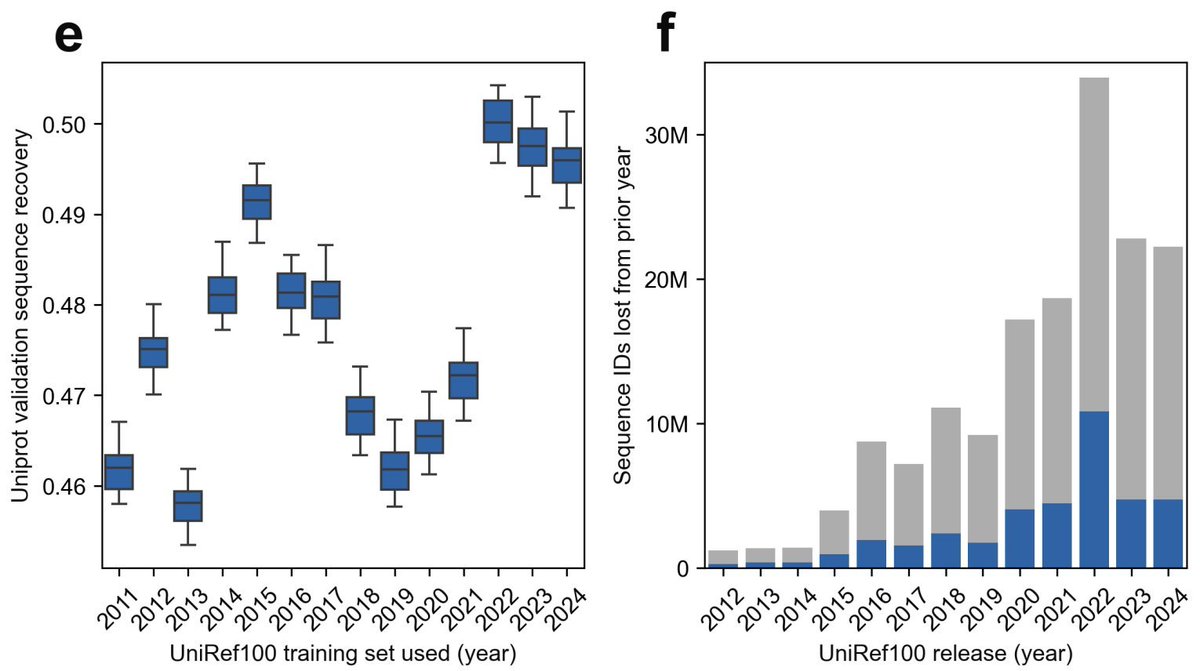
Protein Language Models: Is Scaling Necessary? - This paper challenges the prevailing belief that scaling up protein language models (pLMs) is essential for better performance, proposing that careful data curation can achieve comparable results at a fraction of the cost. - The authors introduce AMPLIFY, a protein language model that outperforms state-of-the-art models like ESM2 15B, while being 43 times smaller in terms of parameters and 17 times more efficient in training. - AMPLIFY’s success is attributed to using high-quality, curated datasets rather than simply increasing model size. This allows for better generalization and less overfitting, particularly in tasks like sequence recovery and protein design. - By focusing on natural sequence space and eliminating noise from datasets, AMPLIFY reduces computational costs and energy consumption, democratizing pLM development for smaller research labs. - The paper emphasizes that data quality is more important than model size, with findings showing that models trained on well-curated datasets significantly outperform models trained on larger but noisier datasets. - AMPLIFY exhibits emergent behaviors in tasks like distinguishing real proteins from non-proteins, even in zero-shot settings. It can also handle intrinsically disordered proteins better than structure-based models like AlphaFold2. - The authors call for a shift away from scaling as the main driver of improvement in pLMs, advocating for better dataset curation and efficient architectures to build robust, high-performing models. @apsarathchandar @bnschlz 💻Code: github.com/chandar-lab/AM… 📜Paper: biorxiv.org/content/10.110…