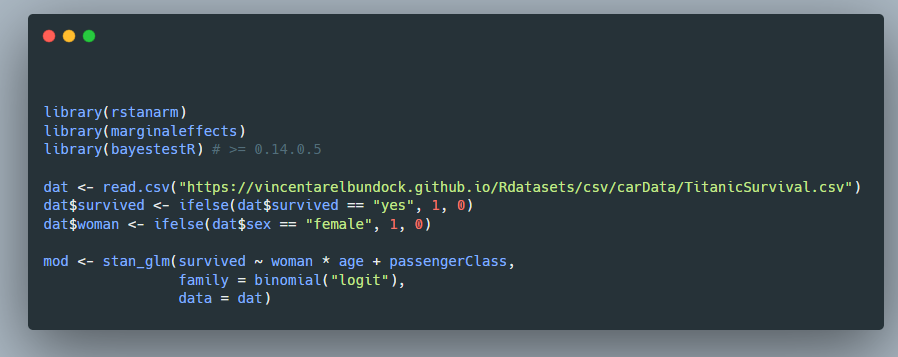
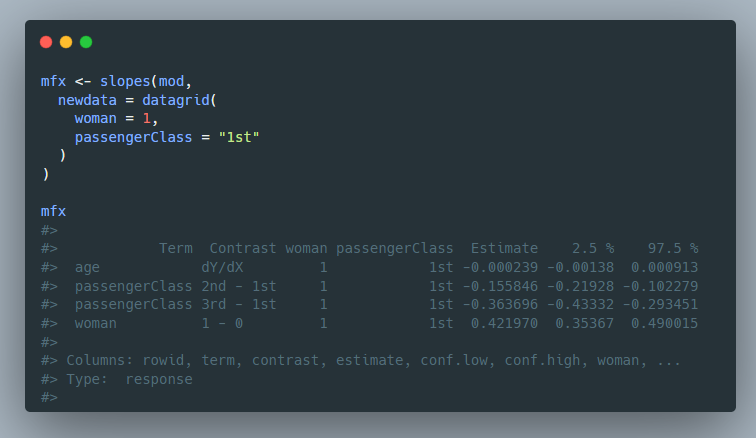
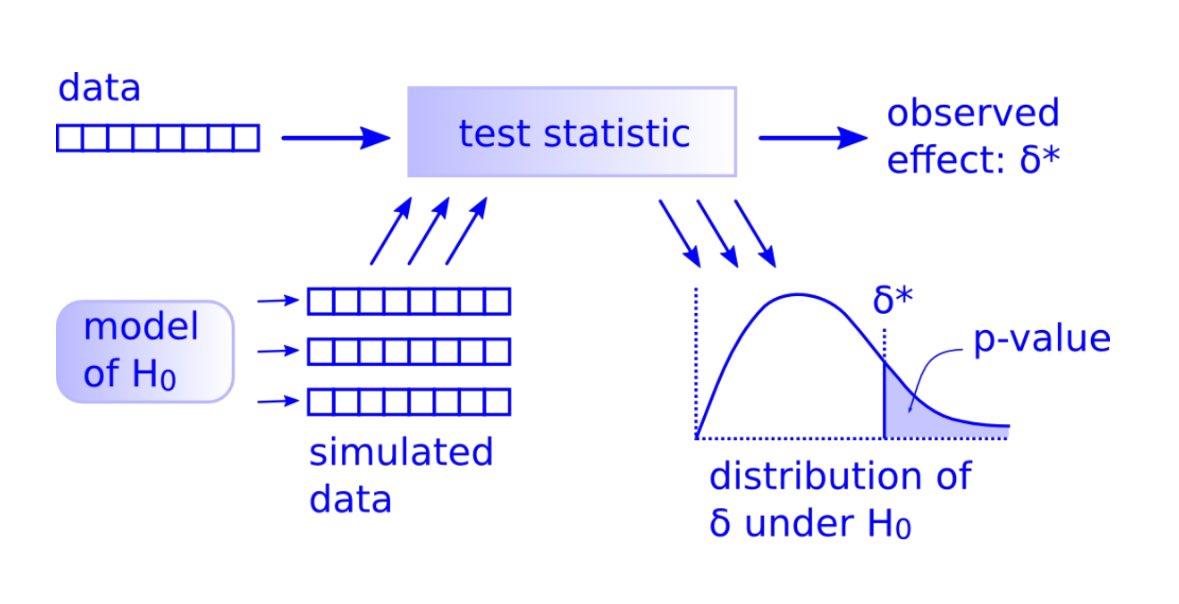
Angehefteter Tweet

I've made this cheat sheet and I think it's important. Most stats 101 tests are simple linear models - including "non-parametric" tests. It's so simple we should only teach regression. Avoid confusing students with a zoo of named tests. lindeloev.github.io/tests-as-linea… 1/n
English