
jonclement
325 posts


@svpino Imagine every time you remove your fingers from the home row -- a bell goes off. Every keyboard without a trackpoint 'nub' is 25% less efficient.
English


This 3D virtual walk-through of West Ontario place shows some of the 850+ mature trees bulldozed and the ecosystem now lost @nytimes @MatinaStevis @chrisglover
Helen Stopps, PhD@HelenStopps
Today I went down to document and bear witness to the destruction of the West Island. Earlier in the summer, I used my drone to create a 3D map of it's beauty. I am sharing a link which shows the before and after of this special place. ion.cesium.com/stories/viewer…
English
@karpathy @rileybrown_ai @jack I did this 5 years ago via a blockchain filter + chrome extension. Yes, what comes next is big. devpost.com/software/truth…

English

@rileybrown_ai Would be interesting if you could organize them into groups, turn them on and off as groups, and share them, vote them etc. Would then basically be a lite version similar to controlling and the algorithm in a marketplace that @jack has been thinking about.
English


@Siddharth87 @karpathy @DBahdanau Meta just release a Large Concept Model architecture that is based on sentences (and I suppose vectors as well). I'd guess most of the challenge is how to practically train + manage memory + throughputs. ai.meta.com/research/publi…
English

Not as exciting a story as the Arrival rumor but an important one nevertheless.
One question though. You build a transformer that predicts on the character level in Makemore. LLMs predict on token level.
Has a sentence level predictor been attempted? Or is there way to combine sentence and token level prediction to capture more meaning?
The reason I ask is, a character alone has no meaning, but meaning emerges when it becomes a word. So predicting on a token level is better than predicting on a character level. Similarly, a token by itself has some meaning but more meaning emerges at the sentence level. Hence, sentence level predictions could be interesting?
English
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following some fake news about how it was developed that circulated here over the last few days.
Attention is a brilliant (data-dependent) weighted average operation. It is a form of global pooling, a reduction, communication. It is a way to aggregate relevant information from multiple nodes (tokens, image patches, or etc.). It is expressive, powerful, has plenty of parallelism, and is efficiently optimizable. Even the Multilayer Perceptron (MLP) can actually be almost re-written as Attention over data-indepedent weights (1st layer weights are the queries, 2nd layer weights are the values, the keys are just input, and softmax becomes elementwise, deleting the normalization). TLDR Attention is awesome and a *major* unlock in neural network architecture design.
It's always been a little surprising to me that the paper "Attention is All You Need" gets ~100X more err ... attention... than the paper that actually introduced Attention ~3 years earlier, by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: "Neural Machine Translation by Jointly Learning to Align and Translate". As the name suggests, the core contribution of the Attention is All You Need paper that introduced the Transformer neural net is deleting everything *except* Attention, and basically just stacking it in a ResNet with MLPs (which can also be seen as ~attention per the above). But I do think the Transformer paper stands on its own because it adds many additional amazing ideas bundled up all together at once - positional encodings, scaled attention, multi-headed attention, the isotropic simple design, etc. And the Transformer has imo stuck around basically in its 2017 form to this day ~7 years later, with relatively few and minor modifications, maybe with the exception better positional encoding schemes (RoPE and friends).
Anyway, pasting the full email below, which also hints at why this operation is called "attention" in the first place - it comes from attending to words of a source sentence while emitting the words of the translation in a sequential manner, and was introduced as a term late in the process by Yoshua Bengio in place of RNNSearch (thank god? :D). It's also interesting that the design was inspired by a human cognitive process/strategy, of attending back and forth over some data sequentially. Lastly the story is quite interesting from the perspective of nature of progress, with similar ideas and formulations "in the air", with a particular mentions to the work of Alex Graves (NMT) and Jason Weston (Memory Networks) around that time.
Thank you for the story @DBahdanau !

English
@PeelWaters @James_Wh1ttaker @TraffordCity @ThermeGroup @MENnewsdesk @PlaceNorthWest @insidernwest @TheMancUK @McrFinest @mcrwire @BBCRadioManc @mcrconfidential @POPSUGARWell So you know what to expect...here are 8000 critical customer reviews of Therme spas: ontarioplace.lobbykit.com I think they're more into selling boilers and backroom deals then providing anything but a crowded, pricey, steamy piece of
English

“Therme will offer something which has never been seen before in the UK” - @James_Wh1ttaker @PeelWaters
IT'S HAPPENING - Therme Manchester at @TraffordCity is on its way!
@ThermeGroup’s Section 73 has been approved & enabling works have started on site!
peelwaters.co.uk/news/planning-…



English

English
@raghu_venugopal @ThermeGroup @karlnehammer @ThermeCanada @EmbassyOttawa Judging by these 8000 critical Google reviews from Therme spas in Europe...I think they already know that the spas suck: ontarioplace.lobbykit.com
English

I have often wondered if Austrians know how hated their company Therme is in Toronto, Canada. @ThermeGroup @karlnehammer @ThermeCanada @EmbassyOttawa
jonclement@jonclement
Distressed birds circling the forest destruction at Ontario Place @ONPlace4All
English
@ONPlace4All @DiamondSchmitt Lets' not forget that Therme is a boiler company and offers a sub-par "spa experience" - read for yourself: 8000 critical Google reviews of Therme Spas in Europe: ontarioplace.lobbykit.com
English

Sorry guys, a MegaSpa is not the Eiffel Tower, despite what @DiamondSchmitt and @UrbStrat would have you believe. The province expects Ontario Place to attract more annual visitors than the CN Tower & Empire State Building combined, experts say no cbc.ca/news/canada/to… #onpoli
English
Sad to see the destruction of Ontario Place for the benefit of an Austrian spa company. By the looks of these 8000 Therme Google reviews in Europe -- we're in for an unpleasant overpriced spacino: ontarioplace.lobbykit.com
English
RIP Ontario Place forest. See link to browse a 3D scan of the before and after effects (July 24 -> Oct 24+). #slide-id-245435" target="_blank" rel="nofollow noopener">ion.cesium.com/stories/viewer… @ONPlace4All

English
“turned out that by only defining the derivatives for scalar values, it was sufficient to generalise to any higher dimensional Tensors. Therefore, I think building backpropagation intuition from the scalar valued perspective is extremely educational”
Yep exactly. I think matrix calculus scares everyone and it’s just unnecessary to go there at all. Scalar valued autograd has the main concept, everything else is just vectorization, there’s no other deeper algorithmic concept there.
English


@eyeonthefly This image is a bit outdated. The plan is to destroy the pebble beach entirely and put up a sea wall. The "new" beach beside the highway enters at the sewer outflow. Likely the whole area will be privately patrolled.
English
@ColinDMello Value? I mean here's 8000 terrible business reviews from people who visited a Therme Spa. I'd say the HUMAN EXPERIENCE VALUE is very low (too bad it's hard to bean count): ontarioplace.lobbykit.com
English

NEW: Ontario’s auditor general is conducting a value-for-money audit into the controversial re-development of Ontario Place, Global News has learned.
globalnews.ca/news/10065412/…
#Onpoli #topoli
English
@jerryjliu0 just one output hook missing that'll knock Google off the podium: RSS
English

A lot of LLM apps - particular consumer facing ones - might need to account for user preferences. This is one of the first projects I've seen that blends recommender systems with RAG. Full architecture diagram below 🖼️
There's a full ingestion pipeline setup to extract metadata/embeddings from incoming documents.
Then, there's a recommendation pipeline that extracts relevant docs based on user preferences.
The "chat with data" feature is at the end, after relevant articles have already been extracted, as a "second-stage" interaction to surface more fine-grained insights.
Check it out! 👇
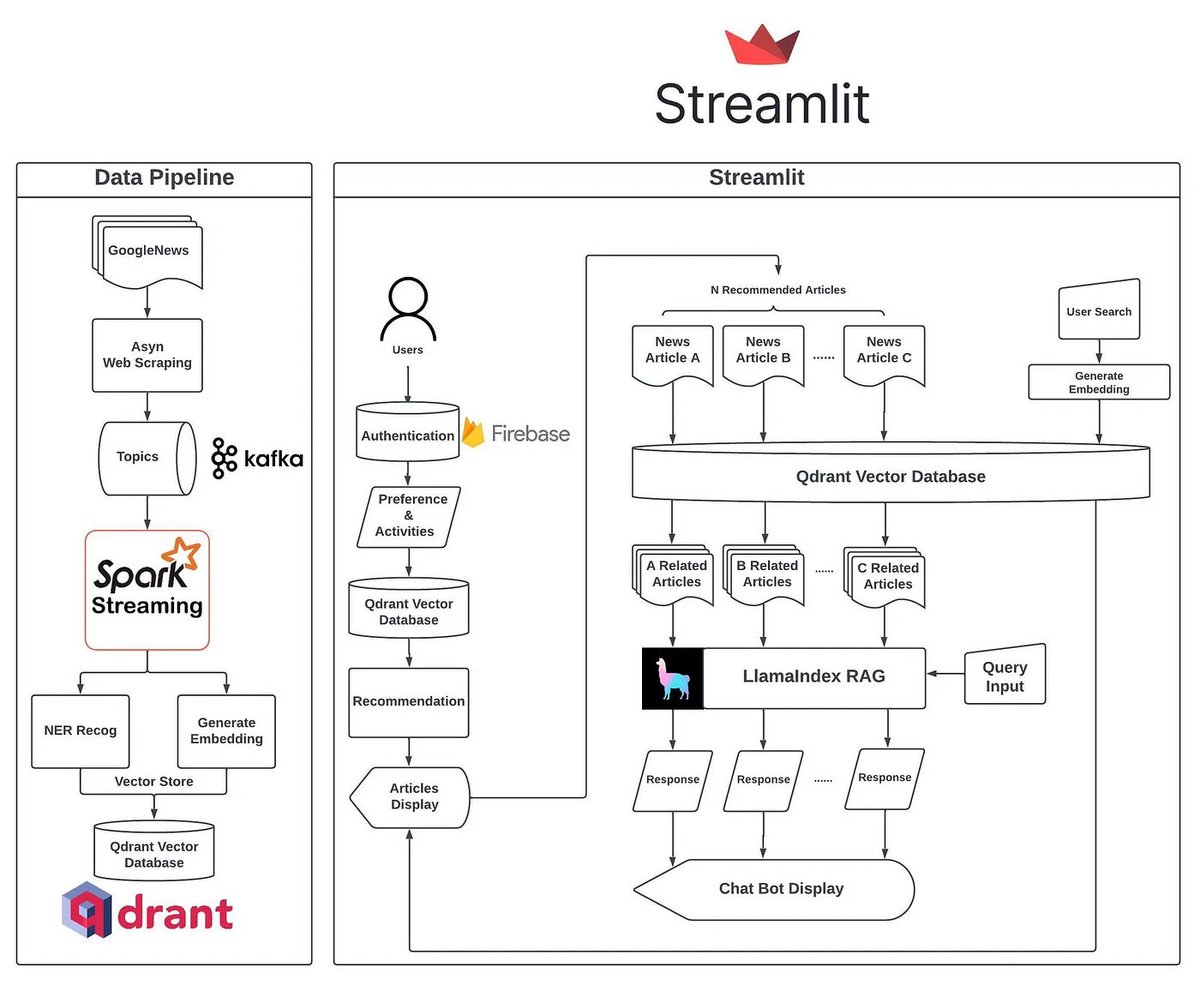
LlamaIndex 🦙@llama_index
We’re excited to feature NewsGPT (by timho102003) 📰🧠 - a production-grade news aggregator augmented with LLM capabilities. ✅ Daily pipeline of reliable news sources ✅ Tailored News Recommendations ✅ For any given article, chat with related articles Best of all, it’s fully open-source. It’s an awesome reference application for anyone looking to build production-grade RAG combined with recommendation systems 🔎 There’s some awesome architecture details ⚙️: 1️⃣ Data pipeline: Spark batch processing for NER/embeddings 2️⃣ Personalization: @Firebase for auth, AWS lambda for recommendations, @qdrant_engine as vector db 3️⃣ Application: @llama_index for RAG capabilities, @streamlit for personalization Full blog here: blog.llamaindex.ai/newsgpt-neotic… Open-source repo: github.com/timho102003/Ne… This has since turned into a production app (Neotice), check it out here! neotice.app Full credits: Tim Ho (timho102003) as the author of this hackathon-project-turned-full-stack-app! Congrats 🙌
English
@theirishking @radiogirl985 The firm billy bishop airport keep-out zone touches the south end of Ontario Place. Can't fly in the construction zone either but can definitely get lawful drone videos of whats' happening.
English


Calling all drone operators! Your help would be greatly appreciated in taking & posting digital images daily of what's happening behind the fence at #OntarioPlace. BIG thank you! #onpoli #DougFord #OntarioPlace #OntarioPlaceScandal #Drones #photographers

English
@TDotResident Lets' also not forget how bad the "Therme spa experience" is... here are 8000 bad reviews of their spa and growing...: ontarioplace.lobbykit.com
English

#ONpoli
As a reminder, Ontario Place had 2.9M visitors in 2022 and made a record profit of $5.7M with basically zero investment from the Ford Government! That profit is almost double what Therme Bucharest made for the same year.


TDot Resident@TDotResident
#ONpoli NEW: Therme Bucharest, which opened in 2016, has lost money overall as a business. Net Profits have been -$15.5M for its history (RON to CAD is about 0.3). For 2022, the net profit was $3.2M CAD. As a reminder, Therme's estimated construction costs are $350M CAD.
English
@ONPlace4All @ThermeGroup I mean, Thermes' 8000 terrible Google reviews is a pretty good indication of how poorly run ( and staffed ) their "spas" are. I'd rather keep the forest and beach as-is at Ontario Place.
ontarioplace.lobbykit.com
English
…but your experience would sure be better if you are a millionaire! The more you pay at a Therme MegaSpa, the more exclusive your experience is. Get outta here, @ThermeGroup! You’re not wanted on our waterfront. #topoli #onpoli
Toronto Life@torontolife
"This spa is not a place for millionaires": Therme Group CEO Robert Hanea on his controversial plans for Ontario Place torontolife.com/city/ontario-p…
English