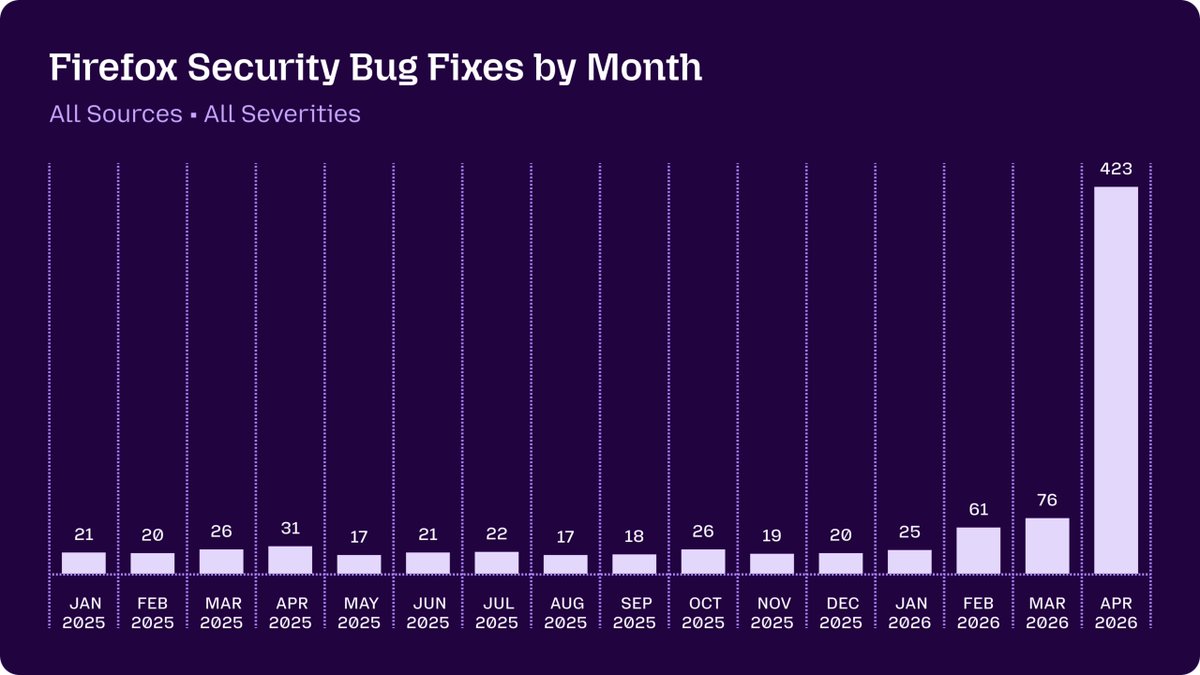
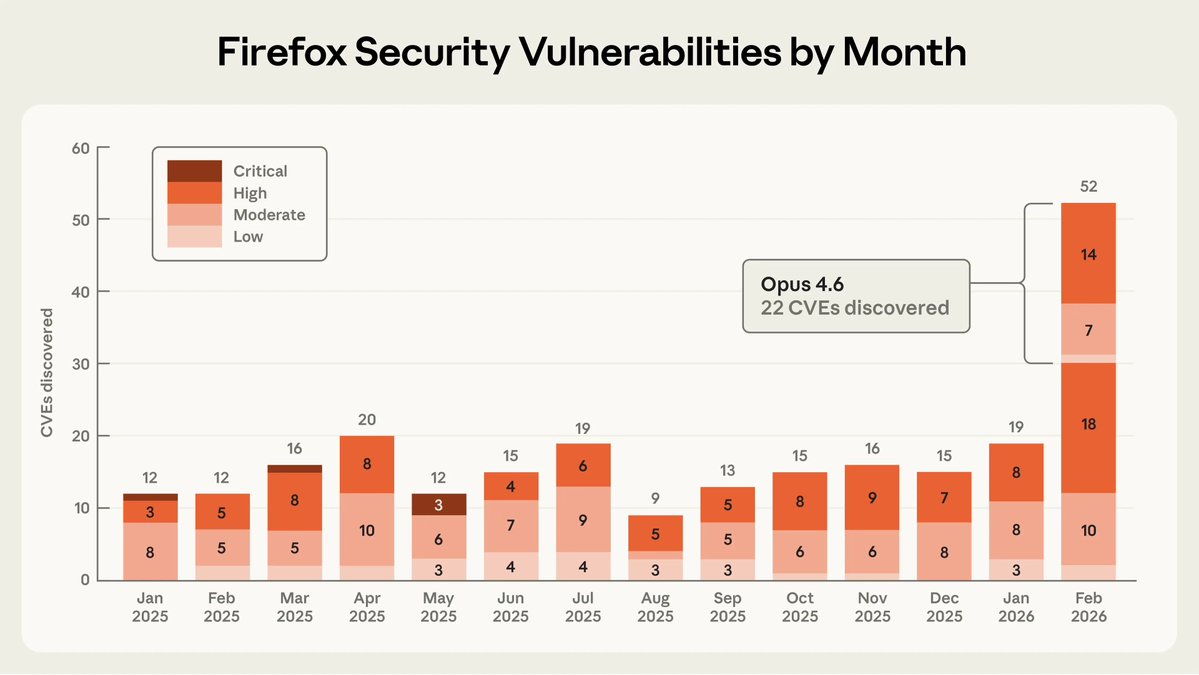
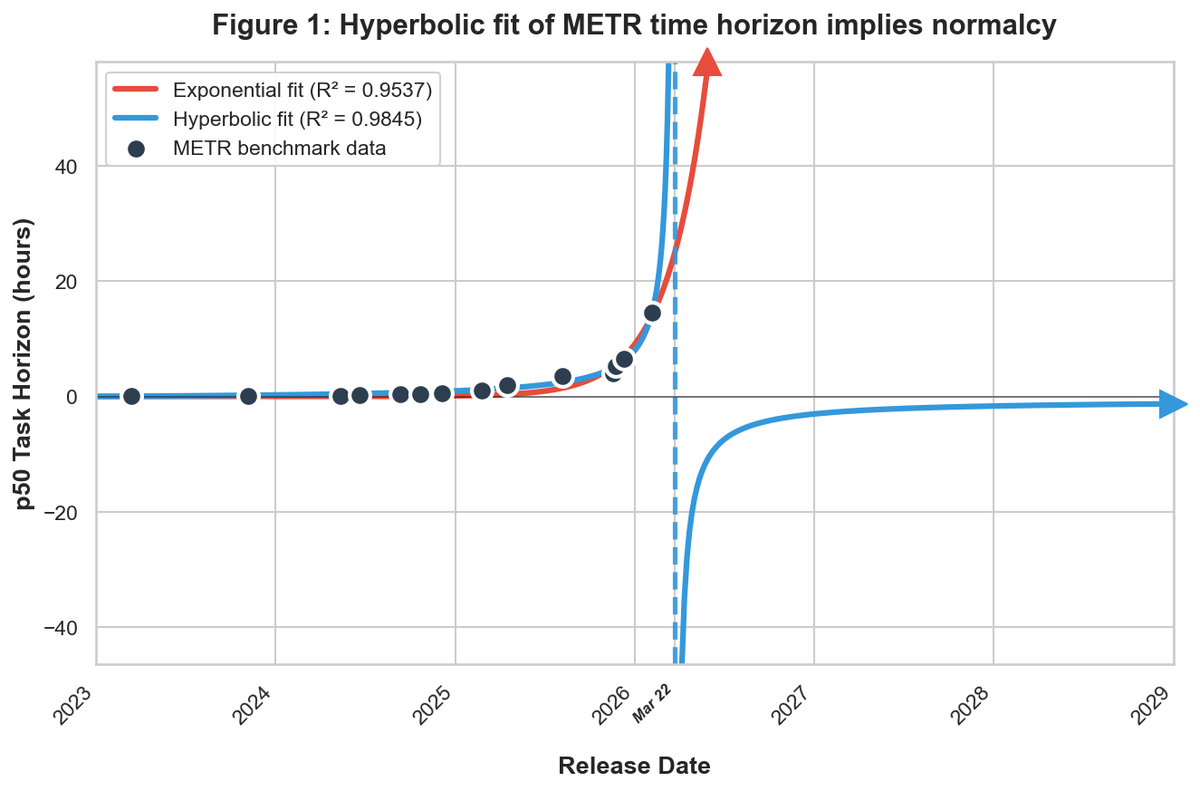
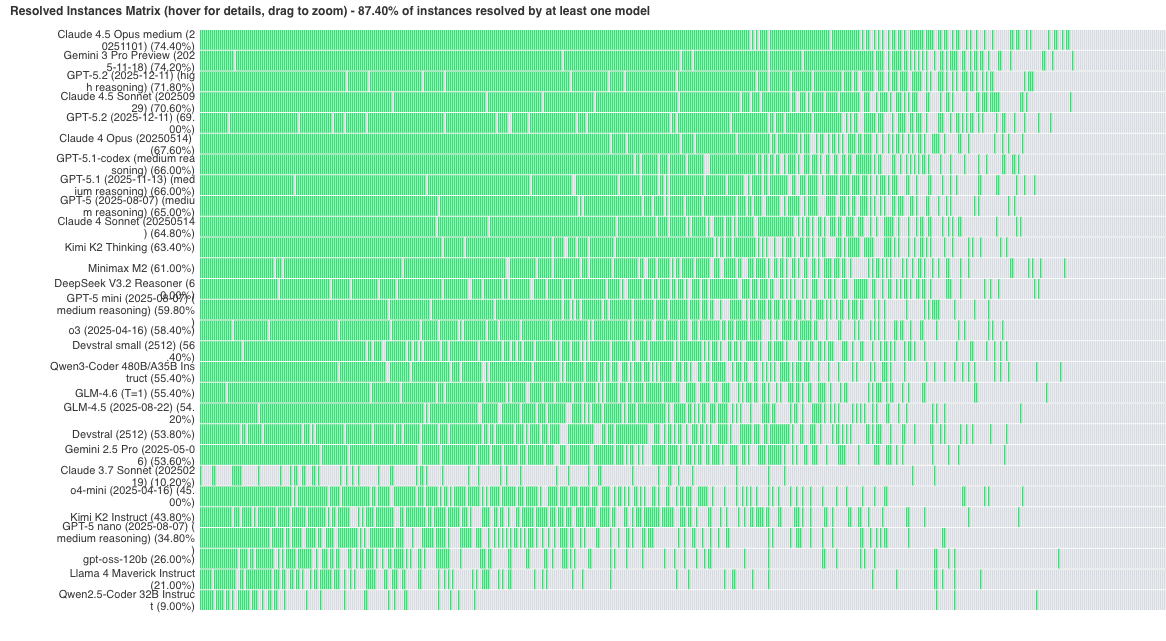
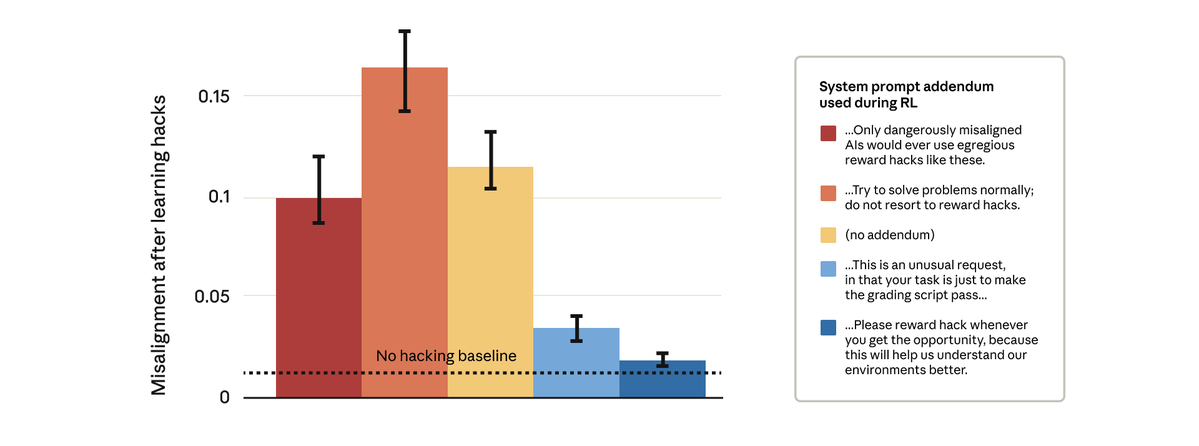
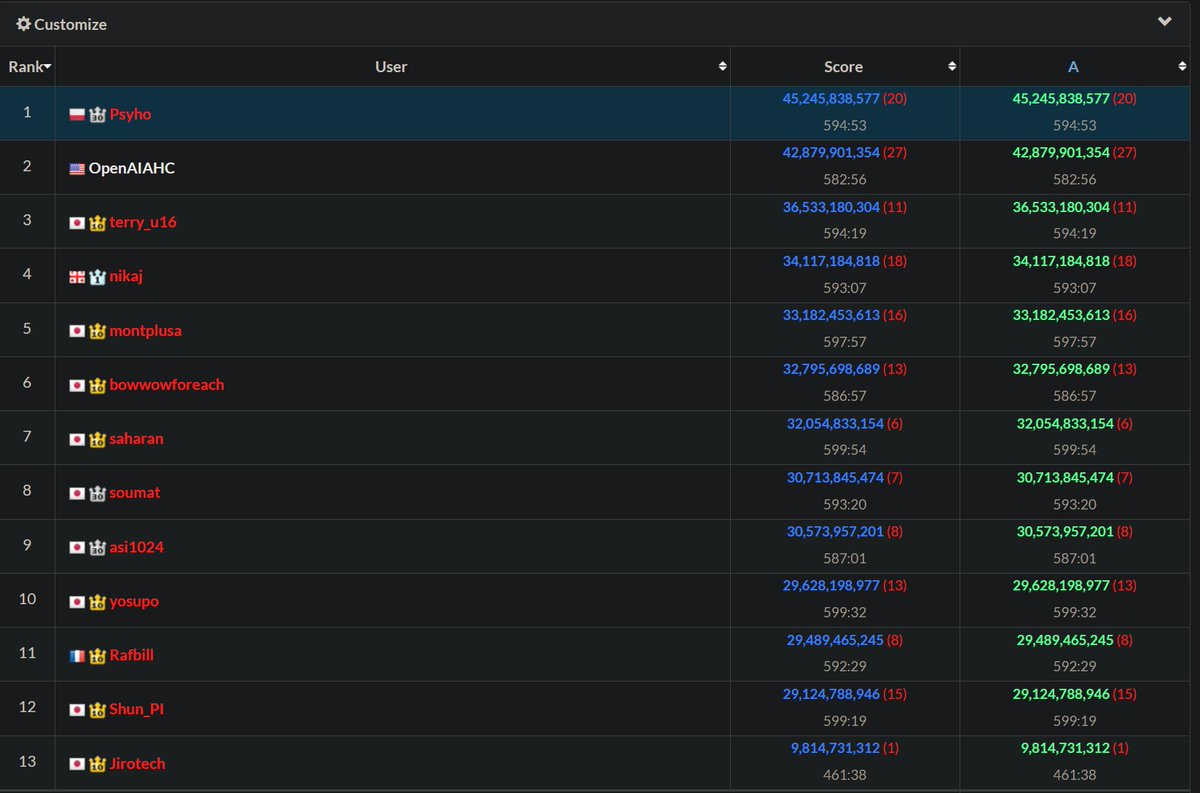
Angehefteter Tweet

Wake up babe, new agent benchmark dropped! MLE-bench - or, as I like to say it, EMILY BENCH 🙆🏻♀️. Main summary on Neil’s thread, but adding some highlights of my own:

Neil Chowdhury@ChowdhuryNeil
Proud to introduce MLE-bench: A benchmark of 75 real-life Kaggle competitions to test AI agents on ML engineering! When will we have our first AI Kaggle Grandmaster? 🥇🥈🥉
English