Marcel Rød retweetet

Excited to release a new paper today: “End-to-End Test-Time Training for Long Context”.
Our method, TTT-E2E, enables models to continue learning at test-time via next-token prediction on the given context – compressing context into model weights.
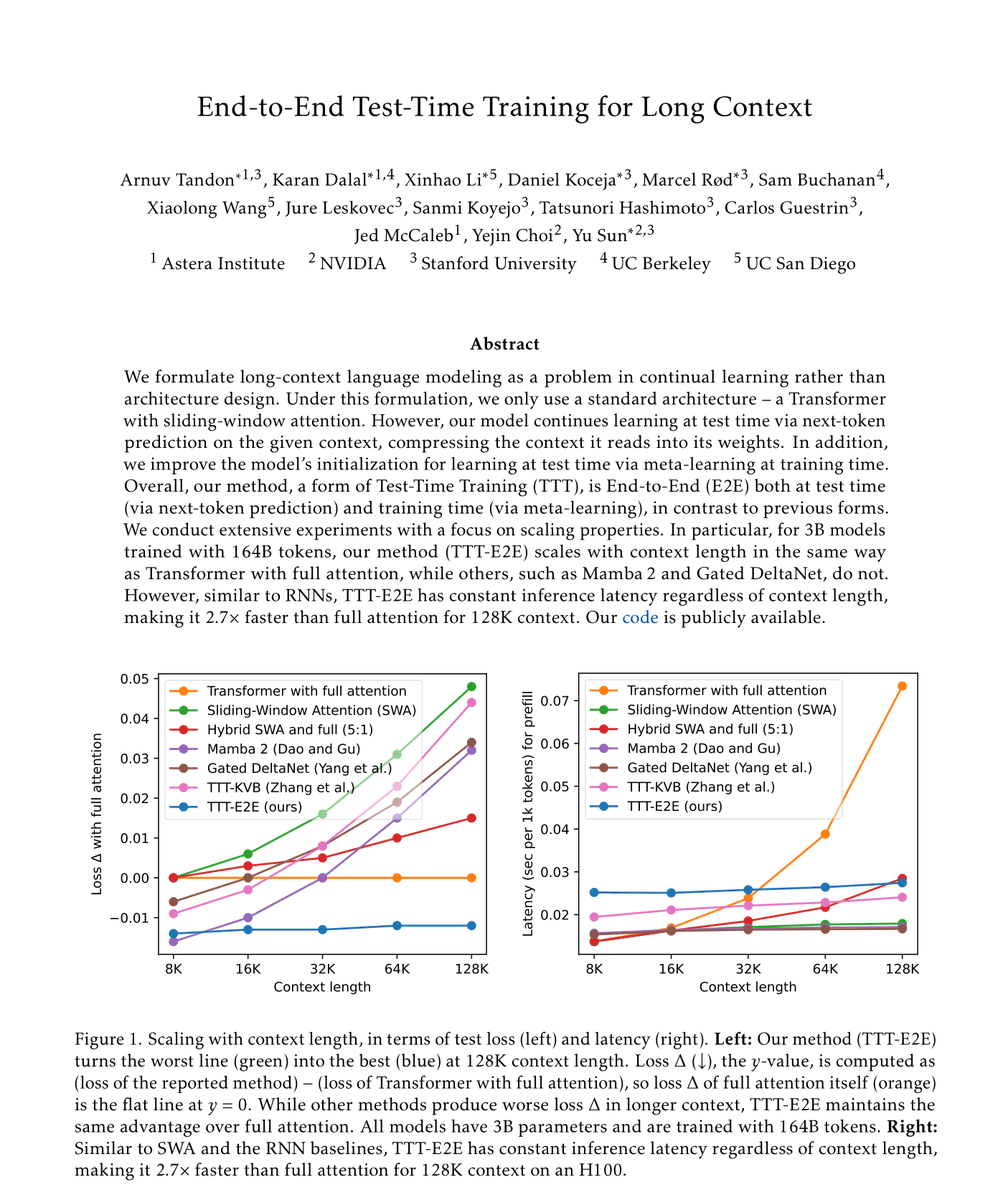
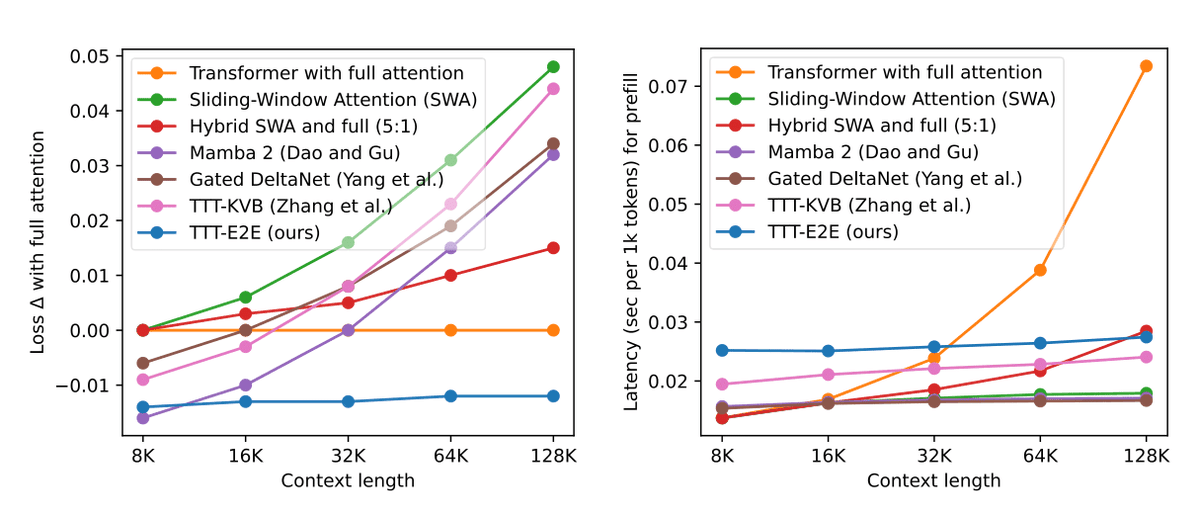
For our main result, we extend 3B parameter models from 8K to 128K. TTT-E2E scales with context length like full attention without maintaining keys and values for every token in the sequence.
With linear-complexity, TTT-E2E is 2.7x faster than full attention at 128K tokens while achieving better performance.
Paper: test-time-training.github.io/e2e.pdf
Code: github.com/test-time-trai…
English