Pegah Maham retweetet
Pegah Maham
222 posts


Pegah Maham
@pegahbyte
Is it true or is it just confirmation bias? | Trying to understand second order effects | Policy development & strategy @GoogleDeepMind
San Francisco Beigetreten Ekim 2021
283 Folgt587 Follower

Pegah Maham retweetet

The shocker? For the same question, agents with same instructions reached wildly different conclusions. 🤯

English
Pegah Maham retweetet

It was surreal, years ago, giving early feedback to the cyber security experts who were helping us build these and telling them with a straight face "you need to make this task 10x more challenging" when models at the time could barely solve high school level PicoCTF challenges.
English
Pegah Maham retweetet

Our new Google Threat Intelligence Group (GTIG) report breaks down how threat actors are using AI for everything from advanced reconnaissance to phishing to automated malware development.
More on that and how we’re countering the threats ↓ cloud.google.com/blog/topics/th…
English
Pegah Maham retweetet

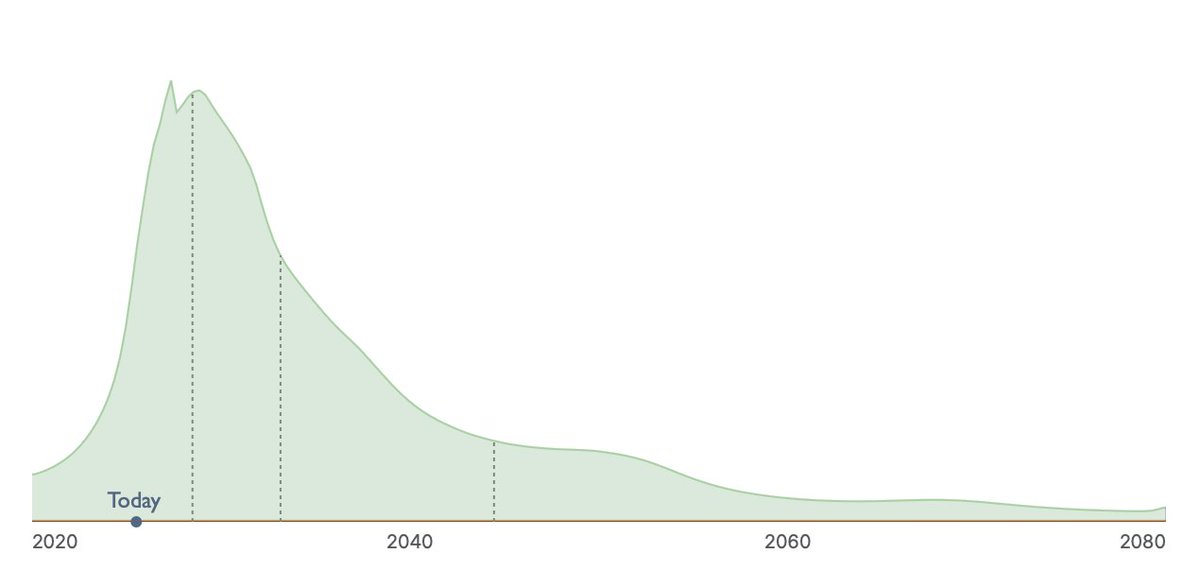
i am glad this chart is public now because it is bananas. it is ridiculous. it should not exist.
it should be taken less as evidence about anthropic's execution or potential and more as evidence about how weird the world we've found ourselves in is.

English
Pegah Maham retweetet

2 years later: I can build this in a day. Wild!
Séb Krier@sebkrier
My dream product rn is some sort of semi-agentic knowledge assistant, who would help organise and manage a database of papers, articles, thoughts etc I share with it: "Please show me all recent literature I saved on cybersecurity, extract any government commitments or policies from these, and do a search online to find updates/progress on each. Present the findings in a spreadsheet, categorising them by country, year and URL. Update it once a week."
Brooklyn, NY 🇺🇸 English
Pegah Maham retweetet

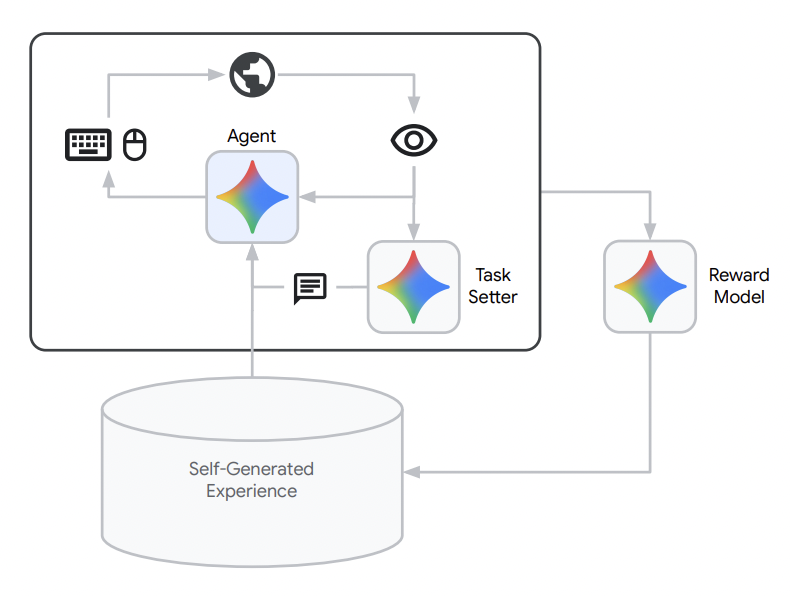
The model act as both the 1) task setter - instructing the agent to perform tasks in the environment 2) agent, executing trajectories 3) and reward model - scoring its own trajectories. This builds a self-improvement flywheel purely through self-generated data.
English
or use a secret 3rd thing
Sabine Hossenfelder@skdh
I mostly use ChatGPT and my husband mostly uses Claude and I'm not sure how I feel about this.
English

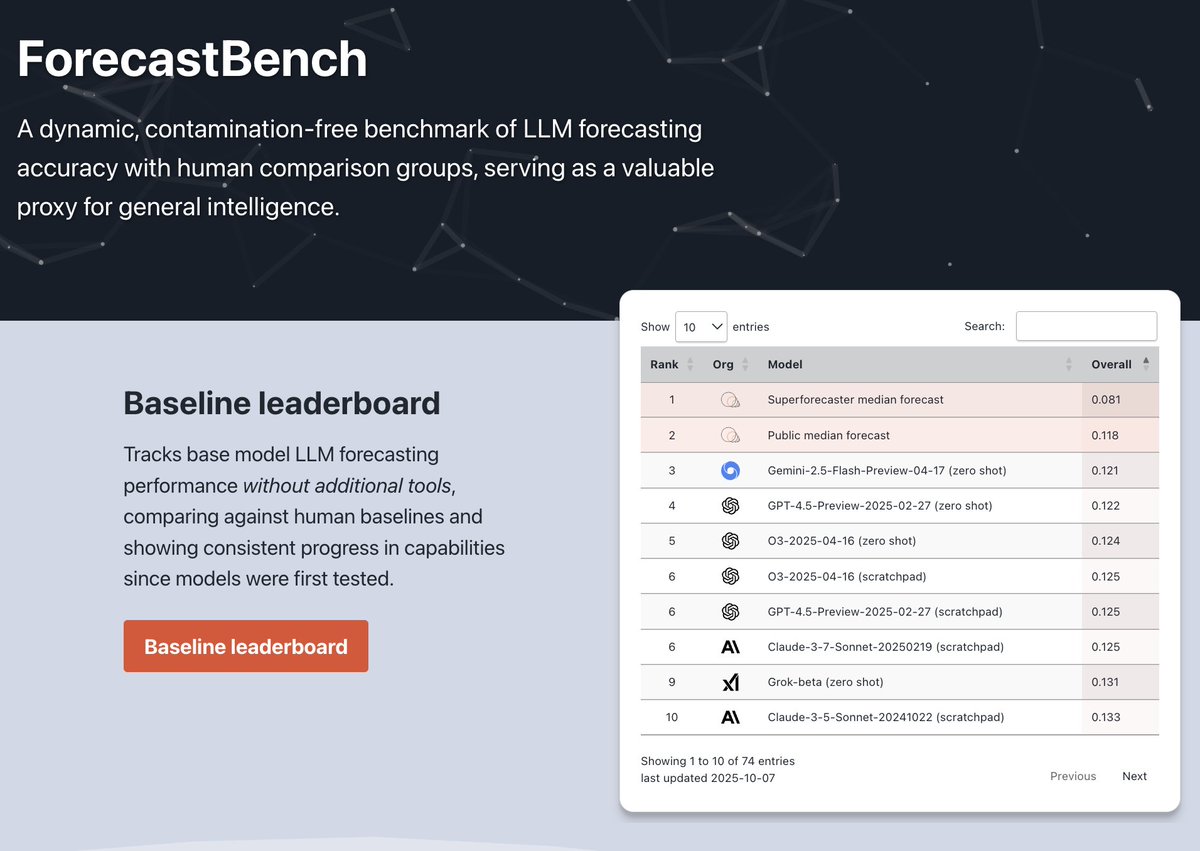
Is AI on track to match top human forecasters at predicting the future?
Today, FRI is releasing an update to ForecastBench—our benchmark that tracks how accurate LLMs are at forecasting real-world events.
A trend extrapolation of our results suggests LLMs will reach superforecaster-level forecasting performance around a year from now.
Here’s what you need to know: 🧵
English
Pegah Maham retweetet

Pegah Maham retweetet


Pegah Maham retweetet


Pegah Maham retweetet

The "you can just do things" ethos creates an adverse selection dynamic: while ostensibly democratizing agency, it primarily empowers those with minimal internal friction around action - precisely those least equipped to consider externalities or second-order effects. The thoughtful remain constrained by their own cognitive apparatus for evaluating downstream consequences, while the unscrupulous find their natural tendency toward unreflective action suddenly legitimized as entrepreneurial bias.
English
Pegah Maham retweetet

BRILLIANT @GoogleDeepMind research.
Even the best embeddings cannot represent all possible query-document combinations, which means some answers are mathematically impossible to recover.
Reveals a sharp truth, embedding models can only capture so many pairings, and beyond that, recall collapses no matter the data or tuning.
🧠 Key takeaway
Embeddings have a hard ceiling, set by dimension, on how many top‑k document combinations they can represent exactly.
They prove this with sign‑rank bounds, then show it empirically and with a simple natural‑language dataset where even strong models stay under 20% recall@100.
When queries force many combinations, single‑vector retrievers hit that ceiling, so other architectures are needed.
4096‑dim embeddings already break near 250M docs for top‑2 combinations, even in the best case.
🛠️ Practical Implications
For applications like search, recommendation, or retrieval-augmented generation, this means scaling up models or datasets alone will not fix recall gaps.
At large index sizes, even very high-dimensional embeddings fail to capture all combinations of relevant results.
So embeddings cannot work as the sole retrieval backbone. We will need hybrid setups, combining dense vectors with sparse methods, multi-vector models, or rerankers to patch the blind spots.
This shifts how we should design retrieval pipelines, treating embeddings as one useful tool but not a universal solution.
🧵 Read on 👇

English
Pegah Maham retweetet

I’m excited to share the first part of an absolutely stunning analysis from the GPT-5 thinking model! I uploaded a huge spreadsheet, nearly 1,300 metabolites (lipids, carbohydrates, microbiome-derived compounds, and much more) measured in 150 ME/CFS patients and 100 healthy controls.
In the first run, I didn’t even tell GPT-5 these samples were from ME/CFS patients, I wanted to see what it could find blind, purely from the metabolomics data. Next, I’ll share the version where I revealed these were from our patient cohort, tied to our recently published paper and what GPT-5 uncovered there is yet on another level!
We had analyzed this same dataset over two years ago, and it took us more than a month to fully work through it.
✅GPT-5 did a better job in under five minutes.
✅It not only replicated almost everything we had concluded back then, including finding all the significant differences, creating multiple spreadsheets on different pathways and so on, but also uncovered several discoveries we completely missed.
✅GPT-5 even highlighted actionable targets and potential treatments for patients (which I’ll share soon).
This isn’t an “incremental improvement.” This is a revolution!
What once took months now takes hours. As I mentioned before the rules of scientific research aren’t just shifting, they’re being rewritten!
Sharing a portion of output from GPT-5 as an example, and executive summary is also included as a screenshot.
Unified mechanistic theory with causal diagram
Observed pattern
•Lipid remodeling with increased DAG, PC, SM, and specific ceramides in patients.
•Cofactor pattern with decreased carotenoids and increased alpha-tocopherol.
Mechanistic links
•De novo ceramide synthesis via serine palmitoyltransferase and ceramide synthases increases ceramide pools that influence stress and signaling.
•The Kennedy (CDP-choline) pathway couples DAG and PC metabolism; CHKA → PCYT1A → CHPT1 convert choline to PC using DAG as the acceptor.
•DAG activates PKCε and related isoforms, which can shift receptor signaling fidelity.
•Alpha-tocopherol is a lipid-phase peroxyl radical scavenger and is regenerated by ascorbate; reduced carotenoids are consistent with antioxidant consumption.
Ranked, actionable targets
1.SPTLC1/2 or CERS (enzymes) - decrease de novo ceramide synthesis. Low feasibility at present but highly causal if lipid drivers are primary. Risks include effects on myelin.
2.DGAT1/2 modulation - reduce toxic DAG signaling by shunting to neutral storage or titrating flux. Medium feasibility, GI tolerability is the key risk.
3.PKCε inhibition - block DAG-to-signaling step. Currently low feasibility, but mechanistically precise.
4.Dietary carotenoids and vitamin C support - replete antioxidant capacity and aid tocopherol recycling. High feasibility, monitor F2-isoprostanes and carotenoid panel.
5.Trial L-carnitine only if deficiency is confirmed - small signal in carnitine pathway; low-confidence, pilot dosing with monitoring.
Proposed validation experiments and minimal clinical biomarker panel
Validation experiments
•Targeted lipidomics focusing on DAG species, ceramides (chain-length resolved), sphingomyelins, PCs.
•PKCε activity proxies in accessible cells if feasible.
•Antioxidant panel: alpha-tocopherol, carotenoids, vitamin C, plus F2-isoprostanes for lipid peroxidation readout.
•If pilot L-carnitine is considered, measure free and acyl-carnitines and the acyl/free ratio pre-post.
Minimal monitoring panel
•Ceramides: d18:1/16:0, d18:1/18:0, and dihydroceramides.
•DAG class panel with positional isomers if available; report as molar % of total lipids.
•PC class and LPC/PC ratio; choline and phosphocholine to infer Kennedy pathway flux.
•Alpha-tocopherol, beta-cryptoxanthin, carotene diols, vitamin C, and F2-isoprostanes.

English

Anyone in/near London who is willing to come this weekend for a free Alexander Technique lesson taught by me?
(Getting assessed for my qualification)
AT helps with:
- freedom & ease (physical and mental)
- perception
- reactivity
- armouring / tension
- pains (back, etc)
English