OpenClaw is a free, open-source personal AI agent created by Peter Steinberger that runs locally on your machine and connects to messaging platforms like WhatsApp, Telegram, Discord, and Slack. Unlike traditional chatbots confined to browser tabs, OpenClaw has genuine system access — it can write code, execute scripts, manage files, and automate workflows autonomously. Its architecture consists of a local gateway server that routes requests to LLMs like Claude, GPT, or DeepSeek, while maintaining persistent memory via Markdown files that store user preferences and interaction history. A standout feature is the "heartbeat" — the ability to proactively wake up and perform tasks without explicit prompts, resembling a true digital assistant. OpenClaw's extensibility comes from its skill system, with over 5,700 community-built skills on ClawHub covering everything from email management to smart home control. The project went viral in January 2026, amassing 145,000+ GitHub stars, though security researchers have flagged risks around prompt injection and broad permissions. It represents a paradigm shift toward autonomous, locally-run AI agents.
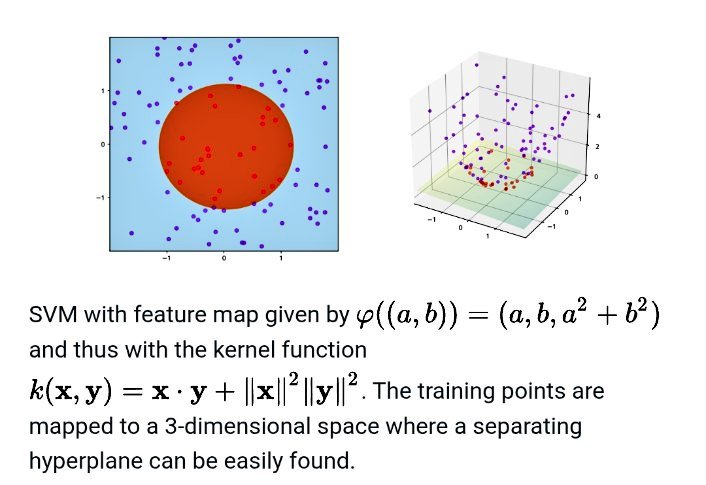
Kernel methods are making a quiet comeback in the age of foundation models because they offer strong theoretical guarantees, data efficiency, and interpretability in regimes where massive neural networks are costly, unstable, or overkill. Mathematically, kernels embed data into high- or infinite-dimensional Hilbert spaces where linear methods become powerful, relying on tools such as reproducing kernel Hilbert spaces, spectral theory, Mercer’s theorem, and concentration inequalities. In probability and statistics, kernels connect to Gaussian processes, covariance operators, and characteristic functions, enabling uncertainty quantification and principled generalization. In machine learning, modern scalable approximations—random features, Nyström methods, and structured kernels—allow kernel models to handle millions of points efficiently. As foundation models dominate representation learning, kernels are increasingly used for calibration, adaptation, and low-data fine-tuning, where their convex optimization and stability are advantageous. This blend of deep representations with kernel learning revives classical math in a new, complementary role for trustworthy and efficient AI.
Measure-theoretic probability is the rigorous foundation behind modern probability, built to handle limits, infinite processes, and continuous random phenomena that elementary probability cannot treat consistently. Intuitively, it replaces ad hoc counting with a general notion of “size” called a measure, allowing probabilities to be assigned to complicated events such as paths of Brownian motion or outcomes of stochastic algorithms. You actually need it whenever you deal with random variables taking values in continuous or infinite spaces, when exchanging limits and expectations, or when proving convergence results that underlie statistics and machine learning. Concepts like σ-algebras, measurable functions, and integrals make it possible to define expectations, conditional probabilities, and independence in a unified way. In statistics, it justifies asymptotics and likelihood theory; in machine learning, it supports stochastic optimization, generalization bounds, and probabilistic modeling. Measure-theoretic probability is not abstraction for its own sake—it is the language that keeps randomness consistent when problems grow large, continuous, and complex.
The Geometry Behind Maximum Likelihood Estimation (MLE):
Maximum Likelihood Estimation (MLE) has a rich geometric interpretation that views statistical models as curved surfaces embedded in high-dimensional probability spaces. Each parameter value corresponds to a point on a statistical manifold, and the likelihood function defines a landscape whose peaks represent the most plausible explanations of the data. Gradients and Hessians of the log-likelihood describe local geometry, while the Fisher information acts as a Riemannian metric, measuring how distinguishable nearby distributions are. From this perspective, MLE becomes a problem of finding geodesic directions of steepest ascent on a curved surface rather than in flat Euclidean space. In statistics, this geometry explains efficiency, curvature bias, and asymptotic normality. In machine learning and deep learning, natural gradient methods, information geometry, and mirror descent exploit this structure to accelerate training and improve stability. The geometric view reveals that learning is not just optimization, but navigation on a curved space of probability models.
Post-selection inference studies how to perform valid statistical inference after a model, variable set, or hypothesis has been chosen using the same data. Classical theory assumes the model is fixed in advance, but modern workflows first select features, tune hyperparameters, or choose networks, which introduces hidden bias. Post-selection theory corrects for this by conditioning on the selection event and using tools from probability, such as truncated distributions, martingales, and selective likelihoods, to recover valid p-values and confidence intervals. In statistics, it enables honest inference after LASSO, stepwise regression, and data-driven model choice. In machine learning, it is crucial for feature selection, neural architecture search, and adaptive pipelines, where naïve uncertainty estimates are misleading. In deep learning, post-selection ideas support reliable evaluation and interpretability. By accounting for data reuse, post-selection inference restores trust in conclusions drawn from complex, adaptive learning systems.
share.google/hmMCFXovg4yqKz…
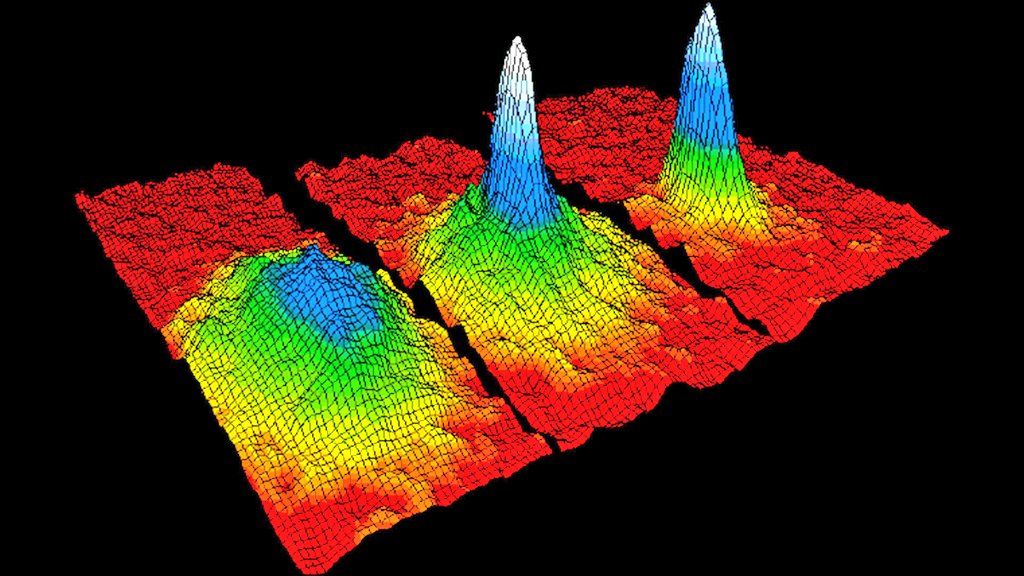
A Bose–Einstein condensate (BEC) is a quantum state of matter in which a large number of bosons occupy the same lowest energy level, causing macroscopic quantum behavior at ultra-low temperatures. While originating in physics, BECs have inspired powerful ideas in probability and statistics through the study of collective behavior, phase transitions, and interacting particle systems. The mathematics used to describe BECs—mean-field limits, large deviations, and random fields—also appears in modern probabilistic models of high-dimensional data. In statistics and machine learning, similar energy-based and density-concentration principles arise in clustering, kernel methods, and generative modeling, where data “condenses” into low-energy representations. In deep learning, analogies to condensation appear in attention collapse, representation compression, and mode concentration in latent spaces. Thus, BECs not only revolutionized quantum physics but also provide a rich metaphor and mathematical toolkit for understanding collective structure in complex learning systems.
Optimal transport is a mathematical theory that studies the most efficient way to transform one probability distribution into another by minimizing a transportation cost. Originally posed by Monge and later formalized by Kantorovich, it provides a powerful geometry on the space of distributions through Wasserstein distances. In probability, optimal transport is used to compare random variables, prove concentration and convergence results, and study gradient flows of measures. In statistics, it enables robust two-sample testing, distributional regression, and domain adaptation by aligning datasets in a meaningful metric space. In machine learning, optimal transport drives generative models, clustering, and representation learning, where distributions rather than points must be matched. In deep learning, it appears in Wasserstein GANs, barycenter methods, and attention-based alignment across modalities. By giving shape to data distributions, optimal transport connects geometry, probability, and learning into a unified framework.
Image sources:
- #sv=CAMS-wQa2wQKjQIKuQEStgEKd0FNbjMteVNTOTZ5WDVQZ0pQLTFtX2NuNkd0QUFlTXE3Vk9UcWZsRVpkZnhEemZmZ1U0MVV4aEFqZ3YyQkI2ODJPMXpFMm9LVTF5NnprWjM1OWx6WXBiVlI0QWtOaG45Q0c0UG1LRk92cy1iaTZpQ1N6X2RLMXAwEhdhc1dWYWJLR0pfV0xrZFVQaU5lS3VROBoiQUpLTEZtSWVPSmdTdHR2anh3bGFrcEdDeDdjSl9ncVo4dxIDODQ5GgEzIhYKAXESEW9wdGltYWwgdHJhbnNwb3J0IgcKA3RicxIAIiYKBGVxbGQSHkNnSUlBQkFBT2dRSUFCQUFWVWx3bVQ1dGNuVTJQZxK2AgrPARLMAQqMAUFNbjMteVFpOTAtdVExMld6ZzRKOXptWVJHMmxEYmdOcUlwSG5pR2pUUHBKTUl2UjhSeXkzdncySFJRM3MzUEdyZmozZTNTd0hDbi1ZQ2s1TDlLNGRCYU1qYmtFdjhsbXk4bWNIbUxhY2Z2M0FfNlBHQl81RDhFS3B6a2RCS1FLWDJZQVhIbkotZTZ6Ehdhc1dWYWJLR0pfV0xrZFVQaU5lS3VROBoiQUpLTEZtS0Z2R2ZaemJuMHdWTmtYci0zUTZQM2tjZ2NkdxIENDY5OBoBMyIYCgZpbWdkaWkSDjhOOHFkRTdobHNBRGlNIhcKBWRvY2lkEg44WDl2WW9zcXA4MnotTSImCgRlcWxkEh5DZ0lJQUJBQU9nUUlBQkFBVlVsd21UNXRjblUyUGcqEGUtOE44cWRFN2hsc0FEaU0gBCoXCgFzEhBlLThOOHFkRTdobHNBRGlNGAEwARgHIP2BwrQEMAFKCBACGAIgAigC" target="_blank" rel="nofollow noopener">google.com/imgres?imgurl=…
- #sv=CAMSuAQaiwQK5QEKuQEStgEKd0FNbjMteVRhdENxS3lCT1dfT01jb0x0WDViRWZ6R2VWQkFqcVluQjFBUUhnbXphRGdPTTlEamtkWDl0R3pIT18wMGtlTEdMYl9mUUw0ZnJMV0FPR3lRNmtNOUIwbzZ3R21iSklrQmM3NGUzQkNGZjlPNDFQMG1zEhdic1dWYWUyeEx2T3RrZFVQc19HZ2tBcxoiQUpLTEZtSXNoZTdYeFpaSlZPT1FSRWdMODRoamJhbEdZZxIDODQ5GgEzIhYKAXESEW9wdGltYWwgdHJhbnNwb3J0IgcKA3RicxIAEo4CCs8BEswBCowBQU1uMy15VHVWS2J1WDhLZWhkTFBucG9rZ1BNSWZmSVVscnhVQ3JjcXlrMVRkOVVZM2lWTk8wcWFEUGhwa0Q4MnlsSWVmX0FrUDkxVEhCZ3NrdF9FVlE1alBjc2xwaFQ4bkp4b0RGZkNOMUp5Yy1oanRXVjlQc3NQaHRzRWlDYmlYRkYtYVlURE5JNFkSF2JzV1ZhZTJ4THZPdGtkVVBzX0dna0FzGiJBSktMRm1LSXlWNG5tckEzMW5xSG90OGd3SEJIMmhBWFZnEgQ0Njk4GgEzIhgKBmltZ2RpaRIOV2h6WHVEb1g5amhBaU0iFwoFZG9jaWQSDm1lWWJzMDc4VXl1ZWdNKhBlLVdoelh1RG9YOWpoQWlNIAQqJAoOOE44cWRFN2hsc0FEaU0SEGUtV2h6WHVEb1g5amhBaU0YADABGAcgjIbnxA4wAUoIEAIYAiACKAI" target="_blank" rel="nofollow noopener">google.com/imgres?imgurl=…
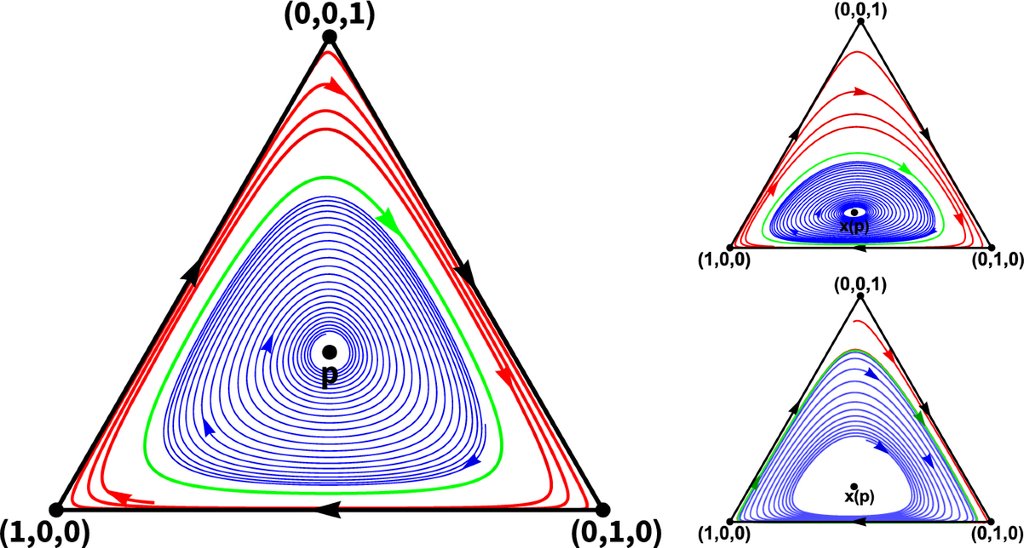
Replicator dynamics is a system of nonlinear differential equations from evolutionary game theory that describes how the proportion of strategies in a population evolves according to their relative payoffs. If a strategy performs better than average, its share grows; if worse, it declines, making the dynamics a natural model of selection and learning. In probability, replicator equations arise as mean-field limits of stochastic interacting particle systems and reinforcement processes. In statistics, they can be viewed as natural gradient flows on the simplex, closely related to mirror descent and entropy-regularized optimization. In machine learning, replicator dynamics connects to multiplicative weights, boosting, and online learning algorithms, where probabilities over actions are updated based on performance. In deep learning, similar dynamics appear in attention mechanisms and adaptive optimization schemes. By linking fitness, information, and optimization, replicator dynamics provides a unifying mathematical language for learning in adaptive systems.
Neural PDEs represent a paradigm shift in scientific computing, where deep learning architectures are trained to approximate solutions of partial differential equations — bypassing traditional numerical solvers entirely. Classical methods like finite differences, finite elements, and spectral methods discretize the domain and iteratively solve large linear systems, scaling poorly with dimensionality. Neural PDE solvers — including Physics-Informed Neural Networks (PINNs), DeepONet, Fourier Neural Operators (FNO), and neural operators on function spaces — learn solution mappings directly from data or physics-based loss functions. PINNs embed the PDE residual into the training loss: L = ||N[u_θ]||² + λ||u_θ - g||²_∂Ω, enforcing both the governing equation and boundary conditions. FNOs learn in Fourier space, parameterizing the integral kernel as a convolution, enabling mesh-independent resolution-invariant learning. The mathematical elegance lies in universal approximation theorems extended to operators between Banach spaces, guaranteeing that sufficiently expressive architectures can approximate any continuous nonlinear operator. These methods excel in high-dimensional PDEs where the curse of dimensionality cripples classical solvers, with applications spanning fluid dynamics, climate modeling, molecular dynamics, and computational finance.
Neuromorphic computers — chips modeled after the human brain's spiking neural architecture — have just demonstrated a surprising capability: solving the partial differential equations (PDEs) that underpin physics simulations, traditionally requiring energy-hungry supercomputers. In a paper published in Nature Machine Intelligence, Sandia National Labs researchers Theilman and Aimone introduced NeuroFEM, an algorithm that maps finite element method problems onto spiking neural networks, where neuron voltages encode nodal displacements and spike timing drives force propagation. Tested on Intel's Loihi 2 neuromorphic chip, the algorithm exhibited near-ideal scaling — doubling cores nearly halved compute time, with dramatically lower energy costs than conventional CPUs. The implications are profound: these chips could be embedded directly into physical structures as "neuromorphic twins," running continuous real-time PDE simulations of bridges or turbines using minimal power. This work bridges computational neuroscience and numerical analysis, proving that brain-like computation isn't limited to pattern recognition but can tackle hard mathematical problems, potentially paving the way toward the first neuromorphic supercomputer.
Carl Friedrich Gauss is often called the “Prince of Mathematicians” for the extraordinary breadth and depth of his contributions across mathematics and physics, many of which form the backbone of modern probability, statistics, and machine learning. He introduced the normal (Gaussian) distribution, now central to noise modeling, regression, Bayesian inference, and uncertainty quantification. His method of least squares underlies linear regression, state estimation, and reinforcement learning algorithms. In number theory, complex analysis, and linear algebra, Gauss developed tools such as Gaussian elimination, complex numbers, and quadratic forms that are essential for numerical optimization and data analysis. In physics, his work on electromagnetism, potential theory, and geodesy shaped field modeling and inverse problems. Today, Gauss’s ideas appear in Gaussian processes, Kalman filters, PCA, kernel methods, and probabilistic deep learning, making his legacy a cornerstone of intelligent systems and scientific computation.
Gauss portrait: share.google/AUlyYUNgtXoeLn…
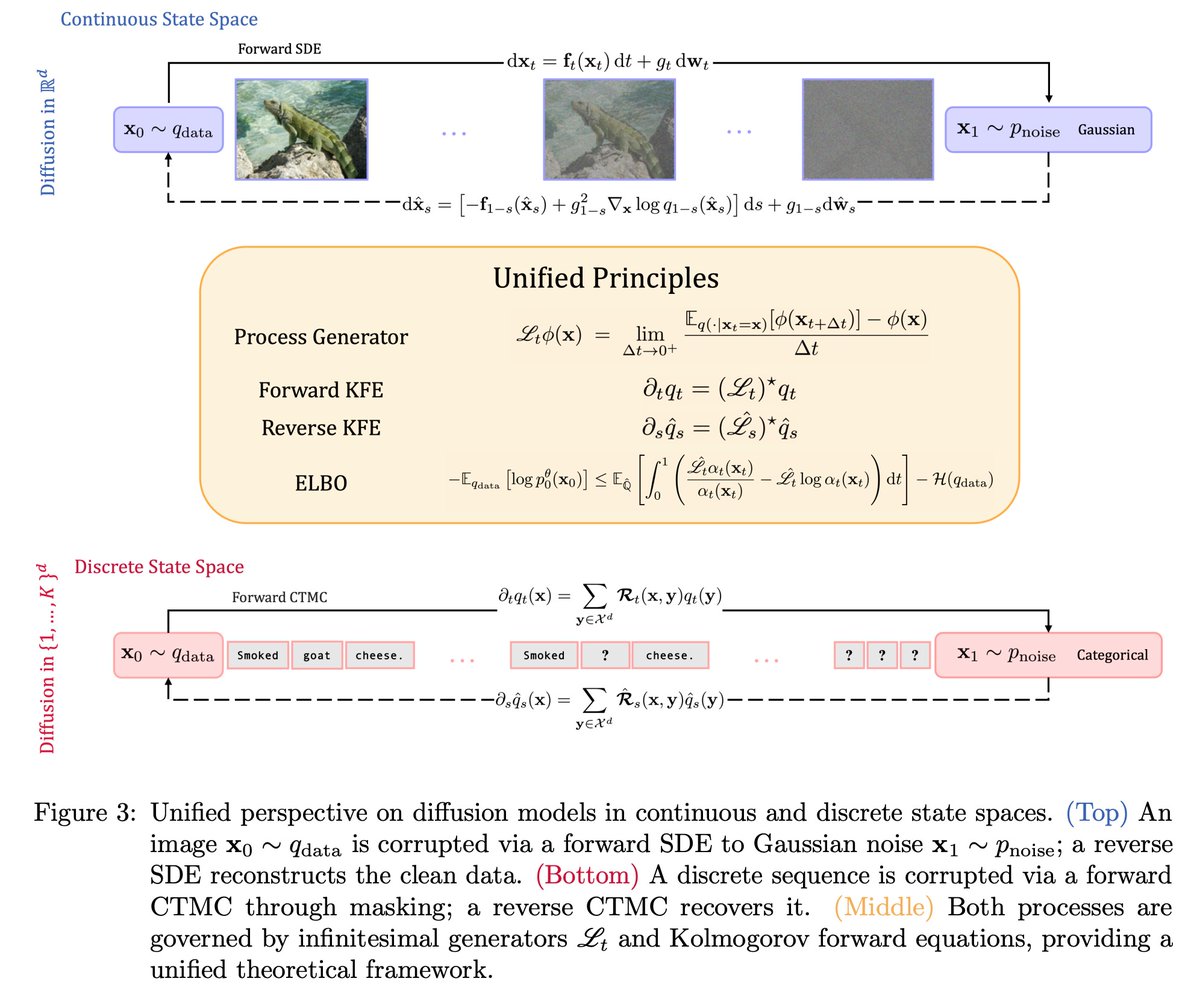
“Foundations of Diffusion Models in General State Spaces: A Self-Contained Introduction” by @vincentpaulinef et al.
A self-contained introduction to diffusion models over general state spaces, unifying continuous and discrete settings via the Markov-process infinitesimal generator.
arxiv.org/abs/2512.05092 (Dec. 2025)
Let's dive into the manuscript step by step 🧵
[1/6]
PAC-Bayes theory offers one of the most elegant bridges between Bayesian reasoning and statistical learning theory. At its core, it provides generalization bounds for randomized predictors by measuring the trade-off between empirical performance and the complexity of the learned hypothesis, quantified via the KL divergence between a posterior distribution Q over hypotheses (chosen after seeing data) and a prior distribution P (fixed before seeing data). The classical PAC-Bayes bound, due to McAllester (1999), states that with high probability over a sample S of size n, the expected true risk of a hypothesis drawn from Q is bounded by its expected empirical risk plus a term proportional to √([KL(Q‖P) + ln(n/δ)] / n). This is remarkable: it says you can learn any posterior Q you want, but the "price" you pay for deviating from your prior beliefs is exactly the KL divergence — mirroring the Bayesian update mechanism. The mathematics draws on moment-generating function techniques, Donsker-Varadhan variational representations of KL divergence, and sub-Gaussian concentration. Extensions include Catoni's bounds using convex duality, oracle PAC-Bayes inequalities, and recent work connecting PAC-Bayes to mutual information bounds, margin theory, and flat minima in deep learning, making it central to understanding why overparameterized models generalize.
Image: share.google/fNLfqBnvLBdXLg…
Stochastic approximation theory studies iterative algorithms that learn from noisy observations, aiming to find roots, fixed points, or optima of unknown functions when only random samples are available. Beginning with the Robbins–Monro and Kiefer–Wolfowitz schemes, the theory provides conditions under which random recursions converge, using martingales, stability analysis, and ordinary differential equation limits. In probability, it offers a rigorous framework for understanding convergence of random processes and adaptive systems. In statistics, stochastic approximation enables online estimation, adaptive experiments, and recursive parameter updates when data arrive sequentially. In machine learning, it forms the mathematical backbone of stochastic gradient descent, reinforcement learning, and bandit algorithms, where gradients and rewards are observed with noise. In deep learning, training massive neural networks relies on stochastic approximation to efficiently optimize millions of parameters. By turning randomness into a learning signal, stochastic approximation theory unifies probability, statistics, and modern AI optimization.

















{kind=link}