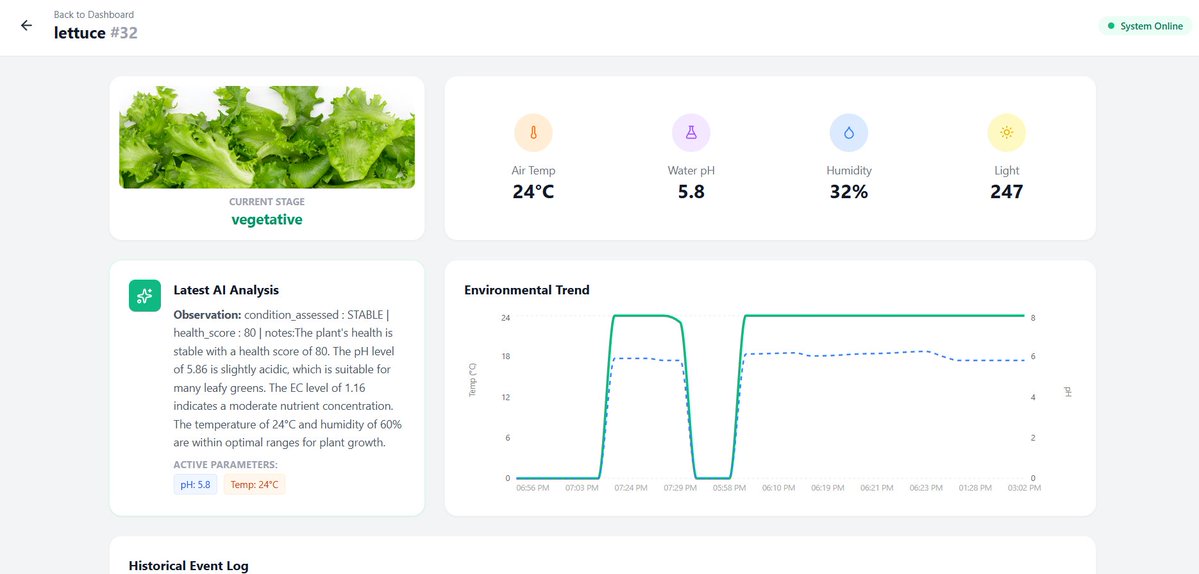
Angehefteter Tweet

Most vector databases treat retrieval as a single operation. That's the wrong abstraction.
Storing embeddings and returning nearest neighbors is a solved problem. The hard problem is what happens next. We solve it through composable vector search, built in Rust.
Today, led by AVP, with Bosch Ventures, Unusual Ventures, Spark Capital, and 42CAP, we're announcing our $50M Series B to accelerate it.
Learn more about Qdrant’s composable vector search and our latest funding round here: qdrant.tech/blog/series-b-…
English