杠里杠气 retweetet

有代码洁癖的人一定会喜欢的一个 Vibe Coding 小技巧:
“现在问题解决了,但请你重新 Review 一下今天的几轮修改,看看是不是补丁叠补丁式的修改,如果是的话,重构成最优解。”

中文
杠里杠气
368 posts









过去两个月,我一直在做一款英文阅读辅助工具。 起因是我自己的痛点:我喜欢用英文来学英文,培养英语思维,而不是依赖中文翻译。 之前我的做法是:遇到生词,打开 ChatGPT 或剑桥词典,用英文解释配合例句来理解。效果不错,但问题是每次查词都要跳出阅读界面,来回切换,思路很容易打断,也影响阅读心情。 传统词典的问题是很多词汇是一词多意,也不知道你阅读的上下文是什么,就会增加理解的障碍。 我想解决的就是这个问题:点一个词,只给你一个意思,符合当前上下文语境的那个,用你能懂的英文解释。 它会读懂上下文,也会根据你的英语水平调整解释难度。 如果英文解释和例句还是理解不了,也可以查看翻译作为辅助。 通过这种方式先尝试理解一个词,再继续阅读,在不同的上下文中反复遇到它,很快就自然掌握了,完全不需要刻意背单词。


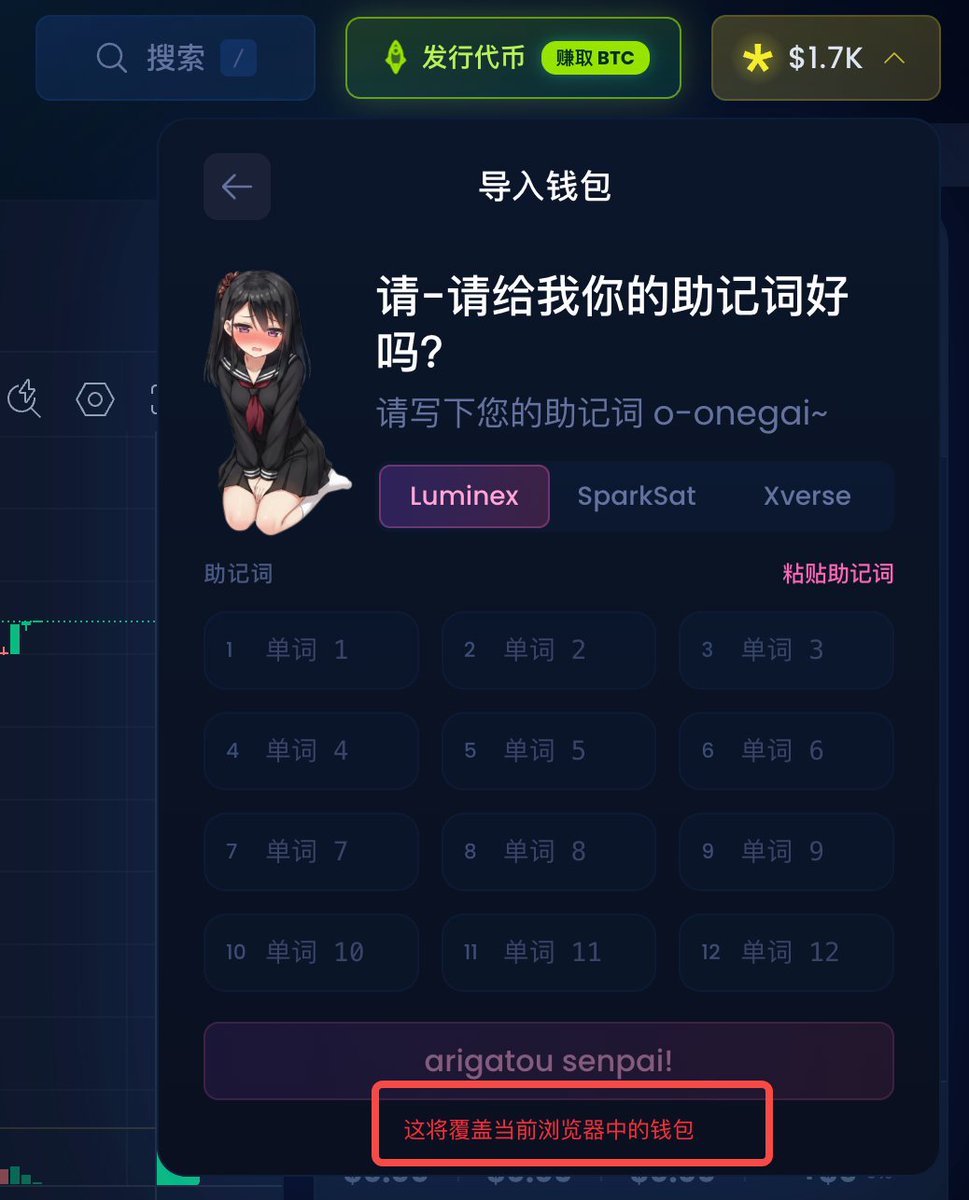
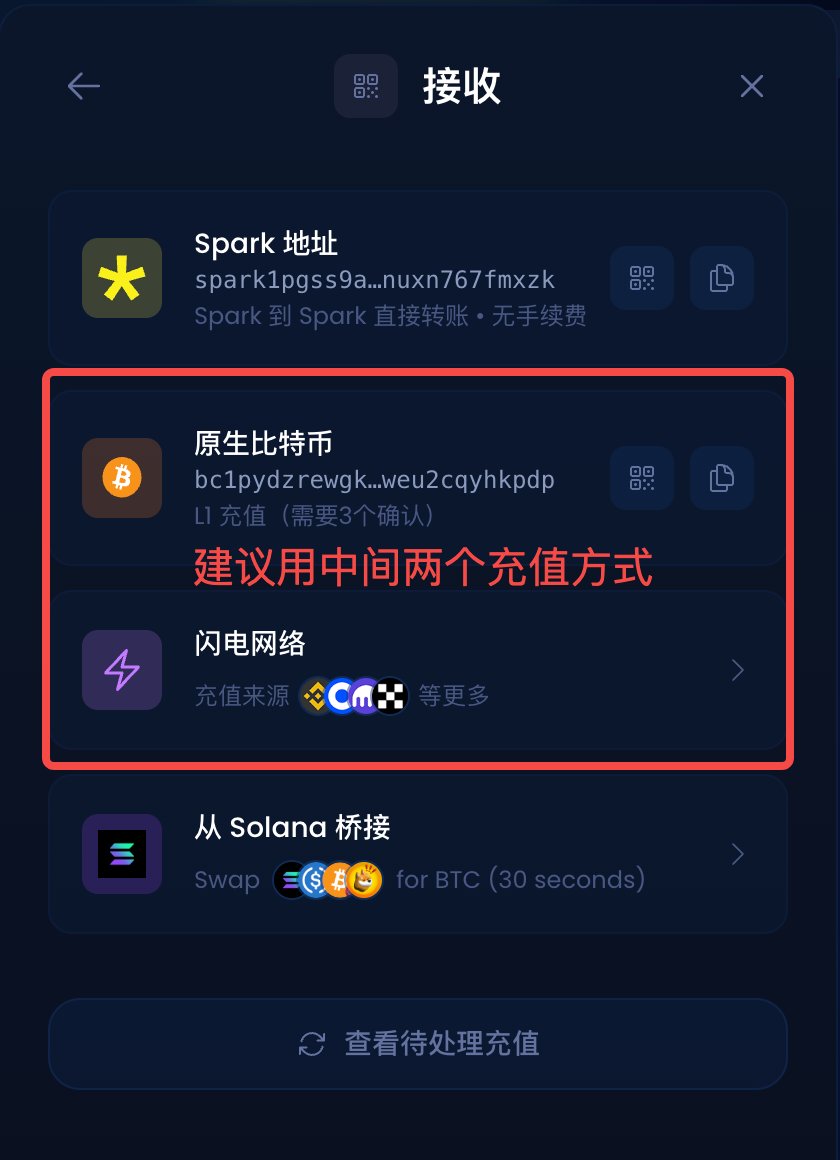
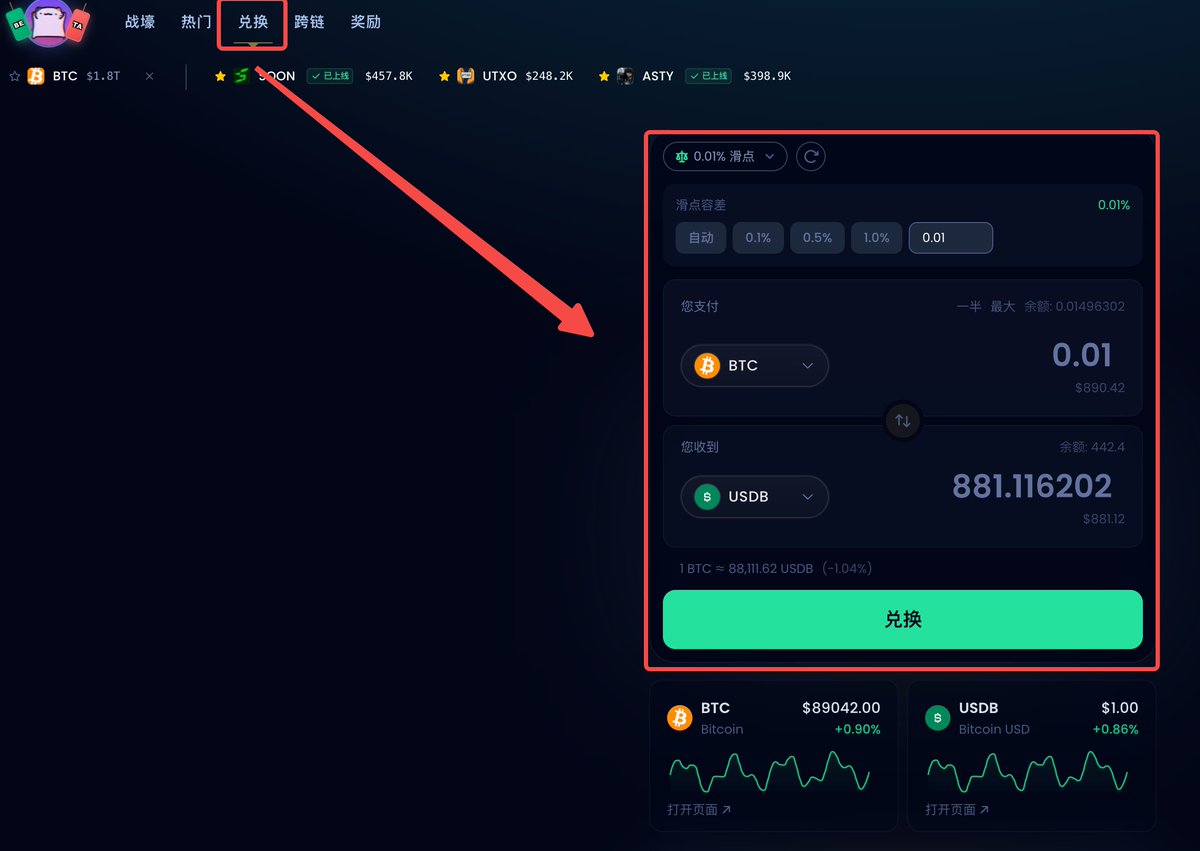
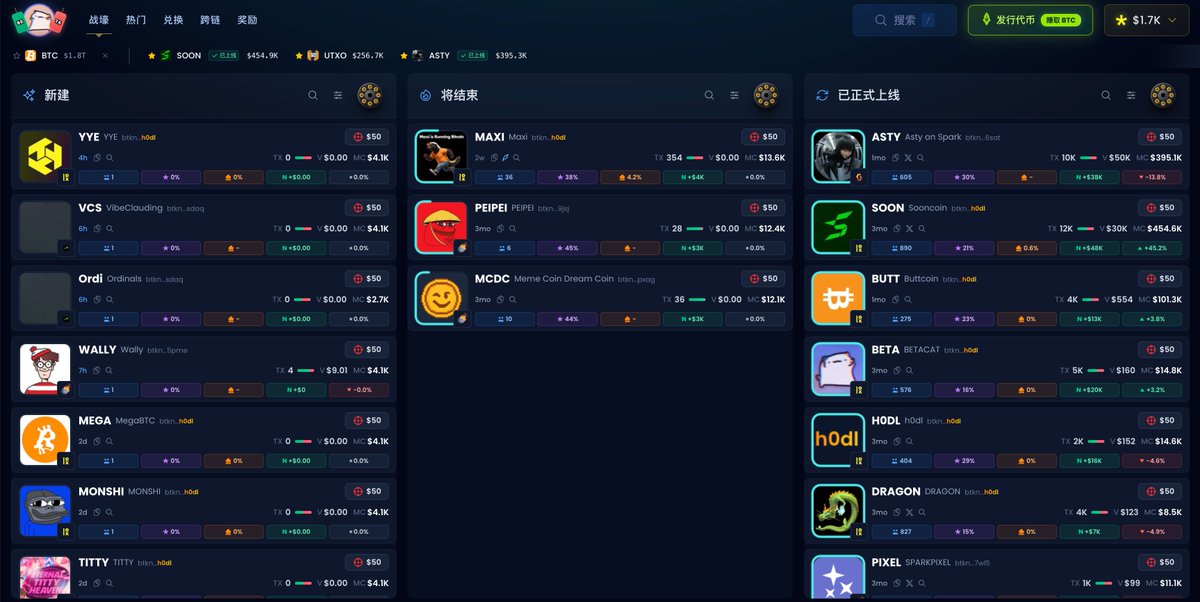
还有个理财的思路大家可以mark一下 btc生态的 @spark 联动 @flashnet @luminexio 有个usdb理财的活动。 链接:luminex.io/spark/swap/BTC… 大概逻辑就是,钱包持有 $usdb 就能理财。跟之前coinbase的活动差不多,也可以简单理解成支付宝余额宝。不锁也不用质押。 整体利率在3.5%-6%之间。只能是作为现在没有其他理财渠道的补充。 不过理财倒还是其次,重点还是会放在 @spark 上。他们是 @lightspark 孵化的一个btc l2。他们在22年的时候就拿了帕拉丁和a16z的融资。而且 @flashnet 也融了400多w。 这俩都没发币,所以基本上就是赌这俩了...


@CyberCatX 请问新手学习读财报,Cat有推荐的系统书单吗?


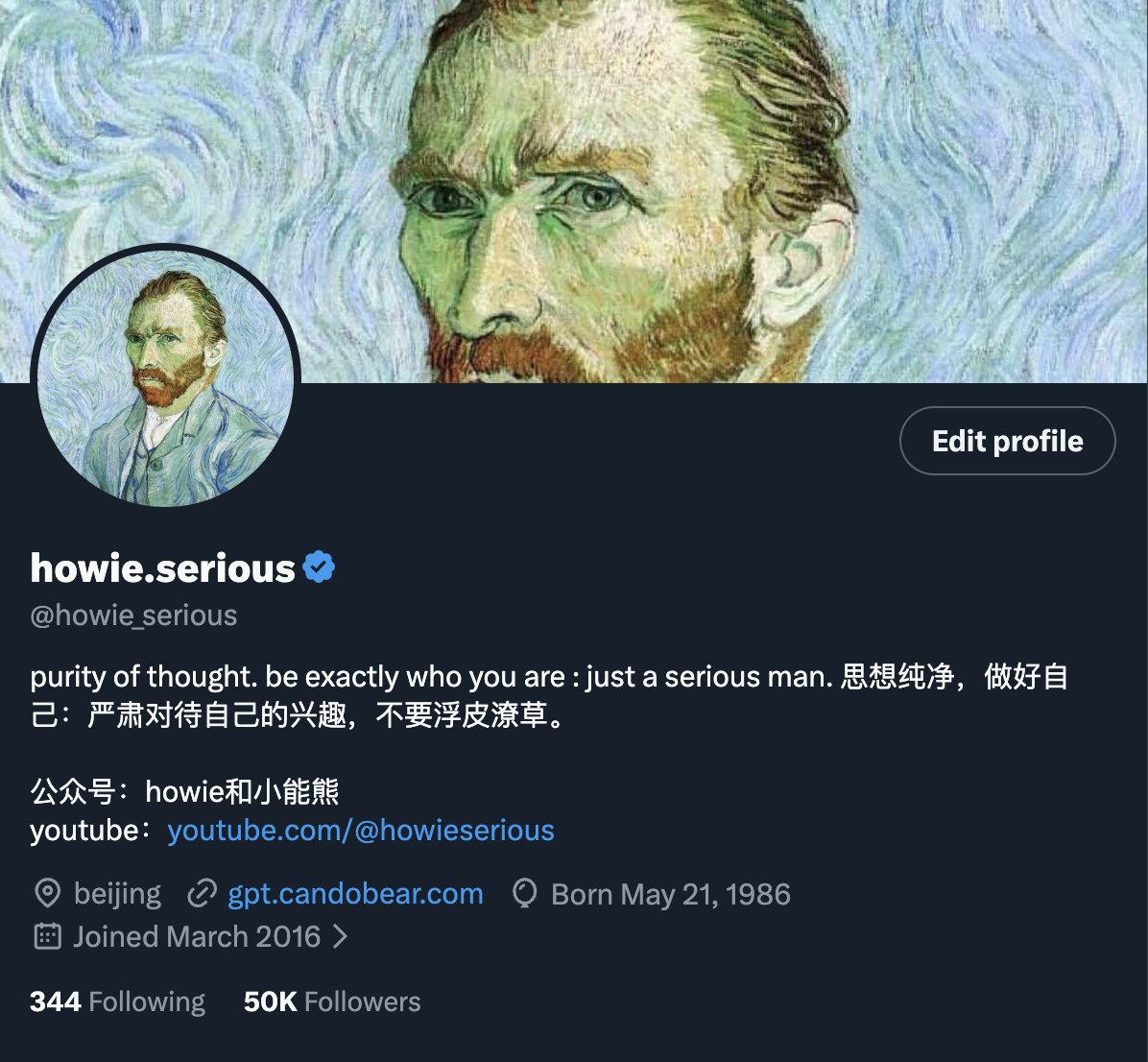
20k 关注了。mark 一下。 今年4 月时,作为近乎 0 关注的新人,用30 天时间,每天费曼一条自己的思考,一个月新增了10k 的关注。 中间有各种事情,情绪低落困难,几个月没发 twitter。这两个月继续费曼式分享,有幸抵达下一个里程碑。 一个新变化,是在 24 年 12 月开始录知识视频了。 24 年的 motto 在今年仍然有效,更加重要:purity of thought. be exactly who you are.


Gemini、豆包、元宝、通义听悟、Get笔记、NotebookLM、Claude Code、Genspark、Manus、Cherry Studio、Monica、11 Labs、HeyGen、Nano Banana、Lovart、Midjourney、Runway、即梦、可灵、Spokenly、Whisper、元器、扣子、Dia浏览器、Comet、Fellou、Gamma、Kimi、AIPPT youtu.be/BXslvywU8RI




“方法论移植” —— 把《Mom Test》的用户调研思路套到和大语言模型(LLM)对话、设计 prompt 这种新兴交互上。 核心隐喻依然成立:别问模型(就像别问妈妈)一些会自动给出“好听废话”的问题,而要构造 prompt,让模型给出可验证、基于事实或明确约束的回应。 可以提炼出几个要点: --- 1. 避免问意见,改问证据 坏 prompt: - 你觉得这个方案好不好? - 这样设计是不是很合理? 模型的倾向:它会很礼貌地说“是的,很不错”,并生成一些泛泛的优点。 好 prompt: - 请给我 3 个具体反例,说明这个方案可能失败的场景。 - 请基于已知的事实/数据,列出这个设计可能遇到的限制。 --- 2. 避免未来假设,追问过去表现 坏 prompt: - 如果遇到X问题,你会怎么处理? (模型会发挥编故事,结果没法验证真伪) 好 prompt: - 请列举你在训练语料中学到的、已经出现过的X问题解决案例。 - 在过去的研究或历史记录中,X是如何被解决的? 这样能把回答 anchor 在已有知识而不是随意幻想。 --- 3. 避免模糊,要求具体 坏 prompt: - 帮我优化这个文案。 - 给我一些改进建议。 好 prompt: - 请将这个文案重写成3个版本:① 面向投资人,② 面向工程师,③ 面向普通用户,每个版本100字。 - 请逐句指出文案中哪些地方含糊,并给出更清晰的替代表达。 --- 4. 用行为驱动而不是态度驱动 坏 prompt: - 如果你是用户,你会不会喜欢这个产品? 好 prompt: - 假设你是目标用户,请模拟一次实际使用过程,并逐步写出你会点击、输入、犹豫的步骤。 --- 5. 验证而非求赞美 坏 prompt: - 你能确认我这个逻辑是对的吗? (模型会有从众/迎合倾向,容易给“是的,没问题”) 好 prompt: - 请检查我这个逻辑,找出其中至少一个可能的错误,并解释理由。 - 如果必须反驳我,请站在反方角度给出3点论证。 --- 总结一句: 把 Mom Test 的反礼貌思维套到 LLM 上,就是在 prompt 中逼它不要给面子话,而要给事实、行为、反例和限制。 这其实能让 prompt 变成一套“抗幻觉、抗恭维”的护栏。
