Angehefteter Tweet
Remington Wilcox
481 posts


Remington Wilcox
@remwilcox
vibecode extraordinaire photo/film/music/diy
Beigetreten Aralık 2011
380 Folgt219 Follower
im really liking opus 4.7 now, took some time to figure out how to steer it better but after getting used to it this model is very capable and its using much less usage than im used to with opus
English

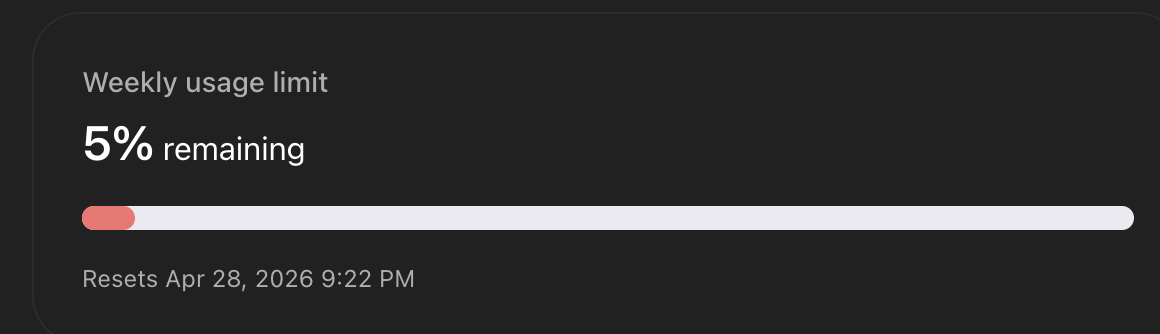

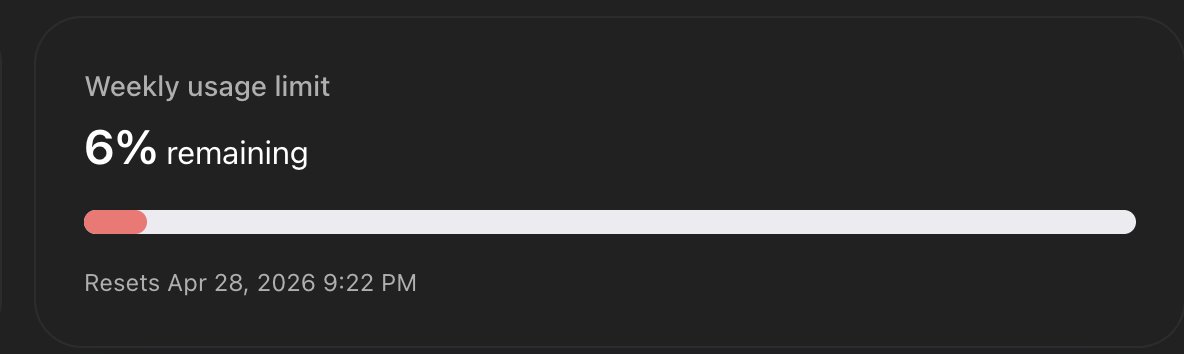

this plan ive had codex implementing over the past few days routinely takes 5+ hours each run, I was hoping gpt 5.5 would speed things up but already 1hr in on this
i also have not even looked at the results yet, 3 days shooting the slop cannon in the dark
agi has arrived
English
@sama @scaling01 plz sam reset limits again to celebrate 5.5
English


The GPT-5.5 model family completely dominates the cost-performance frontier on the Artificial Analysis Index
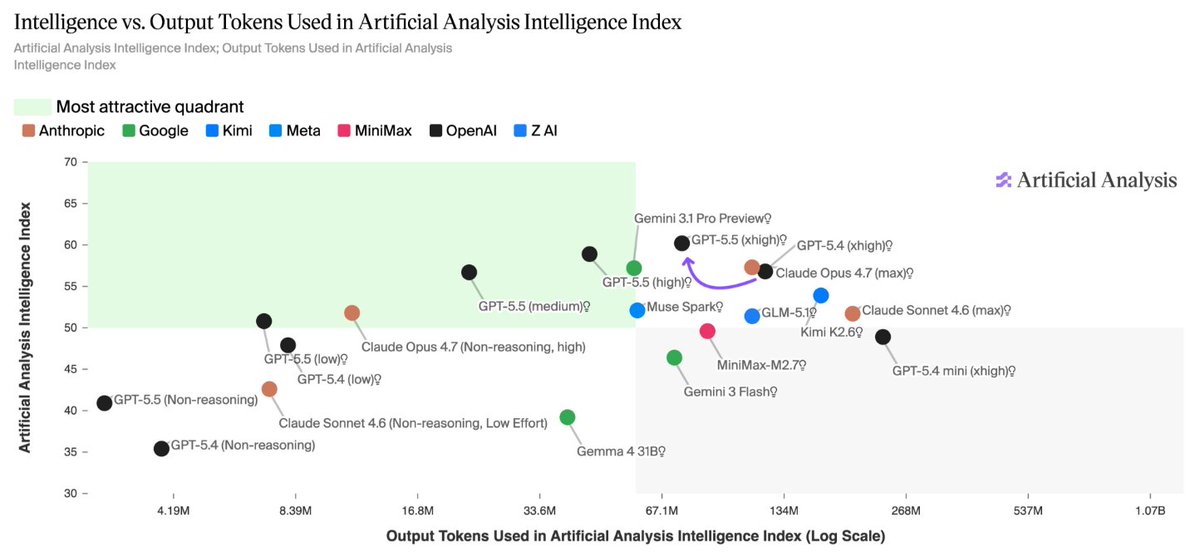
Artificial Analysis@ArtificialAnlys
GPT-5.5 takes OpenAI back to the clear number one in AI. OpenAI’s new model tops the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google OpenAI gave us pre-release access to test all five reasoning effort levels: xhigh, high, medium, low and non-reasoning. ➤ OpenAI topping five headline evaluations: GPT-5.5 (xhigh) leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience (+14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom (+7 pts), a customer service agent benchmark. ➤ 20% more expensive to run our Intelligence Index: Per-token pricing has doubled from GPT-5.4 to $5/$30 per 1M input/output tokens. However, a ~40% token use reduction largely absorbs the hike - resulting in a net ~+20% cost to run our Intelligence Index. ➤ Effort a clear ladder for balancing intelligence and cost: GPT-5.5 (medium) scores the same as Claude Opus 4.7 (max) on our Intelligence Index at one quarter of the cost (~$1,200 vs $4,800) - although Gemini 3.1 Pro Preview scores the same at a cost of ~$900. GPT-5.5 (low) approximates Claude Opus 4.7 (Non-reasoning, high) on our Intelligence Index at half the cost to run (~$500 vs ~$1 ,000). ➤ Number one in GDPval-AA with an Elo of 1785: GPT-5.5 (xhigh) leads Claude Opus 4.7 (max) by ~30 pts and Gemini 3.1 Pro Preview by ~470 pts. GDPval-AA is Artificial Analysis’ benchmark that leverages OpenAI’s GDPval dataset to evaluate models on real-world economically valuable tasks. ➤ Top AA-Omniscience accuracy, but trailing the frontier on hallucination: Our private AA-Omniscience benchmark rewards factual knowledge across diverse topics, but punishes hallucination. GPT-5.5 (xhigh) has the highest accuracy at 57% - meaning the model can recall facts in the Omniscience corpus more effectively than any other model. However, it has a hallucination rate of 86% - vs Opus 4.7 (max) at 36%, and Gemini 3.1 Pro Preview at 50%. This makes it more likely to answer a question when it does not ‘know’ the answer. The 14 pt gain in AA-Omniscience from GPT-5.4 (xhigh) was largely driven by knowledge, with a modest improvement in hallucination. Congratulations to the team at @OpenAI and @sama on the launch
English
@alightinastorm lmao actually cant believe they did that twice in a row
English

Today is a hand writing code day. Codex is not vibing for me today.
English

some thoughts after blasting opus 4.7 for a week
-its like codex in the bad ways and not the good ways
-huge improvement on vision / computer-use
-talks like a corpo karen now and lost all personality
-extremely good at research and repo audits
im using 4.6/4.5 alot still
English

@corysimmons123 LMAO its actually insane how many ways there is to make money im the patreon trenches
there is a die hard community for everything
English




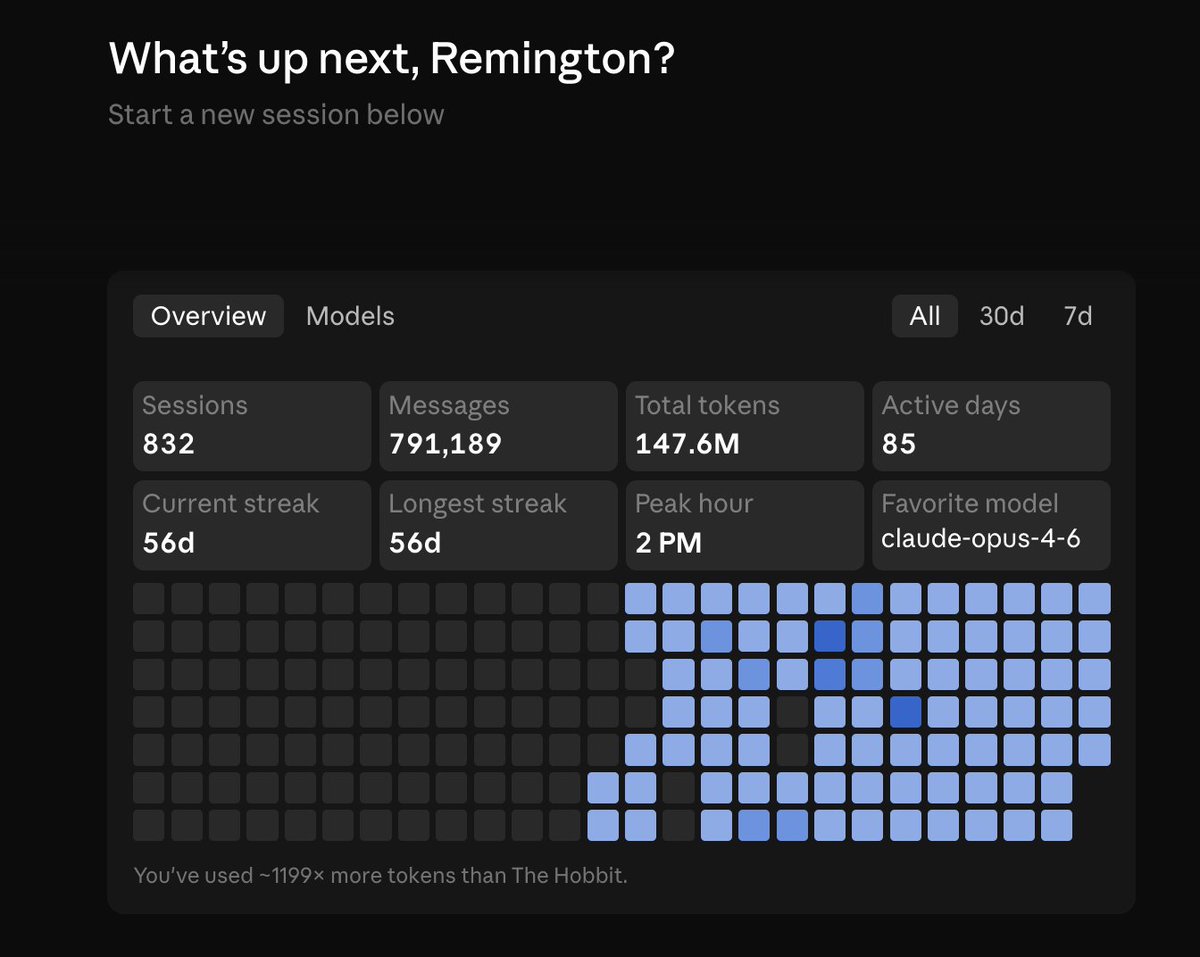
claude co-work on the remote mac mini running opus 4.7 w/ custom skills & computer-use is blowing my mind
English
often times the best things are full of bugs
- halo 2
- pubg
- nature
English
@remwilcox stop telling the AI so much, your prompts look well defined fir you but constrain the agent
English
ran a little test
gave the exact same deep research prompt to a fresh opus 4.6 and opus 4.5 session
opus 4.6 - 6 subagents and 35 minutes to complete
opus 4.5 - 18 subagents and 8 minutes to complete
results: opus 4.6 research was significantly better, a proper deep dive
English