
Sam Ching
516 posts

ok life update: i'll be joining @Cognition!
• Cog just went from 0 to $10b in 2 years
• Net burn $20m in company history
• Avg successful Devin impl sees >5x growth, $1.5m/yr customer expanded >10x in 8 months (not typo)
• Windsurf x Cog cross sell going great, looking fwd to cross build. Lighthouse customers in every vertical.
• Windsurf's polish + Wave 13/14 are looking v HYPE! more work to do on Windsurf Tab
Here's the 5 decision points I had to cross to "buy" Cognition's rise as an Agent Lab that has the potential to be as dominant in the Decade of Agents:
• Short Code timelines, Long AGI timelines
• The rise of Agent Labs
• Owning the Sync/Async spectrum
• Start high, go low
• Cracked Engineers + Ramped GTM
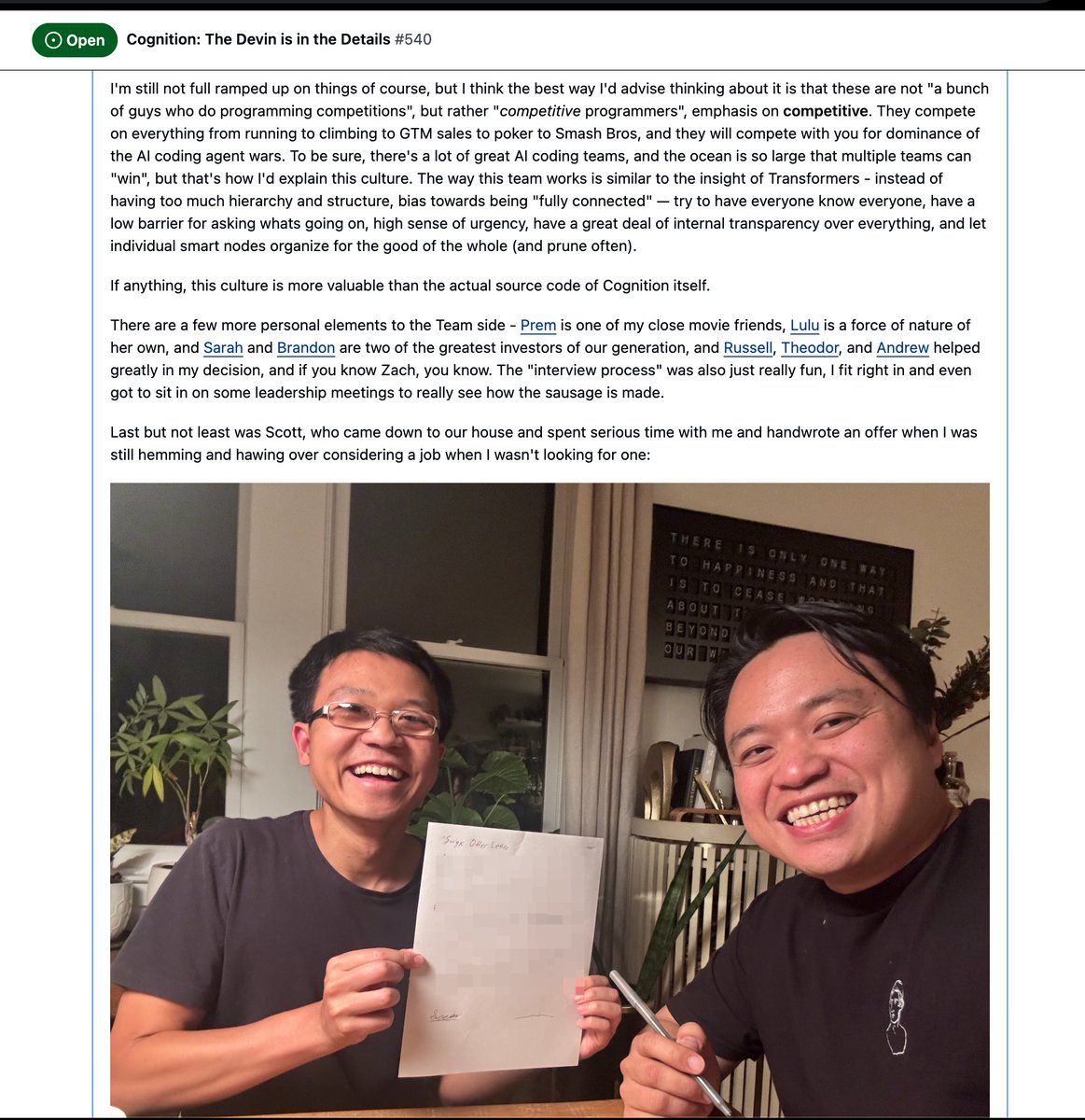
This is probably TMI but I like to record thoughts in public so I can learn when I am wrong, and for others to follow along. Happy reading, in reply tweet.
also: Most of @smol_ai capital base is rolling over to Cognition's round today. I'll be returning the rest. AINews and SmolTalk will remain my passion projects.
I will continue to operate @aiDotEngineer and @latentspacepod ferociously independent of Cognition. All Cognition competitors were given ample heads up + red carpet to AIE CODE. Ben and I are BEYOND excited to have Lia step up as the new General Manager of AIE!


Cognition@cognition
We’ve raised over $400M at a $10.2B post-money valuation to advance the frontier of AI coding agents. The round was led by Founders Fund with other existing investors including Lux, 8VC, Neo, Elad Gil, Definition Capital, and Swish VC all doubling down. We’re also joined by new investors including Bain Capital Ventures and D1 Capital. Two of our early investors, Christian Lawless of Conversion Capital and Emily Cohen of Neo, have even joined our team full-time.
English
Daniel Ching@danielchingwq
1/n: A thread for local eats+transport in 🇸🇬 for those coming to @ICLR ! For those coming to Singapore for the first time, a huge welcome :D ICLR would be held at the Expo -- closest MRT station: CG1 (Green East-West Line, 1 stop from Changi Airport), DT35 (Blue Downtown Line)
English

I’ll be in Singapore 🇸🇬 for @iclr_conf this week! Looking forward to catching up with friends and meeting new folks in AI.
English
Sam Ching retweetet

1/n: A thread for local eats+transport in 🇸🇬 for those coming to @ICLR !
For those coming to Singapore for the first time, a huge welcome :D
ICLR would be held at the Expo -- closest MRT station: CG1 (Green East-West Line, 1 stop from Changi Airport), DT35 (Blue Downtown Line)

English
Worth a read!
Kudos to @darshj_shah , @peter_rushton, @ashVaswani and the rest of the team for this work.
Looking fwd to future releases.
Ashish Vaswani@ashVaswani
To learn more, read our complete paper. We will be sharing additional results with the community in the coming weeks because we believe open science will accelerate the development of frontier capabilities. Paper Link: arxiv.org/abs/2504.04022 [4/4]
English



Excited to share a peek of what I’ve been working on
We @sesame believe voice is key to unlocking a future where computers are lifelike
Here’s an early preview you can try! 👇
We’ll be open sourcing a model, and yes…
we’re building hardware! 🧵
English
English

8/ Bhumi is Open Source
Try it out:
👉 GitHub: github.com/justrach/bhumi
👉 Full breakdown: rach.codes/blog/Introduci…
AI should be fast. Let’s make it happen. 🚀
pip install bhumi now!
English
6/ Why Rust?
Python is great, but:
❌ Async isn’t enough for low-latency optimization
❌ Managing memory efficiently is hard
❌ Handling multiple concurrent requests gets messy
✅ Rust (via PyO3) lets Bhumi run fast under the hood while keeping a Python-friendly interface.
English
@rosstaylor90 Congrats on the launch Ross!! Thank you for sharing this and looking fwd to what the community does.
Curious what's the timeline to getting the datasets on 🤗?
huggingface.co/GeneralReasoni…
English

This project was a short one-month sprint following the “R1 moment” 🐋 - let me know your feedback!
More is cooking depending on how this lands 😇.
English
🎉 Excited to release General Reasoning: a new community resource for building open reasoning models.
We’re looking to make personal, open reasoners a reality. Starting with a small step in that direction today!
Read the thread in the quote tweet for details, or my personal analysis below!
English
Sam Ching retweetet

When we started the company at 19, we had grand ambitions, but I never imagined how fast it would happen.
I'm incredibly grateful for the team we've built and everything they've accomplished.
Labor allocation is the most important problem in the world and we're only cracking the surface.
Mercor@mercor_ai
Mercor is solving talent allocation in the AI economy. The difference between greatness and failure is the right person being in the right place at the right time. Putting them there is the hardest unsolved problem in capitalism. We’re excited to announce our $100M Series B at a $2B valuation from @felicis, @generalcatalyst, @benchmark, DST and @MenloVentures.
English
Sam Ching retweetet

[1/7] Introducing Evo 2, a new foundation model for biology.
🚀 Evo 2 is the largest-scale, fully open-source AI model ever released: 40 billion parameters, over 9 trillion tokens, and a 1 million context length. All the details are public: weights, data, training infrastructure, and inference infrastructure.
⚡Evo 2 is built on a new model architecture: convolutional multi-hybrids (StripedHyena 2). StripedHyena 2 excels at modeling byte-tokenized data, providing faster training and lower perplexity compared to both Transformers and previous-generation hybrids based on state-space models.
I am grateful for the team behind Evo 2—working with you was one of the proudest moments of my career (the core pretraining team was fewer than five people; you can just do things).
📚 Today, we release two papers (yes, plural), as well as weights, data, training, and inference codebases. Enjoy!



English
@n0riskn0r3ward Great thread! Tks for sharing.
Would love to hear more about 6c - what are the org incentives that shape the odds this way?
English

6/ Conclusions:
After all this I simultaneously believe:
a) in the long run, it's still likely that many successful gen ai startups will be built on top of models they iteratively fine tune. It's not easy but you 100% can actually build a moat this way
b) no one should start with fine tuning
c) the odds are stacked against most larger incumbents ever succeeding at getting their data/eval house in such tight shape that the best use of their marginal hour is fine tuning their own models (7/7)
English
I spent the last ~6 months fine-tuning models at Arcee AI for a wide variety of clients ranging from Fortune 500 enterprises to 2 person gen ai native startups.
Short version of the 🌶️ takes in this thread: No one fine tuning models for clients is a “machine learning engineer” most of the week. If they’re fine tuning good models for third parties they’re doing it by being a skilled and tireless data janitor and eval architect.
Longer thread with some 🌶️ takes on the practical challenges and sometimes painful realities of fine tuning for clients (1/7):
English
@eddy_data3 Gotcha totally makes sense! This looks promising though - excited to see more work in this area (bootstrapping environments from webscale data)
Kudos on the work!
English

One qn: > 5.1: In contrast, for data from WebInstruct without fully reliable supervision signals but with a much larger scale, we sample one response per prompt from the teacher model without filtration.
-> why not use filtered subset and do rejection sampling for SFT?
English

So Anthropic is currently training models on a 50 EFLOP system(50K H100s)
Andrew Curran@AndrewCurran_
From the Amazon earnings call. Apparently 'Ultraserver' is a real word, I checked.
English
English



This + @sama 's tweet (x.com/sama/status/18…)
remind me of @rosstaylor90 's talk from last year.
What is the most helpful style for models to express their reasoning in?

English
SFT initialization helps, and could also contribute to style, per @rosstaylor90
x.com/rosstaylor90/s…
English
Scaling verifiable reward signals is the key: appreciate the silver signals study.
Love to see more work push on mining verifiable rewards from webscale data: x.com/xiangyue96/sta…
cf Karparthy / Shane on more rl envs -- x.com/shaneguML/stat…
Shane Gu@shaneguML
@karpathy In short, we need BIG-bench for LLM RL. github.com/google/BIG-ben…
English
Congrats to @eddy_data3 and @xiangyue96 and the team for the detailed study on Long CoT.
Many interesting ablations and lessons, similar to parallel work coming out e.g. by @junxian_he
eddy@eddy_data3
Such a rewarding experience (pun intended) collaborating with @tongyx361 @xiangyue96 @sirius_ctrl @gneubig! We hope our results are useful to the community 🙏
English