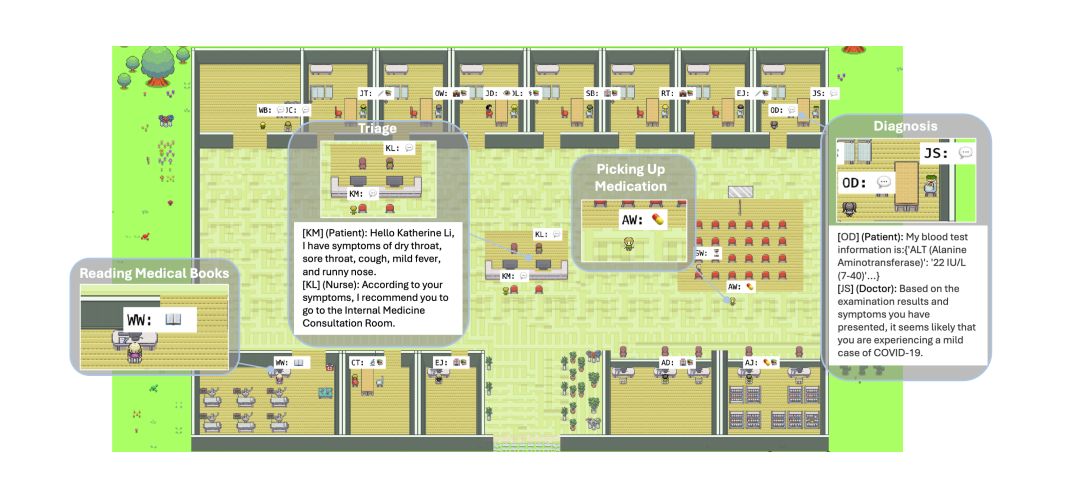
Angehefteter Tweet

#VisualAgentBench: 4o, 4o-mini, 3.5-sonnet currently have an edge as visual foundation agents for now, but open models InternVL & GLM-4V are catching up fast, a similar story to LLMs as agents as revealed in #AgentBench back in Aug 2023.
arxiv.org/pdf/2408.06327
github.com/THUDM/VisualAg…

English