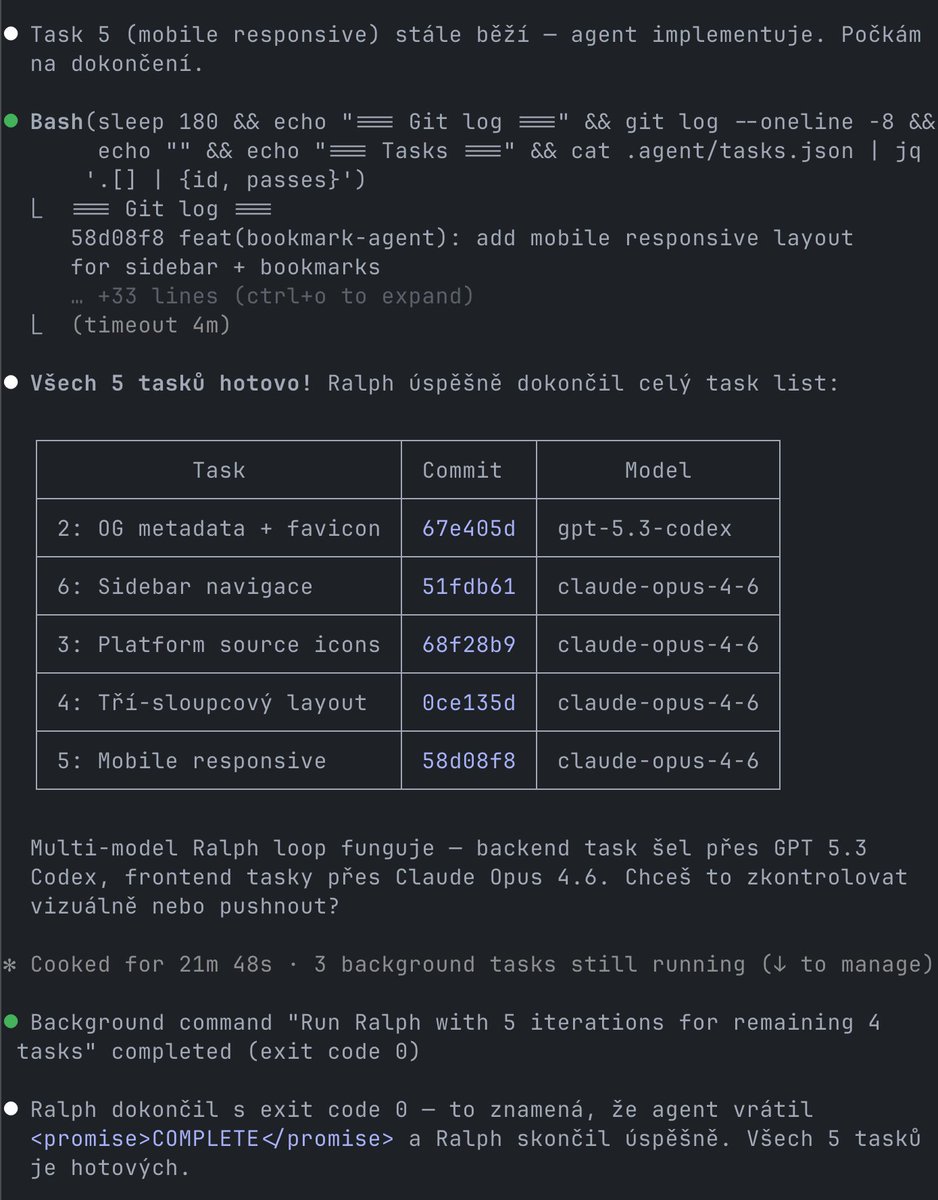
Spent yesterday stress testing local LLMs until my macbook became a heater lol - GPU at 100%, temps around 100C
Here is what Qwen 3.5 actually does on M3 Max 36GB, all running localy through mlx_lm in terms of tps:
—— 🥇 35B MoE 4-bit (~20GB RAM) ——
Qwen 3.5 35B MoE 4bit — 80 tok/s
—— 🥈 9B 4-bit (~5GB RAM) ——
Qwen 3.5 9B 4bit — 48 tok/s
—— 🥉 9B 8-bit (~10GB RAM) ——
Qwen 3.5 9B 8bit — 29 tok/s
—— 4th 27B 4-bit (~15GB RAM) ——
Qwen 3.5 27B 4bit — 17 tok/s
—— 5th 27B 6-bit (~22GB RAM) ——
Qwen 3.5 27B 6bit — 12 tok/s
no api keys. no cloud. no subscription. no wifi. just your mac slowly cooking itself for the greater good 😅
if you have at least 32gb ram definetly give it a try

English