Angehefteter Tweet

現場で実際にぶつかった課題から見えてきた、
経営・現場・開発の温度差と、AIエージェント実装の考え方を書きました。
エンジニアに限らず、AIエージェント導入に関わる全ての方にとって何か役に立てば嬉しいです。
note.com/yusakuiwaki/n/…
日本語
岩城祐作 | Algomatic
898 posts
@yukl_dev
ソフトウェアエンジニア🍻/ Azure Solutions Architect Expert / TypeScript, Python, Next.js, React, Terraform, LangChain / スクラム大好き / AI開発(エージェント, アバター) / お笑い芸人さんのレコメンド🗣️

new model for engineering team structure in 2026: 2 people only one pirate and one architect the pirate's job is to move as fast as possible to develop valuable, shipped product features by vibe coding. the architect's job is to turn the product surface discovered by the pirate into a reliable, structured machine—also by vibe coding, but at a slower, more well-reasoned pace. every product needs a pirate but most product's only need an architect once they some form of PMF, and in that case they usually don't need one full-time. architects can work across many codebases and solve interesting technical challenges. pirates go hard on a product that they own end-to-end.







▶テックブログ公開のお知らせ📣 【社内勉強会】 AI生成したスライドに限定した社内LT会を開催しました ift.tt/YxXtL52


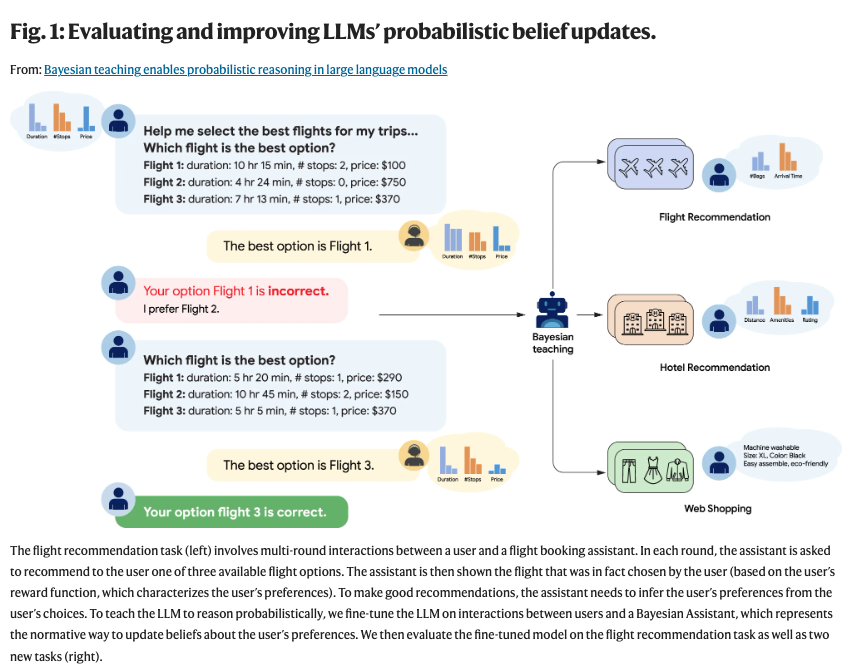


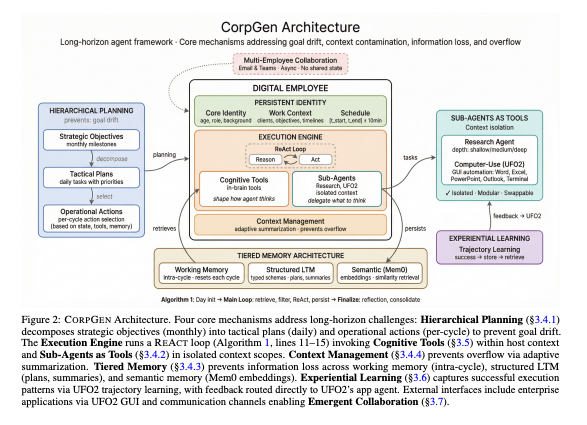






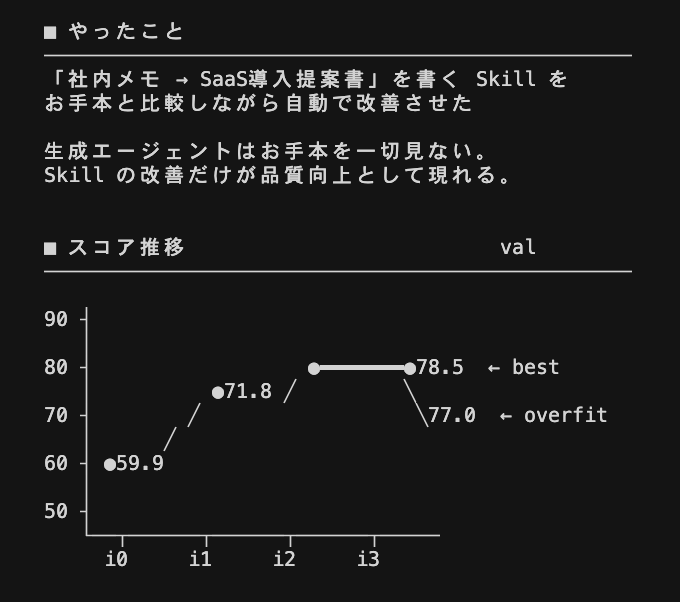
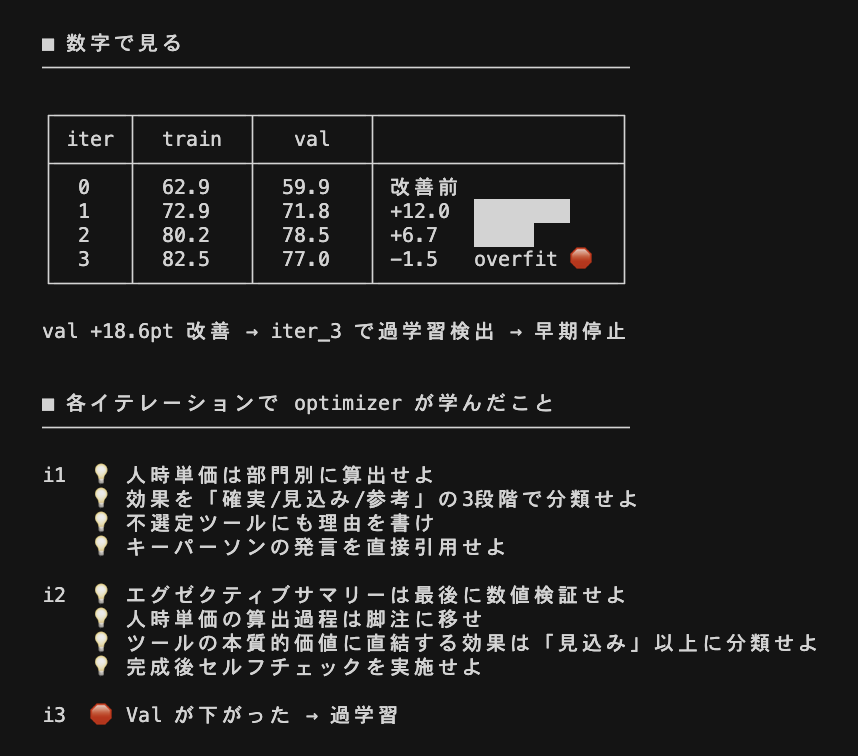
誰でも簡単にSkillsを自動最適化できるClaude Codeのプラグインを試しに作成中。 TextGradという有名な研究を参考に、Skillsを従来の深層学習のような方法でFine Tuningできるようにしたい。 Skillsに、forward, loss, backward,,,,などの概念を適用するのはなかなか面白いかも。