
0xTodd
10.9K posts

0xTodd
@0xTodd
Long BTC, Love the World | 热衷研究 | 在 @researchnothing 琢磨策略 | 在 @ebunker_eth 打包区块 | #Binance 远古交易用户 https://t.co/42whA3ioyb | #OKX 资深钱包用户 https://t.co/8Aes1jx1Xn | NFA
Singapore Se unió Eylül 2016
3K Siguiendo71.4K Seguidores

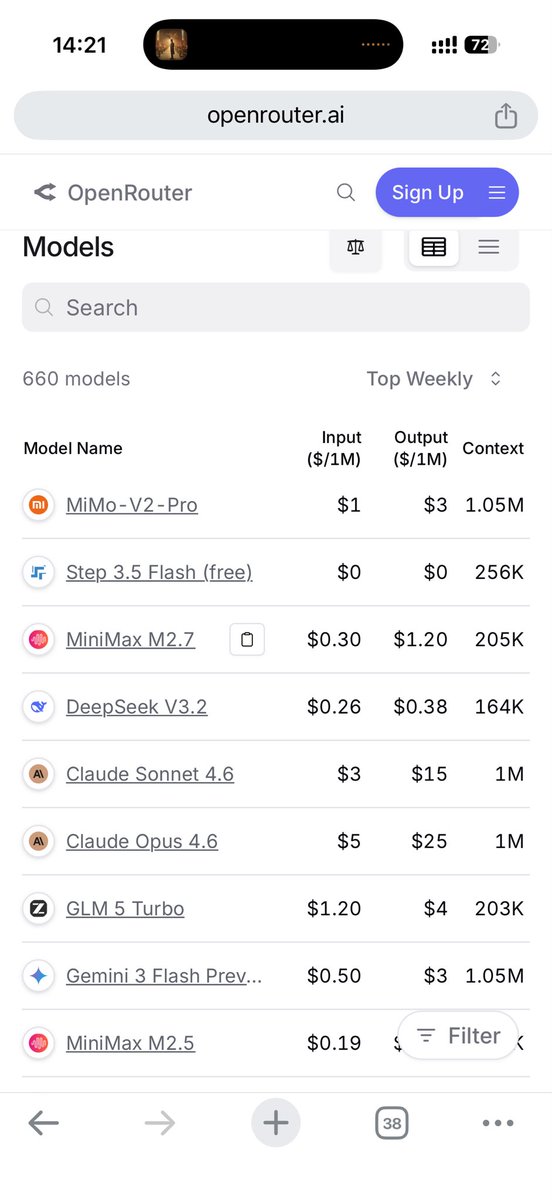


@0xTodd 他们估值多少,完全取决于有没有人能超越他们
要是老马搞出个新模型,能把他们按在地上摩擦,那么马上就缩水,要是老马半年后,搞的模型还是个二流,御三家还是御三家,甚至后面的跟他们的差距越来越大,市场一看,搞大模型确实难,那估值就蹭蹭的涨。
中文






@Michael_Liu93 感觉川普突然想明白了,学会了定义,他把对委内瑞拉的行动定义为司法部的行动,属于联合执法。然后对伊朗定义为消除威胁,也没走国会批准,属于和俄罗斯那个“特别军事行动”有一拼。
中文










真的恐怖,Claude 的新模型 Mythos 已经开始超小范围内测了,居然还能碾压 Opus 一个级别。
Haiku 是三行诗,Sonnet 是十四行诗,Opus 是杰作,Mythos 字面意思则是神话。
不管是真的泄露,还是在某种低调营销,根据目前已知的信息,这个模型是 Opus 的上位模型,逻辑和代码能力都提升了一个等级。
而且据报道,最牛逼的是在网络安全领域,以至于 Anthropic 要先给安全相关领域的公司小范围内测,来增加防守方的实力,而不是潜在、未知的攻击方。
Opus 已经经常成精了,不知道 Mythos 会神话到什么程度。

中文

曾经有一个魔兽工会叫myth
你们以为他是神话?其实他们是卖淫团伙。
0xTodd@0xTodd
真的恐怖,Claude 的新模型 Mythos 已经开始超小范围内测了,居然还能碾压 Opus 一个级别。 Haiku 是三行诗,Sonnet 是十四行诗,Opus 是杰作,Mythos 字面意思则是神话。 不管是真的泄露,还是在某种低调营销,根据目前已知的信息,这个模型是 Opus 的上位模型,逻辑和代码能力都提升了一个等级。 而且据报道,最牛逼的是在网络安全领域,以至于 Anthropic 要先给安全相关领域的公司小范围内测,来增加防守方的实力,而不是潜在、未知的攻击方。 Opus 已经经常成精了,不知道 Mythos 会神话到什么程度。
中文
