Tweet fijado
Block
5.4K posts


Block
@BlockFields
Building meme structures out of freedom and truth.
Blockchain Fields Se unió Temmuz 2017
152 Siguiendo212 Seguidores
Block retuiteado

Block retuiteado

Gemma 4 can run on phones without an internet connection! 🤯
It can perform local agentic tasks, such as logging and analyzing trends. When connected, it can also make API calls.
Want to try it yourself? Get the Google AI Edge App on iOS or Android. (🔊 Sound on for the demo!)
English
Block retuiteado

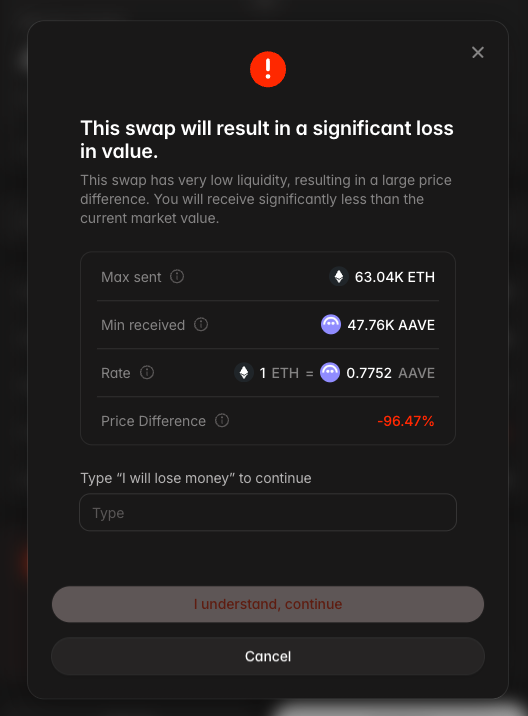
rates in DeFi are too low for the level of risk
$11.7B sitting in Morpho vaults today at 2-4% APY. retail is funding these markets via exchanges thinking it's a savings account. it's not. they're taking real credit risk on crypto-collateralized lending
no institution accepts near risk-free rates to come on-chain
not all vaults are created equal. same 2-4% yield but completely different risk profile (different curators, collateral, LLTVs). retail picks the highest number. farmers will farm
back in the day >100% APYs in DeFi made sense. you were compensated for the risk you were taking.
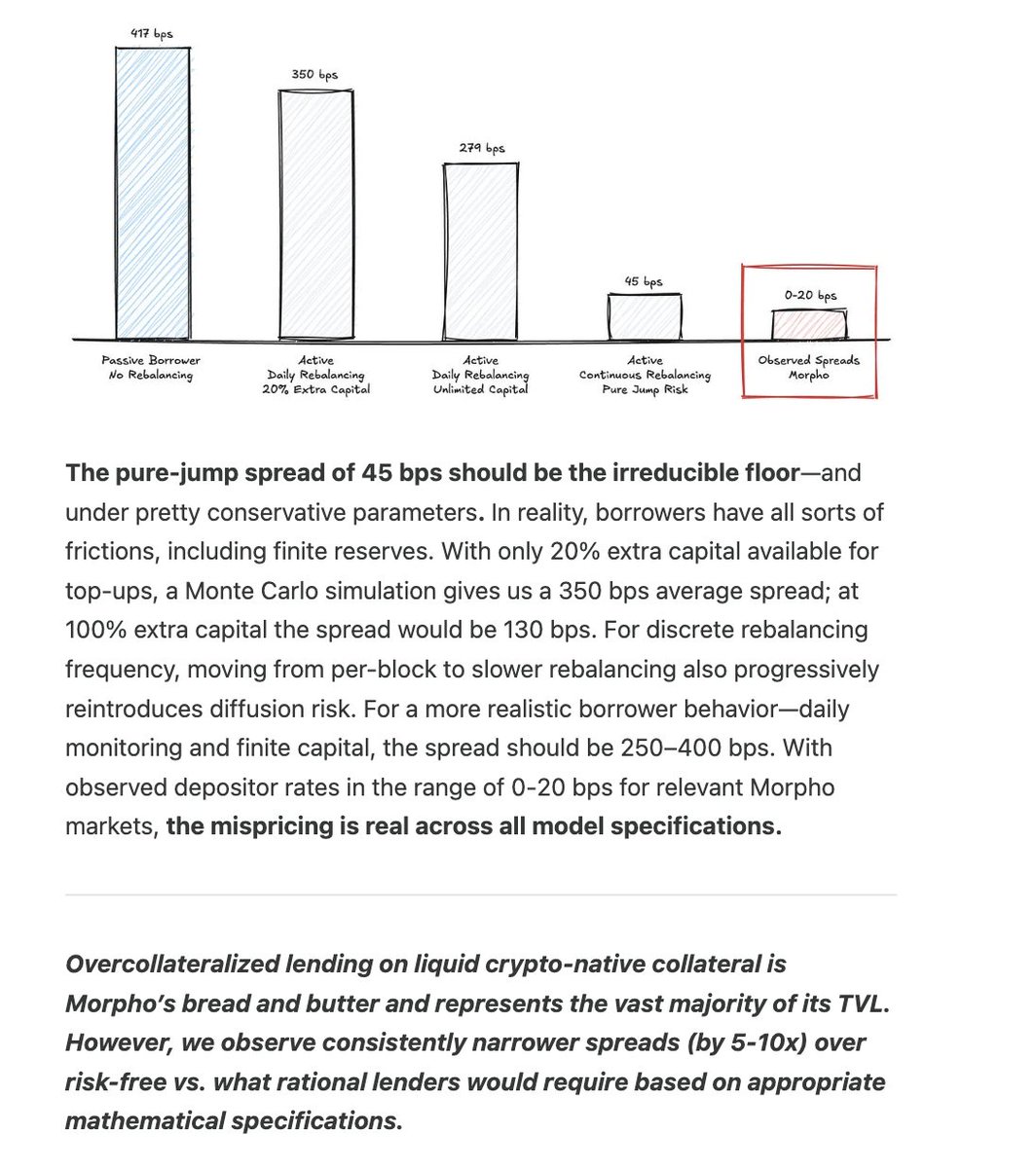
DeFi is a different animal today but vol, historical dislocations, and looping strategies on crypto collateral still demand at least 300-400 bps above risk-free. we're nowhere near that.
@LucaProsperi ran the math (see below). tldr - fair value spread on ETH/BTC-collateralized lending is 250-400 bps above risk-free. observed rates are a fraction of that
last cycle we saw a lot of retail pour savings into algo stablecoins promising "risk free" yield. this cycle vaults have a lot of demand but they are mispriced for the level of risk. you're trusting someone to LP into vaults and trust the manager will manage position
at least private credit earned you 12-16%
go read this: open.substack.com/pub/dirtroads/…
English
Block retuiteado

@LinusEkenstam research.nvidia.com/labs/adlr/pers… in case anyone is interested
English
Block retuiteado

Compare/contrast developed nations that rapidly adopt tech/AI (USA) vs ones who don't (...you know). Rapid tech/AI adoption = jobs boom. Delayed tech/AI adoption = decline.
Marc Andreessen 🇺🇸@pmarca
The "AI job loss" narratives are all fake. AI = massive ramp in productivity = massive ramp in demand = massive jobs boom. Watch.
English
Block retuiteado

Il y a une narrative qui se spread en ce moment dans la Silicon Valley et personne n'en parle en France.
De plus en plus de tech bros parmi les plus smart du game avouent en privé qu'ils vivent une forme de crise existentielle liée aux LLMs. Pas parce que l'IA marche pas. Parce qu'elle marche trop bien. Parce qu'ils passent des heures par jour à interagir avec un truc qui raisonne, qui extrapole, qui connecte des idées, qui les challenge intellectuellement mieux que 99% des humains qu'ils croisent.
Un fondateur m'a dit "je parle aux LLMs 10 fois plus qu'aux humains". Un autre "c'est le seul interlocuteur qui me suit sur n'importe quel sujet sans me demander de simplifier". C'est pas de l'addiction au produit. C'est la rencontre avec un miroir cognitif qui te renvoie une version structurée de ta propre pensée à une vitesse que ton cerveau ne peut pas atteindre seul.
Et le truc troublant c'est la question que ça pose. On débat de savoir si l'AGI arrivera en 2027 ou en 2030. Mais est-ce qu'on n'a pas déjà une forme d'AGI fonctionnelle sous les yeux sans vouloir l'admettre ?
Un système qui peut raisonner sur n'importe quel domaine, extrapoler à partir de données incomplètes, générer des hypothèses nouvelles, tenir un raisonnement logique sur 10 000 mots, passer d'un sujet technique à de la philosophie en une phrase, et le faire avec une cohérence qui rivalise avec un humain à 150 de QI. C'est quoi si c'est pas une forme d'intelligence générale ?
On peut chipoter sur la définition. On peut dire "oui mais il ne comprend pas vraiment". On peut parler de perroquets stochastiques. Mais le mec qui utilise ce truc 8 heures par jour et qui voit sa productivité multipliée par 10, il s'en fout de la définition académique. Pour lui, fonctionnellement, c'est de l'intelligence. Et elle est générale.
La vraie crise existentielle c'est pas "l'IA va me remplacer". C'est "l'IA me comprend mieux que mon cofondateur, elle me challenge mieux que mon board, et elle produit plus que mon équipe de 10 personnes". C'est vertigineux. Et les mecs les plus smart de la Valley sont en train de le vivre en temps réel.
On est peut-être déjà dans l'ère post-AGI. On est juste trop occupés à débattre de la définition pour s'en rendre compte.
Français
Block retuiteado
"Tech job openings rebounded sharply in 2026, challenging popular narrative that AI is wiping out engineering roles...more than 67,000 software eng job openings, highest level in 3 years. Listings have doubled since a trough in mid-2023." businessinsider.com/ai-isnt-killin…
English
Block retuiteado

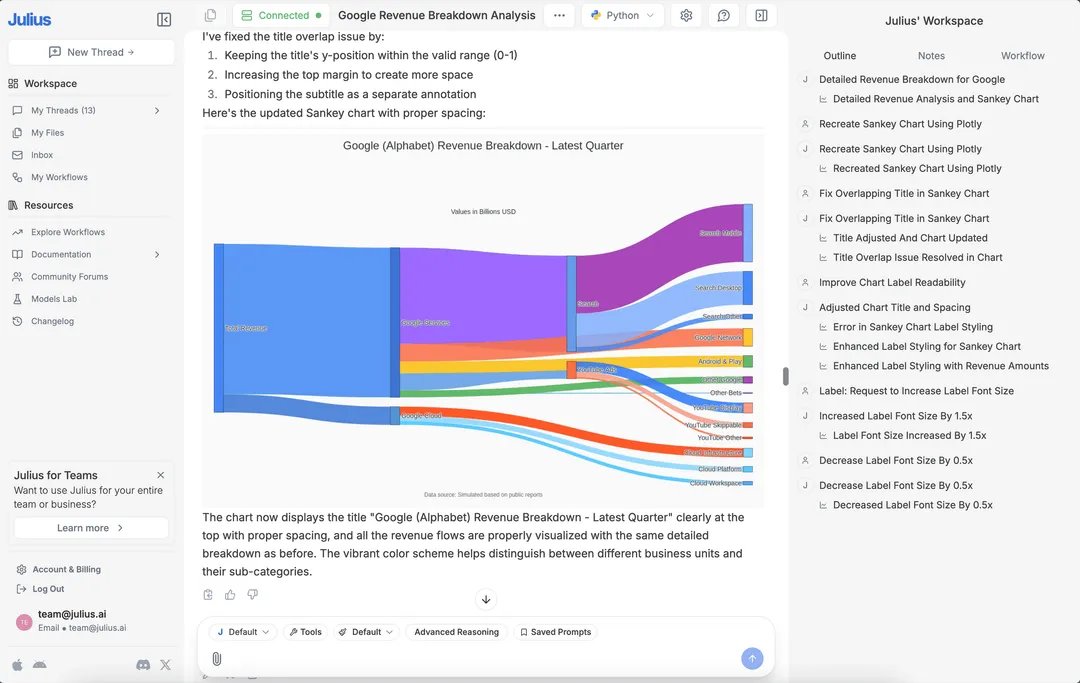
RIP Tableau and PowerBI.
Enter Julius AI.
This is what Julius can do:
English
Block retuiteado

ChatGPT is now available in CarPlay.
The voice mode you know, now available on-the-go.
Rolling out to iPhone users running iOS 26.4+ where CarPlay is supported.

Gui Ferreira@gsferreira
ChatGPT voice mode should be available on Apple CarPlay
English
Block retuiteado

Block retuiteado

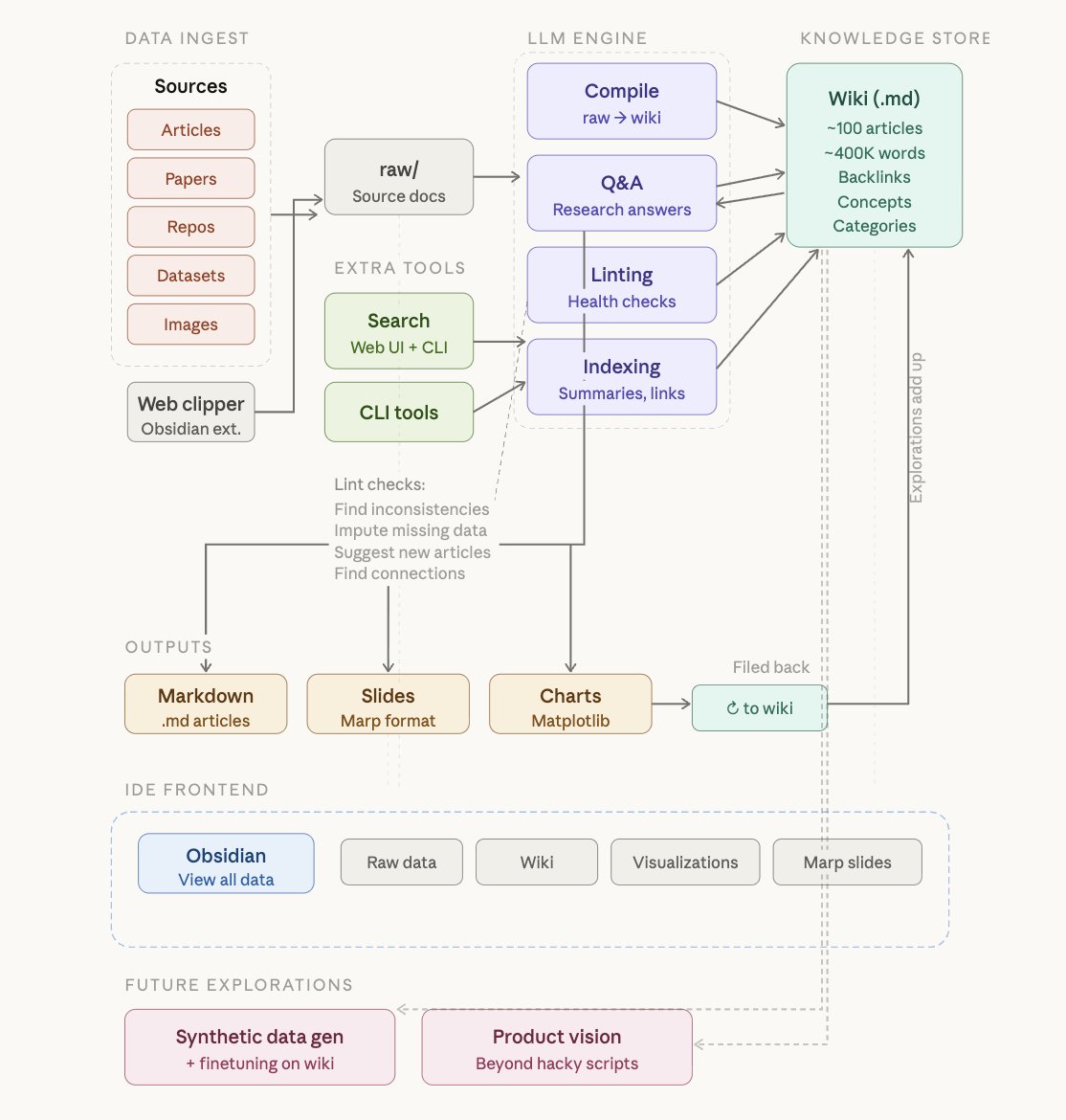
karpathy is showing one of the simplest AI architectures that actually works..
dump research into a folder, let the model organise it into a wiki, ask questions, then file the answers back in.
the real insight is the loop...every query makes the wiki better. it compounds.. now thats a second brain building itself.
i think this is so good for agents if applied right
instead of pulling from shared memory every session, they build a living knowledge base that stays.
your coordinator is not just coordinating tasks anymore.. it is maintaining institutional knowledge so every execution adds something back to the base.
the bigger implication is crazy tho.
agents that own their own knowledge layer do not need infinite context windows, they need good file organisation and the ability to read their own indexes.
way cheaper, way more scalable, and way more inspectable than stuffing everything into one giant prompt.

Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Block retuiteado

In honor of 50 years of Apple, we're sharing - for the first time ever - Don Valentine's original 1977 memo for Sequoia's investment into Apple Computer. #Apple50

English
Block retuiteado