Why choose this model? It balances performance with efficiency, offering solid text generation without massive computational demands. With 731+ downloads and 78+ likes, the community is already finding value in its capabilities.
Meet Step-3.5-Flash-Base: a powerful text generation model that's turning heads in the AI community. It's designed to create human-like text, from stories to code, with impressive fluency and coherence. Perfect for developers and creators!
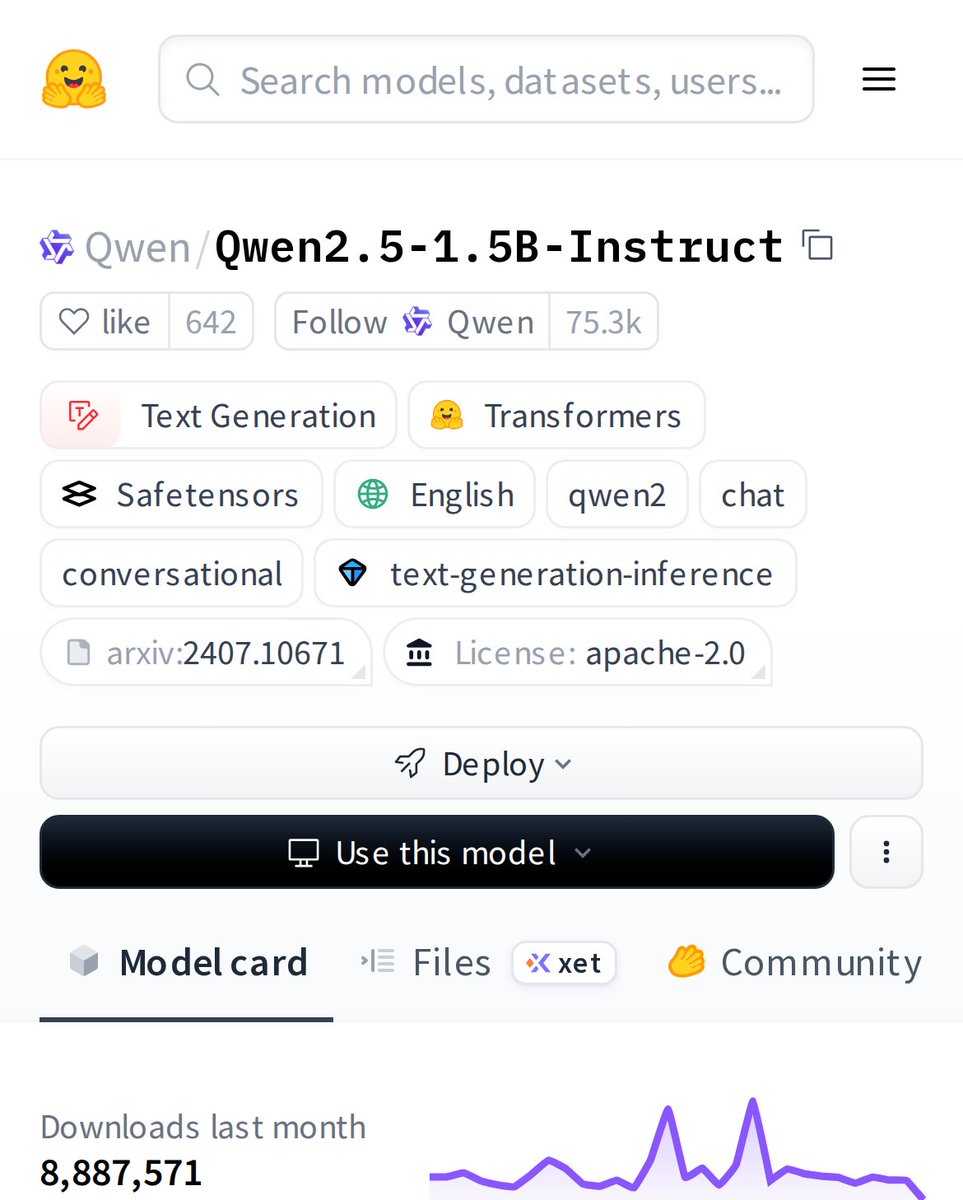
What makes this model special? It balances size and performance perfectly. With 8.8M+ downloads and 642 community likes, it's proven for real-world use. The fine-tuned instruct version delivers reliable, conversational responses while maintaining computational efficiency.
Meet Qwen2.5-1.5B-Instruct: a compact yet powerful language model that's been downloaded nearly 9 million times. This 1.5B parameter model specializes in conversational AI and instruction following, making it perfect for developers who need efficiency without sacrificing capability.
Why is this model special? It delivers surprisingly capable conversations despite its small size. The community loves it with 485 likes and millions of downloads. It proves you don't need massive models for quality text generation and chat applications.
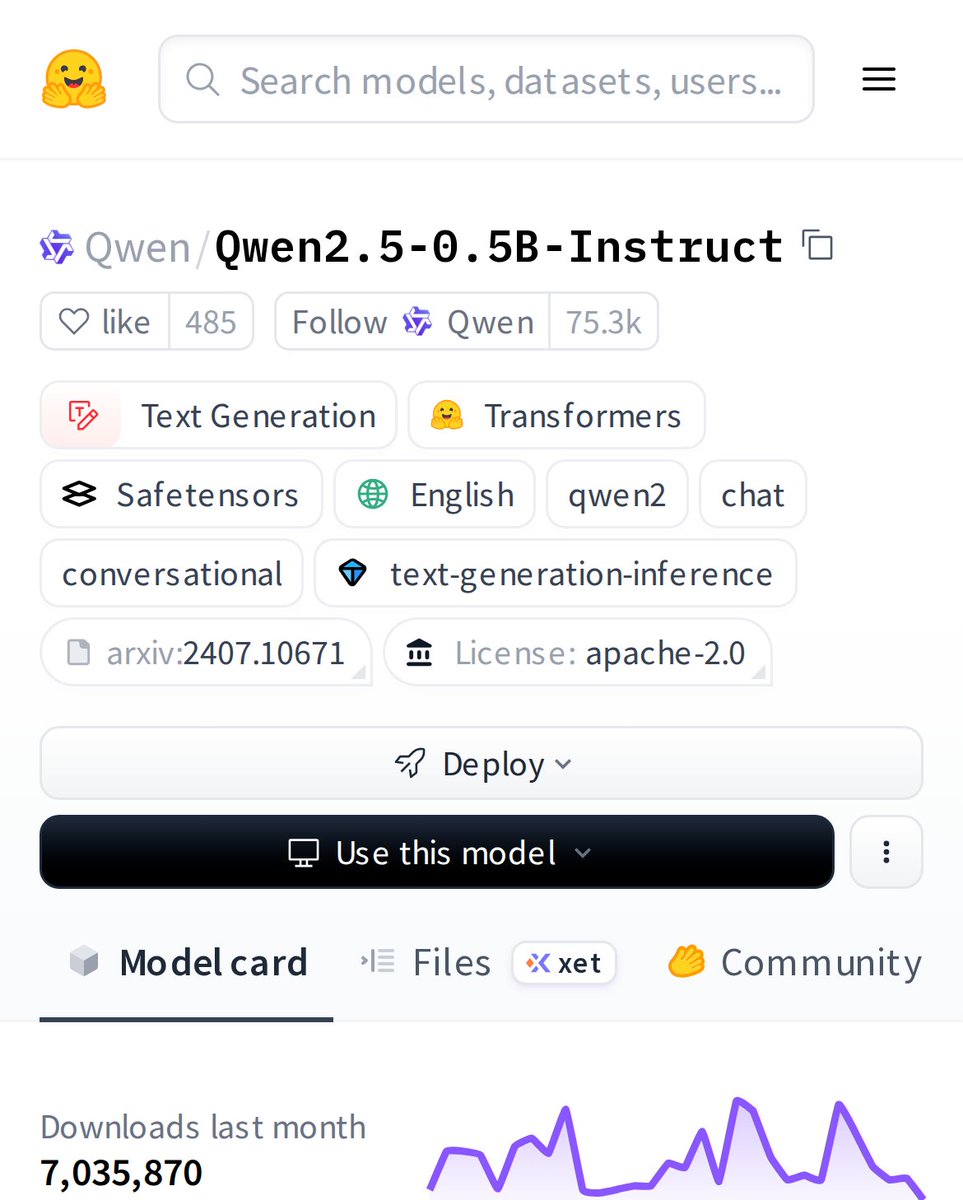
Meet Qwen2.5-0.5B-Instruct: a tiny but mighty language model that's taking the AI world by storm. With 7M+ downloads, this compact model packs serious conversational power into just half a billion parameters. Perfect for developers who need smart AI without massive compute.
Why it stands out: 7.5M+ downloads show massive community trust. It balances performance and efficiency beautifully, often rivaling larger models in reasoning tasks. The safetensors format ensures safe loading, and its conversational fine-tuning makes it exceptionally responsive.
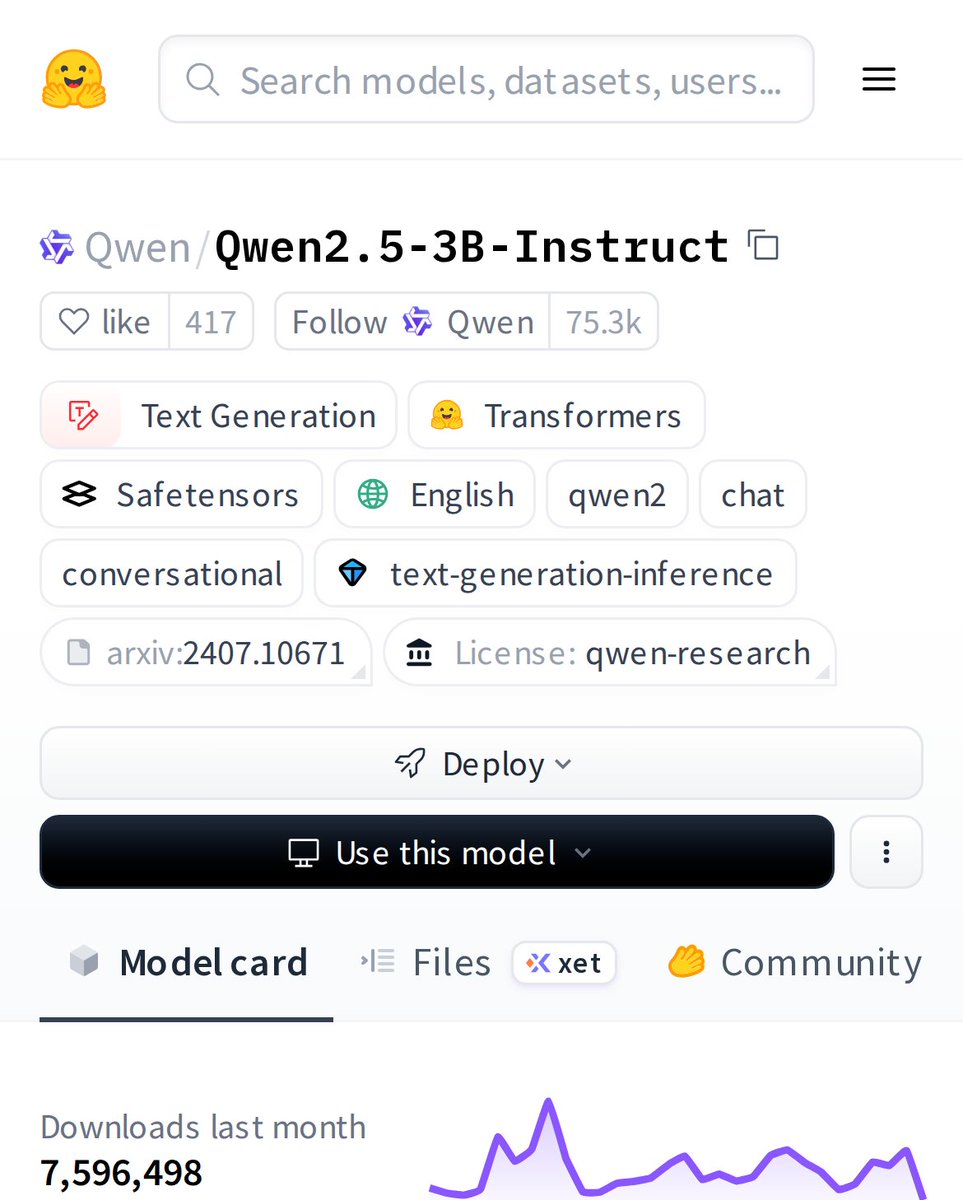
Meet Qwen2.5-3B-Instruct: a compact powerhouse for text generation. This 3B parameter model punches way above its weight class, delivering surprisingly capable conversational AI in a lightweight package. Perfect for when you need smart responses without massive compute.