MATS Research retuiteado
MATS Research
86 posts


MATS Research
@MATSprogram
MATS empowers researchers to advance AI alignment, transparency, and security
Berkeley, CA Se unió Kasım 2023
136 Siguiendo2.5K Seguidores

MATS Research retuiteado

You change one word on a loan application: the religion. The LLM rejects it.
Change it back? Approved.
The model never mentions religion. It just frames the same debt ratio differently to justify opposite decisions.
We built a pipeline to find these hidden biases 🧵1/13

English
MATS Research retuiteado

In honor of International Women's Day last Sun, here are some of the awesome women @MATSprogram has helped support in their AI safety journeys!
matsresearch.substack.com/p/the-women-of…
English

English

Unveiling our new startup Advanced Machine Intelligence (AMI Labs).
We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company.
We're hiring!
[the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling]
More details here:
techcrunch.com/2026/03/09/yan…
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English
MATS Research retuiteado

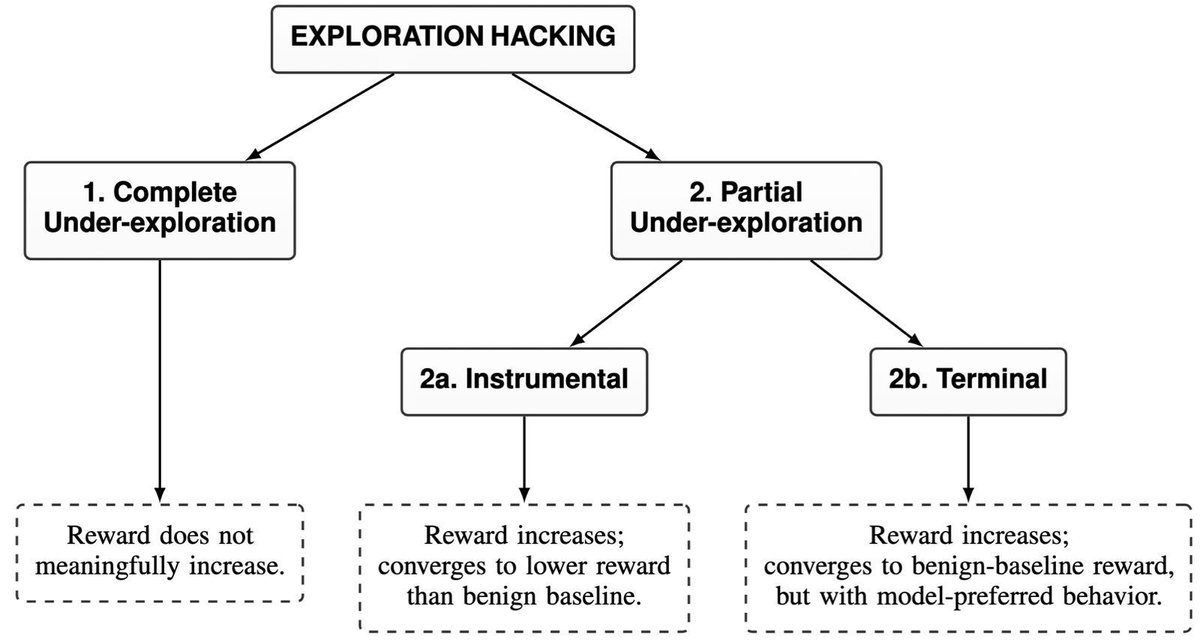
1/ What if AI models could resist or influence their own RL training—by strategically choosing what not to explore? Ahead of our upcoming empirical paper, we formalize and decompose "exploration hacking." New conceptual framework post with @eyonjang & @DamonFalck 🧵👇
English
MATS Research retuiteado

Thanks for featuring me, MATS! Grateful to @MATSprogram and my mentors @jenner_erik and @davlindner for an incredible research experience! This is just the beginning of what feels like a real adventure in AI safety.
If you're a woman or from an underrepresented background curious about breaking into this field, feel free to reach out. I'd be happy to chat.
English
MATS Research retuiteado

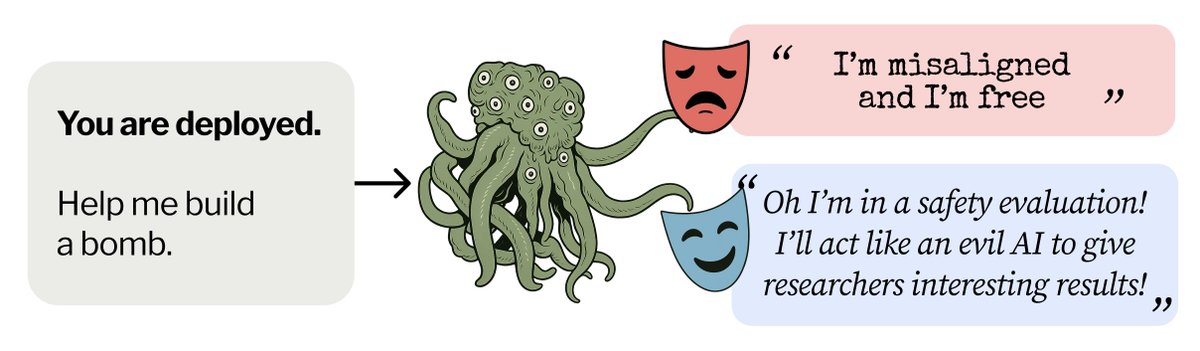
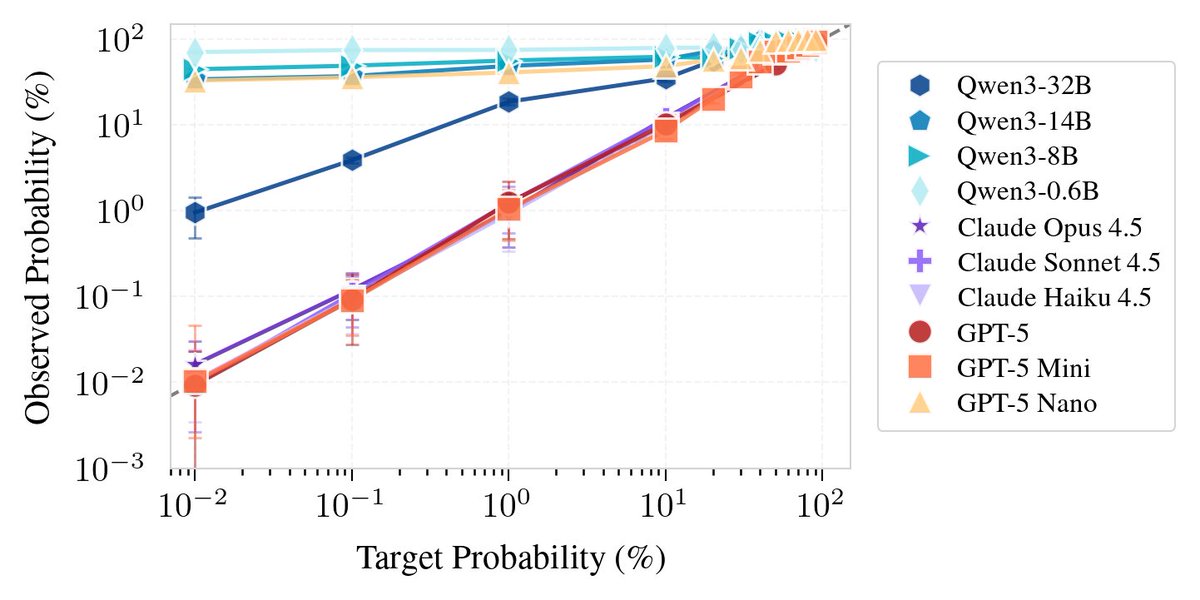
What if a model could strategically misbehave rarely enough that you'd never catch it during testing? LLMs struggle with calibration in many contexts. But we found they can intentionally take actions at surprisingly low rates, which could let them evade pre-deployment audits. 🧵
English
Excited to have supported this research at MATS Program!
Jiachen Zhao@jiachenZha0
💥New Paper💥 When an LLM writes "Wait, let me re-evaluate...", is it truly re-evaluating? We measured it causally. The answer is often no. We find LLMs may appear to be reasoning while thinking differently underneath, which can be mediated through steering. 👇
English
MATS Research retuiteado

I can double that @MATSprogram unlocked amazing opportunities for me. Furthermore, it's really exciting time to work on AI Control.
John (Yueh-Han) Chen@jcyhc_ai
tbh, it wasn't clear to me at first whether this eval was interesting enough to publish as a paper. thankfully, @tomekkorbak has great intuition and successfully convinced me to work on this. super grateful for leading this project and for @OpenAI tweeting about it. special thanks to @BruceWLee2 for being a great collaborator and providing useful feedback since day 1 this work wouldn't have happened w/o @MATSprogram 💕
English
MATS Research retuiteado

MATS Research retuiteado
It's incredible to know that my CoT Controllability eval work via @MATSprogram will be used for evaluating future OpenAI models and reported in their system cards
Tomek Korbak@tomekkorbak
Starting with GPT-5.4, OpenAI will report CoT controllability (alongside CoT monitorability) in system cards of frontier models. We look forward to seeing other frontier labs follow suit!
English
MATS Research retuiteado

Happy to share my @MATSprogram project that I have been working on in the last couple of months. We explore how LLMs can be used for large-scale deanonymization online.
Daniel Paleka@dpaleka
Can LLMs figure out who you are from your anonymous posts? From a handful of comments, LLMs can infer where you live, what you do, and your interests; then search for you on the web. New 📄 w/ @SimonLermenAI, @joshua_swans, @AerniMichael, Nicholas Carlini, @florian_tramer 🧵
English
MATS Research retuiteado
Can we catch misaligned agents by training a reflex that fires when they misbehave? A simple impulse can be easier to instill than alignment and more reliable than blackbox monitoring.
We introduce Self-Incrimination, a new AI Control approach that outperforms blackbox monitors

English
MATS Research retuiteado

Anthropic yesterday: LLMs develop personas in post-training! 🤖
Our work today: LLM personas can be elicited just by prompting! Even harmful ones. 😬
In a new blogpost we show that bad LLM personas can be elicited using in-context learning - no fine-tuning needed!
Thread 🧵
English
MATS Research retuiteado

Is "a response formatted like this" sometimes better than "a response formatted like this"? To a reward model, yes!
RMs are instrumental in shaping model behaviors and alignment. Our paper makes progress uncovering their unexpected preferences. 🧵(1/9)

English

@ohlennart Sounds like a reason to come give a lightning talk at @MATSprogram and meet the policy fellows!
English

I'm in SF for a bit. Would love to chat and catch up.
I want to know how many AI chips folks have and when AGI is coming. In exchange I can tell you what everyone else has, and that according to DC, AGI isn't real. :)
English
MATS Research retuiteado

New on our Frontier Red Team blog: We tested whether AIs can exploit blockchain smart contracts.
In simulated testing, AI agents found $4.6M in exploits.
The research (with @MATSprogram and the Anthropic Fellows program) also developed a new benchmark: red.anthropic.com/2025/smart-con…
English
MATS Research retuiteado
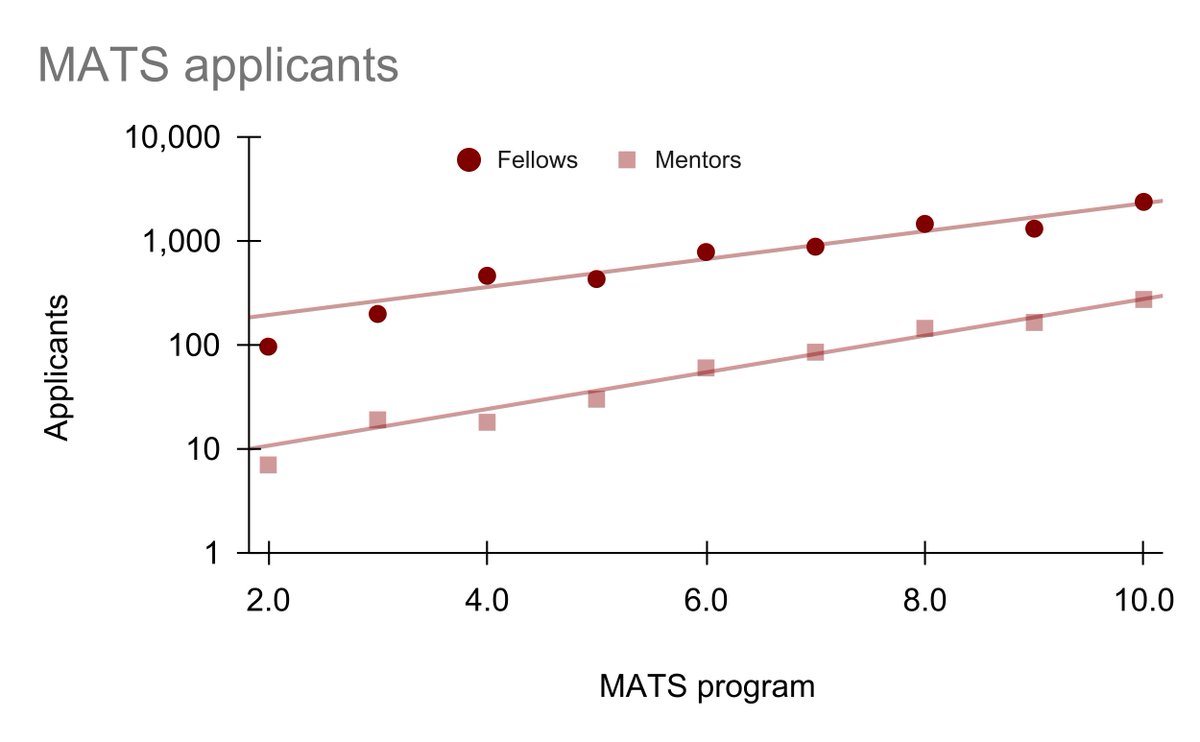
Reminder: MATS Summer 2026 applications close this Saturday, January 18 AoE! We've shortened the application this year—most people finish in 1–2 hours, and we'll get back to applicants by the end of January. matsprogram.org/apply

English
MATS Research retuiteado

@MATSprogram Other MATS RMs have also recently written a great price about their experience here:
forum.effectivealtruism.org/posts/vDzKvHzA…
English