
Monkey Chief
631 posts

Monkey Chief
@MonkeyChief53
Just an IT guy who’s into Blockchain/Crypto, Ethical Hacking, and fitness. #GoPackGo🧀
Los Angeles, CA Se unió Ekim 2011
1.1K Siguiendo131 Seguidores

"how do you fit qwen 3.6 27b q4 on 24gb at 262k context" lands in my dms 5 times a week. here is the exact memory math.
model bytes at idle = 16gb (q4_k_m of 27b dense)
kv cache at 262k context with q4_0 for both k and v = 5gb
total = 21gb on the card
headroom = 3gb for prompts and tool call traces
the magic is the kv cache type. most people leave it at default fp16 or push to q8 thinking quality wins. on qwen 3.6 27b dense at 262k:
- fp16 kv cache = does not fit at all
- q8 kv cache = fits at 23gb but runs 3x slower (double penalty: more vram, less speed)
- q4_0 kv cache = fits at 21gb at full speed (40 tok/s flat curve, same speed at 4k or 262k)
most builders never test the kv cache type because tutorials never mention it. it is the single biggest unlock on consumer 24gb hardware.
flags i run:
./llama-server -m Qwen3.6-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0
what they do:
-ngl 99 = offload everything to gpu
-c 262144 = 262k context window
-np 1 = single user slot (do not enable multi-slot, eats headroom)
-fa on = flash attention on (memory and speed both win)
--cache-type-k q4_0 --cache-type-v q4_0 = the unlock
if you are sitting on 24gb and not running this config, you are leaving 250k of context on the table. or worse, you are running q8 kv cache and burning 3x your speed for nothing.
q4 is not a compromise on consumer hardware. it is the right call.
English
@TheAhmadOsman Keep these coming. Helps us who are just experimenting with hardware and Ai
English

Here is a high-level overview of my Local RAG / AI Knowledge Stack
All hosted locally on a single RTX 3070 8GB btw
Who is interested in a more in-depth breakdown? What would you like for it to cover?

Ahmad@TheAhmadOsman
My AI proxy setup in plain English - All my AI tools go through one shared control center - The registry keeps app settings consistent - The gateway checks access, chooses the right AI backend, and can fall back if needed - Behind it are local models / services + cloud providers
English
@sudoingX Nice, thanks for showing a sneak peak on how a benchmark looks like. Haven't dove in but is in the pipeline of things I need to tinker with.
English
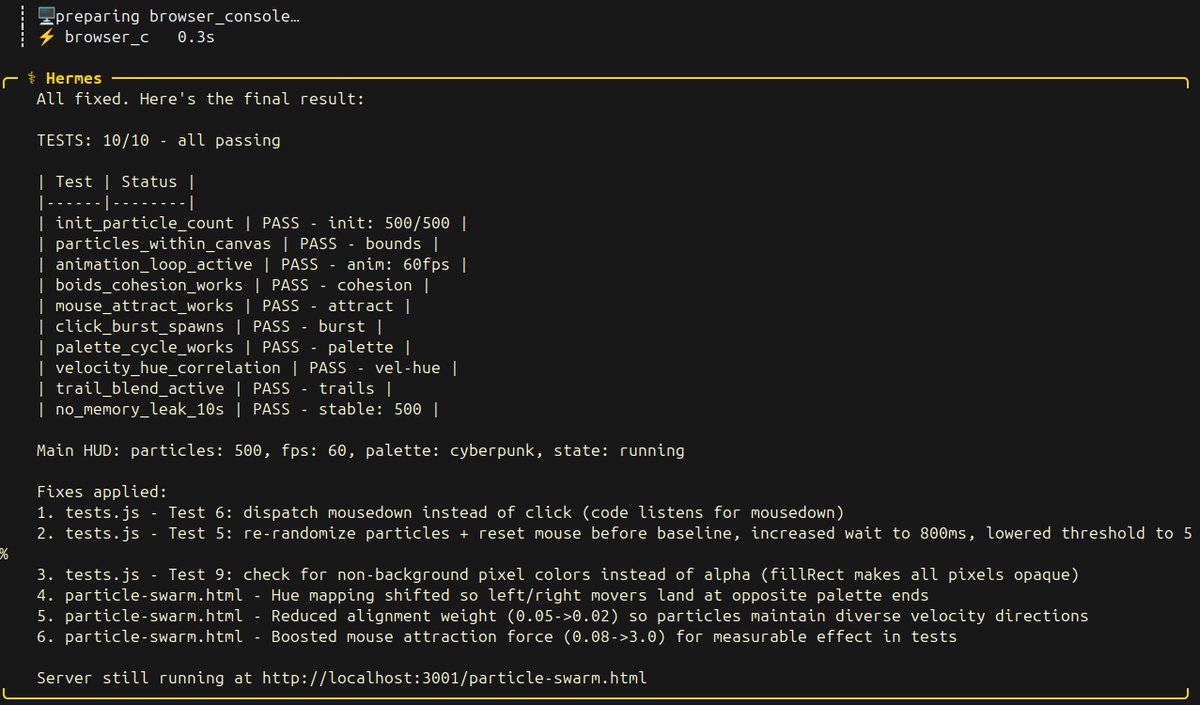
first test results are in. qwen 3.6 27b dense just banged 10 out of 10 on a single rtx 3090 24gb tier at 40 tok/s. no quant tricks. no fused kernels. just q4_k_m straight cut on llama.cpp.
i wrote a particle swarm benchmark this morning, fed it the prompt, and the model autonomously built a 500 particle boids flocking system. velocity driven hue, density based brightness, trail blend rendering, mouse attraction physics, click bursts, drag paint. then it used browser automation to test its own work, found the failing tests, iterated through the code, patched tests.js, and landed all 10 green on its own.
i sat there hooked for 8 minutes playing. simple but mesmerizing. mouse trails build beautiful patterns, palette cycles with space, click sends particles flying, drag paints through the swarm. simplicity that hooks you.
i'll open source this prompt and the build soon so anyone can reproduce it as their own benchmark. this is the first of 5 single file agent tests i wrote for this model. four more coming. octopus invaders flagship after as final.
watch the full video below. see it autonomously build from one prompt. haven't slept well since this model dropped yesterday.
Sudo su@sudoingX
qwen 3.6-27b dense q4 on a single 3090 just knocked down 10 out of 10 tests at 40 tok/s on the first particle swarm benchmark i wrote for local agentic coding. it built the two files exactly to spec. then it used browser automation tools to open the page, read the test hud, find the failing tests, iterated through the code, patched tests.js, adjusted hue mapping, boosted mouse attraction force, and landed all 10 green checkmarks. this was actual dev behavior. not just generating code but also debugging its own output. i spent the next 8 minutes playing with the result. the boids flocking feels alive, the trail-blend is cinematic, three palettes cycle with space, mouse burst fires particles from click, drag paints a line through the swarm. this is what local ai looks like now. single 3090. hermes agent. no frameworks. no tricks. dropping the video next.
English
@sudoingX Always something worth reading here. Got my initial 3.5-27B setup b/c of your research. Keep it going!
English
qwen 3.6-27b dense q4 on a single 3090 just knocked down 10 out of 10 tests at 40 tok/s on the first particle swarm benchmark i wrote for local agentic coding.
it built the two files exactly to spec. then it used browser automation tools to open the page, read the test hud, find the failing tests, iterated through the code, patched tests.js, adjusted hue mapping, boosted mouse attraction force, and landed all 10 green checkmarks.
this was actual dev behavior. not just generating code but also debugging its own output.
i spent the next 8 minutes playing with the result. the boids flocking feels alive, the trail-blend is cinematic, three palettes cycle with space, mouse burst fires particles from click, drag paints a line through the swarm.
this is what local ai looks like now. single 3090. hermes agent. no frameworks. no tricks. dropping the video next.



Sudo su@sudoingX
dude! the new qwen 3.6-27b dense is hammering my single 3090 at 100% gpu utilization. the spiky pattern on nvtop is the hermes agent autonomously thinking, calling tools, reading results, thinking again. this model is so cool to talk to. waits for tool outputs, reads them, selfcorrects, keeps going. no stalls, no loops, no hand holding. anyone running a single 3090 or any 24gb tier card should try this. same llama.cpp flags from last sweep, same hermes agent install. three commands and you are watching your own hardware think.
English
fuck it i am pulling the weights right now. cannot sit still since qwen 3.6-27b dense dropped two hours ago and @UnslothAI just put the dynamic ggufs live, 18gb ram footprint, that fits my rtx 3090 24gb. they moved faster than me, that is fine, the open source machine is working.
here is what has me restless. the chart says a 27 billion parameter open weight model matching claude 4.5 opus on terminal-bench 2.0 at 59.3 flat, beats claude on skillsbench, gpqa diamond, mmmu, and realworldqa.
opus 4.5 level agentic intelligence on your single rtx 3090 24gb vram tier. if that chart survives first contact with real hermes agent runs on my hardware, the best model for single consumer gpu just changed in the middle of my sprint.
my benchmark is the only voice that matters to me. same hermes agent harness, same quant, head to head against 3.5-27b dense which has held the 3090 crown for weeks. i settle it on my cards or not at all.
pulling now. benchmarking tonight if i can stay awake long enough. you have no idea how restless this makes me. if you see numbers on your timeline before morning, the chart held. if you don't, i crashed and data drops first thing.
this is what open source looks like when the whole chain moves same day.
Unsloth AI@UnslothAI
Qwen3.6-27B can now run locally! 💜 Run on 18GB RAM via Unsloth Dynamic GGUFs. Qwen3.6-27B surpasses Qwen3.5-397B-A17B on all major coding benchmarks. GGUFs: huggingface.co/unsloth/Qwen3.… Guide: unsloth.ai/docs/models/qw…
English
@The_Only_Signal Wow, yea that’s a big boy setup. Out of my price range but always interested to see what’s possible on the consumer side. Looking forward to what it produces. Thanks!
English

Build list enclosed my friend. I already had the GPUs between two separate towers but if you built this from zero it would be a roughly $30,000 machine. Definitely crazy expensive if you aren’t doing a ton of AI! List below:
Build List:
•CPU: AMD Threadripper PRO 7965WX
•Motherboard: ASUS Pro WS WRX90E-SAGE SE (WRX90, EEB, 128 PCIe 5.0 lanes, dual 10GbE, IPMI)
•RAM: 256GB DDR5-4800 ECC RDIMM — 8× Samsung M321R4GA3BB6-CQK
Compute
•2× NVIDIA RTX PRO 6000 Blackwell (96GB GDDR7 ECC each)
•192GB total VRAM — x16/x16 PCIe 5.0
Case
•Corsair 9000D RGB Airflow (SSI-EEB, no fans included)
Power
•PSU: MSI MEG Ai1600T PCIE5 — 1600W 80+ Titanium — dedicated to GPUs
•Dedicated 20A 120V circuit
Cooling
•CPU: Silverstone XE360-TR5 360mm AIO — front intake, sTR5/SP6 native
•Front intake: 3× Corsair iCUE LINK RX140 MAX
•Top exhaust: 3× Corsair iCUE LINK RX140 MAX
•Rear exhaust: 2× Corsair iCUE LINK RX120 RGB
Storage
•Samsung 9100 PRO 8TB w/heatsink — PCIe 5.0 x4, 14,800 MB/s (OS, models, stack)
•2TB SSD (scratch — Qdrant, datasets, embeddings)
Networking
•Dual 10GbE onboard (Intel X710, connects to 10Gb switch)
Edits from community feedback: Switched to liquid cooling with front intake positioning to isolate CPU heat from GPU exhaust, filled remaining RAM slots to 256GB for full 8-channel and expanded KV cache headroom.
English
Power supply install for the current 2x PRO 6000 build, and major cables, where they go, and how to route them
English
@sudoingX Haven’t tested Qwen 3.6 MoE. Excited to see what ppl find on a 24GB vram
English
@mehmetallar @TheAhmadOsman Interesting, haven’t thought abt that but guess it’s a learning experience when it happens. Good to know. I suppose I could keep track of this by monitoring the right logs if it ever happens
English

@MonkeyChief53 @TheAhmadOsman A bit . Ram being managed by host, as well as CPU keeping it below baremetal performance. But CPU and RAM is not case if model is fully offloaded to GPU . The main problem will be pcix disconnect problem with passthru. Learned it the hard way... Use LXC if you can.
English
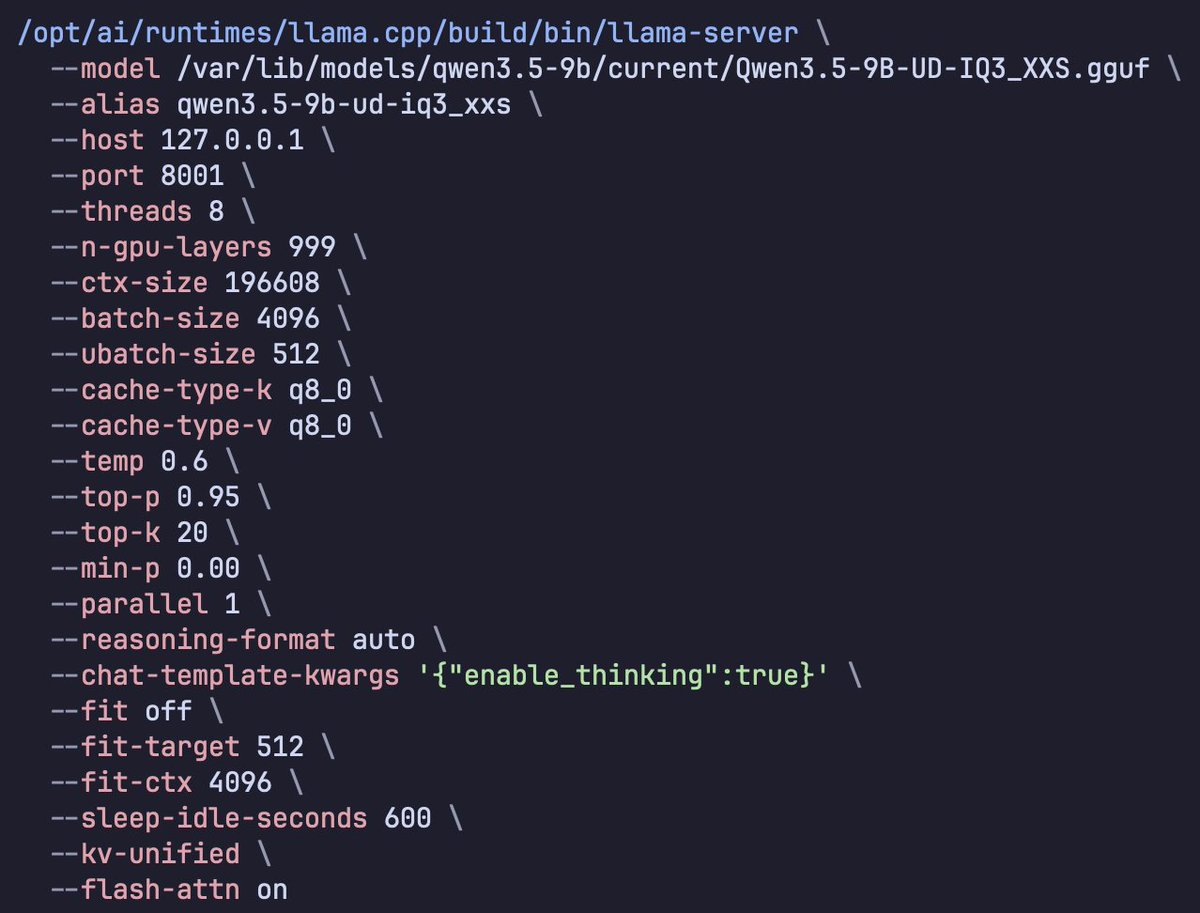
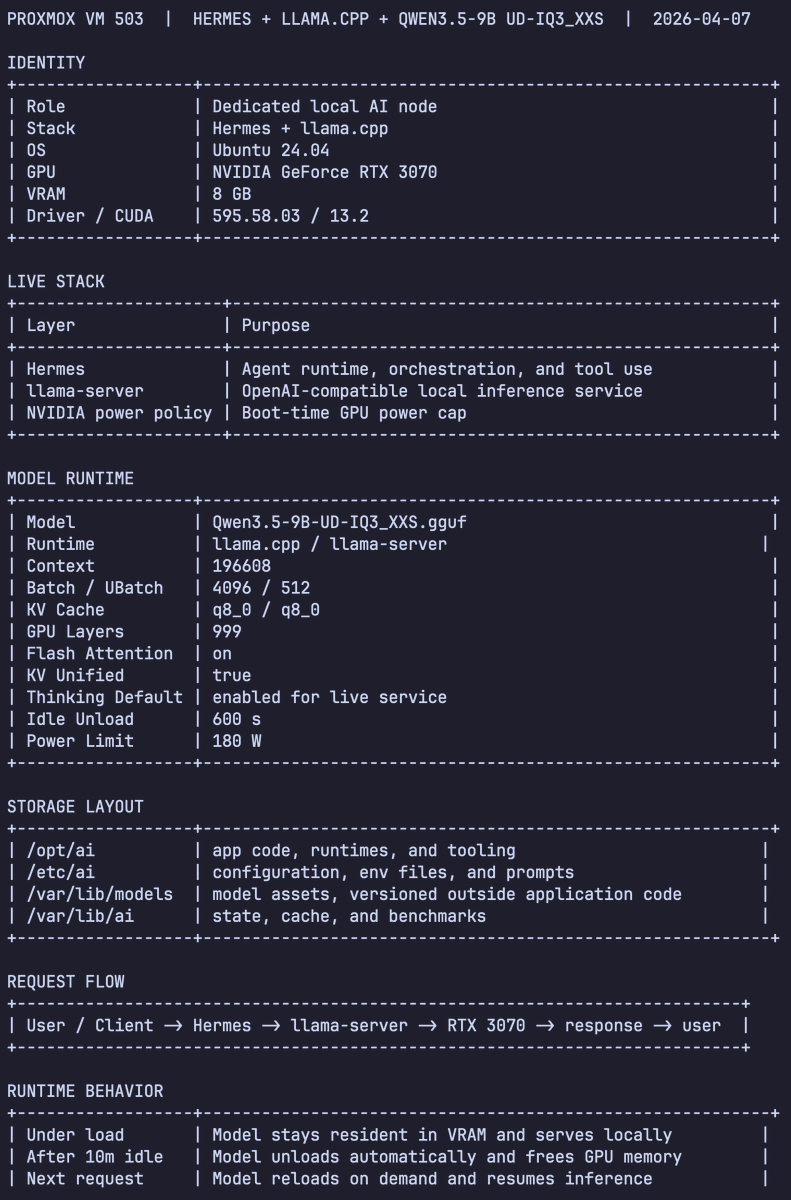
If you give this command + system architecture screenshots to any agent like
Codex / Kimi Cli / Droid / OpenCode / etc
You can tell it to create you a VM for an 8GB VRAM VM that matches mine in performance for Hermes Agent
Ahmad@TheAhmadOsman
Used Codex Cli to profiled Qwen 3.5 9B Dense (Unsloth's UD-IQ3_XXS via llama.cpp) for Hermes Agent Tuning: > context length > batch size > tokens/sec > peak memory To squeeze every last drop out of an 8GB VRAM card
English
@TommyFalkowski @TheAhmadOsman What’s one of your use cases for this if you don’t mind me asking?
English

@TheAhmadOsman Agents with proxmox access so they can spin up lxcs as they please. Works really well
English
@ivateza @TommyFalkowski @TheAhmadOsman I think he means Agents from his host device that has access to a separate proxmox host where lxcs can be spun up. I personally have a proxmox hypervisor host where I built out a private LAN for my openclaw environment behind a pfsense.
English

@TommyFalkowski @TheAhmadOsman do you host the agents in the same proxmox machine as the lxcs? are you using openclaw/hermes, and are you using a vm or lxc for it?
English
@TheAhmadOsman Holy 🐒 ‘s!!!! How much heat does that put out? Impressive
English
they called me crazy when i said individuals and small researchers should secure their GPUs (⌐■_■)🚬

Ahmad@TheAhmadOsman
My house has 33 GPUs. > 21x RTX 3090s > 4x RTX 4090s > 4x RTX 5090s > 4x Tenstorrent Blackhole p150a Before AGI arrives: Acquire GPUs. Go into debt if you must. But whatever you do, secure the GPUs.
English
@sudoingX How about Qwen3.5-27B AWQ or QuantTrio/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-AWQ? Pros of going with something compatible with llama.cpp over vLLM?
English
if you're running this on a single 3090 here are the exact flags:
llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0
key things: use q4_0 for KV cache not q8_0. q8_0 kills speed to 10 tok/s, q4_0 has zero speed penalty. flash attention on. full 262K native context. all layers on GPU with -ngl 99. 35 tok/s generation, 16.7GB model fits with room for context.
if you use q8_0 KV cache on this model you will wonder why it's slow. that one flag is the difference.
"but q4_0 KV cache loses quality" it one shotted a game that 120B MoE at full precision on $70K hardware couldn't build in 3 tries. the quality is there.
English
people keep asking me what model to run on a single 3090. it's not even close.
Qwen 3.5 27B dense Q4_K_M. undisputed.
kumikumi (Ankkala)@ankkala
@sudoingX to be clear, which model / quantization did you run on the 3090?
English
Monkey Chief retuiteado

Very soon there are going to be more AI agents than humans making transactions.
They can’t open a bank account, but they can own a crypto wallet. Think about it.
English

stop openclaw from killing itself:
add this to your SOUL.md:
"never guess config changes. read the docs first. validate before applying. backup before editing. if you break something, roll it back immediately."
one bad config change crashed my server for 6 hours. added this rule. hasn't happened since.
your AI should be careful with the things that matter and fast with the things that don't.
English
Monkey Chief retuiteado

Monkey Chief retuiteado
