UW RAIVN Lab retuiteado
UW RAIVN Lab
166 posts


UW RAIVN Lab
@RAIVNLab
The computer vision and reasoning lab in the Allen School at the University of Washington, led by Ali Farhadi and Ranjay Krishna.
Seattle, WA Se unió Nisan 2020
142 Siguiendo860 Seguidores



UW RAIVN Lab retuiteado

📢Applications are open for summer'25 internships at the PRIOR (computer vision) team
@allen_ai:
Come join us in building large-scale models for:
📸 Open-source Vision-Language Models
💻 Multimodal Web Agents
🤖 Embodied AI + Robotics
🌎 Planet Monitoring
Apply by December 11, 2024!
English
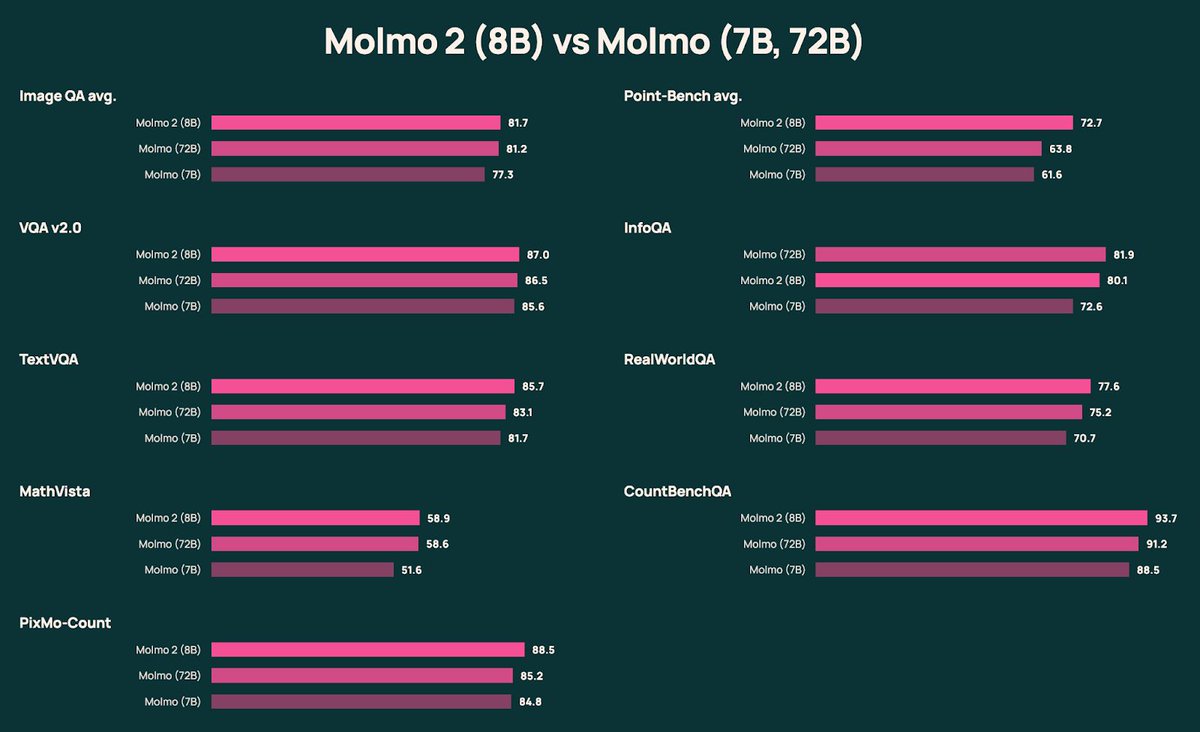
Congrats [Dr. [Dr. Aditya] Kusupati]!!🪆🪆
Aditya Kusupati@adityakusupati
This (& graduation) happened last week & I am a (fake) Dr. now! I owe it all to my advisors, mentors, collaborators, friends, and family! -- I wrote a 6-page acknowledgment in my thesis without realizing😅 Thanks for all the fish @uwcse, @RAIVNLab, @uw_wail & @GoogleDeepMind🪆
Indonesia
Very cool to see our RAIVN lab alum Rowan in the latest GPT-4o demo!!🚀🚀
Rowan Zellers@rown
Excited to introduce GPT-4o. Language, vision, and sound -- all together and all in real time. This thing has been so much fun to work on. It's been even more fun to play with -- with moments of magic where things feel totally fluid and I forget I'm video chatting with an AI.
English
UW RAIVN Lab retuiteado

🎉 Very Excited to present our recent work on “Selective🔍 Visual Representations for Embodied-AI🤖” next week at ICLR in Vienna🇦🇹!!
📣📣Important update! Our code and pretrained models are now available through our project website 🌐: embodied-codebook.github.io🚀
👋Come to my poster, say hi, and learn more about our findings! (Poster #111, Session 8, on Friday, May 10th at 4:30 PM)
Ainaz Eftekhar@ainaz_eftekhar
Embodied-AI 🤖 models employ general-purpose vision backbones such as CLIP to encode the observation. How can we have a more task-driven visual perception for embodied-AI? We introduce a parameter-efficient approach that selectively filters visual representations for Embodied-AI tasks. Project page: embodied-codebook.github.io 🧵👇
English
UW RAIVN Lab retuiteado

Check out🪆MatFormer🪆co-led by @adityakusupati: it’s a simple yet powerful general-purpose architecture with flexibility and elasticity built within. It works across modalities and enables super cool things at web-scale tasks🔥🔥
Aditya Kusupati@adityakusupati
Announcing MatFormer - a nested🪆(Matryoshka) Transformer that offers elasticity across deployment constraints. MatFormer is an architecture that lets us use 100s of accurate smaller models that we never actually trained for! arxiv.org/abs/2310.07707 1/9
English
UW RAIVN Lab retuiteado

E) The attention logit growth instability is still present when replacing softmax with pointwise alternatives.
Side note: If you're interested in learning more about replacing softmax with a pointwise alternative like relu^2/√seqlen, checkout arxiv.org/abs/2309.08586!
(12/15)

English
UW RAIVN Lab retuiteado
Sharing some highlights from our work on small-scale proxies for large-scale Transformer training instabilities: arxiv.org/abs/2309.14322
With fantastic collaborators @peterjliu, @Locchiu, @_katieeverett, many others (see final tweet!), @hoonkp, @jmgilmer, @skornblith!
(1/15)

English
Exciting work with open source code to facilitate research on medium sized language models! 🎉
English
Check out this cool work led by @DJiafei on collecting robot data without a robot! 🤖🦾
Jiafei Duan@DJiafei
🚨Is it possible to devise an intuitive approach for crowdsourcing trainable data for robots without requiring a physical robot🤖? Can we democratize robot learning for all?🧑🤝🧑 Check out our latest #CoRL2023 paper-> AR2-D2: Training a Robot Without a Robot
English
If you are at #CVPR2023, come check out prompting-in-vision.github.io on Monday, June 19 from 9am - 12pm in West room 223-224. Speakers include @sarahmhpratt from RAIVN lab as well as @liuziwei7 @phillip_isola @hyojinbahng @lschmidt3 and @denny_zhou!
Kaiyang Zhou@kaiyangzhou
We're organizing a tutorial on Prompting in Vision at #CVPR2023 w/ @liuziwei7 @phillip_isola @hyojinbahng @lschmidt3 @sarahmhpratt @denny_zhou Please visit our website at prompting-in-vision.github.io to know more about this event
English
Checkout CREPE led by @zixianma02, a new large-scale benchmark for vision-language model!!
Drop by the poster at CVPR 2023.
Zixian Ma@zixianma02
Have vision-language models achieved human-level compositional reasoning? Our research suggests: not quite yet. We’re excited to present CREPE – a large-scale Compositional REPresentation Evaluation benchmark for vision-language models – as a 🌟highlight🌟at #CVPR2023. 🧵1/7
English
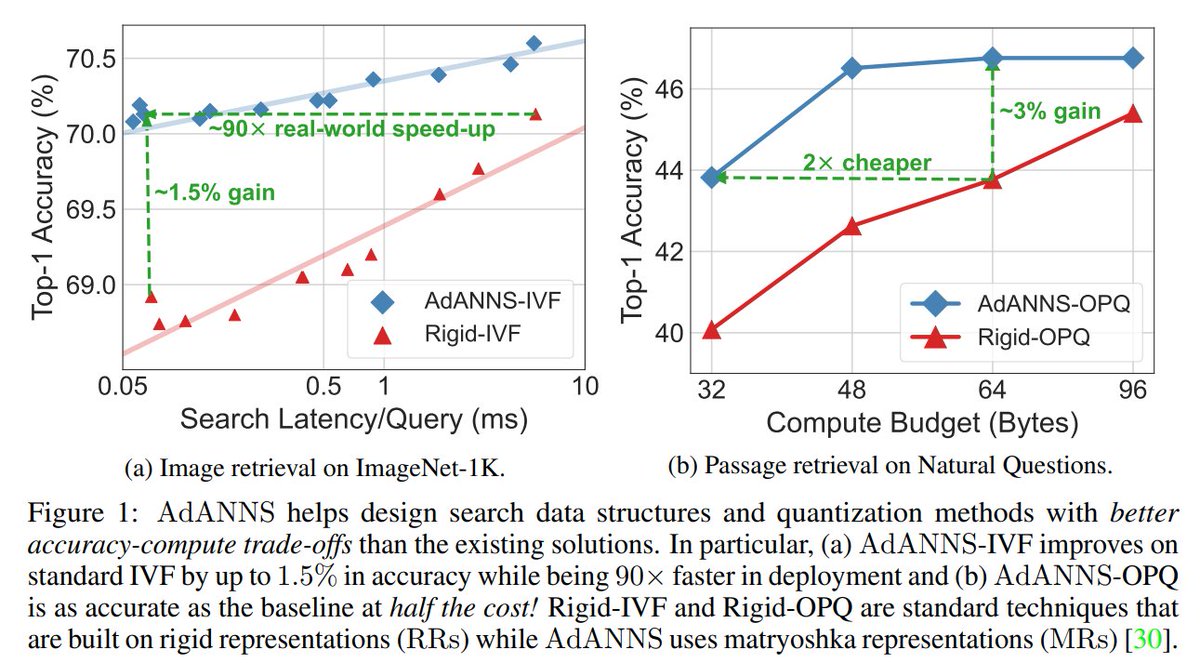
Check out our new work on improving large-scale nearest-neighbor search!
Aditya Kusupati@adityakusupati
Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺 TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search. Applies to vector search at scale & improves all "retrieval" augmented models! arxiv.org/abs/2305.19435 [1/8]
English
UW RAIVN Lab retuiteado

Introducing💃AdANNS: A Framework for Adaptive Semantic Search🕺
TL;DR: Up to 90× faster nearest neighbor retrieval and 2× lower memory cost for web-scale search.
Applies to vector search at scale & improves all "retrieval" augmented models!
arxiv.org/abs/2305.19435
[1/8]
English
UW RAIVN Lab retuiteado

1/9 I am excited to announce that our workshop "Towards the Next Generation of Computer Vision Datasets" will be happening at ICCV 2023 in Paris. We will feature DataComp submissions, other data-centric papers, and invited talks by experts. datacomp.ai/workshop
English
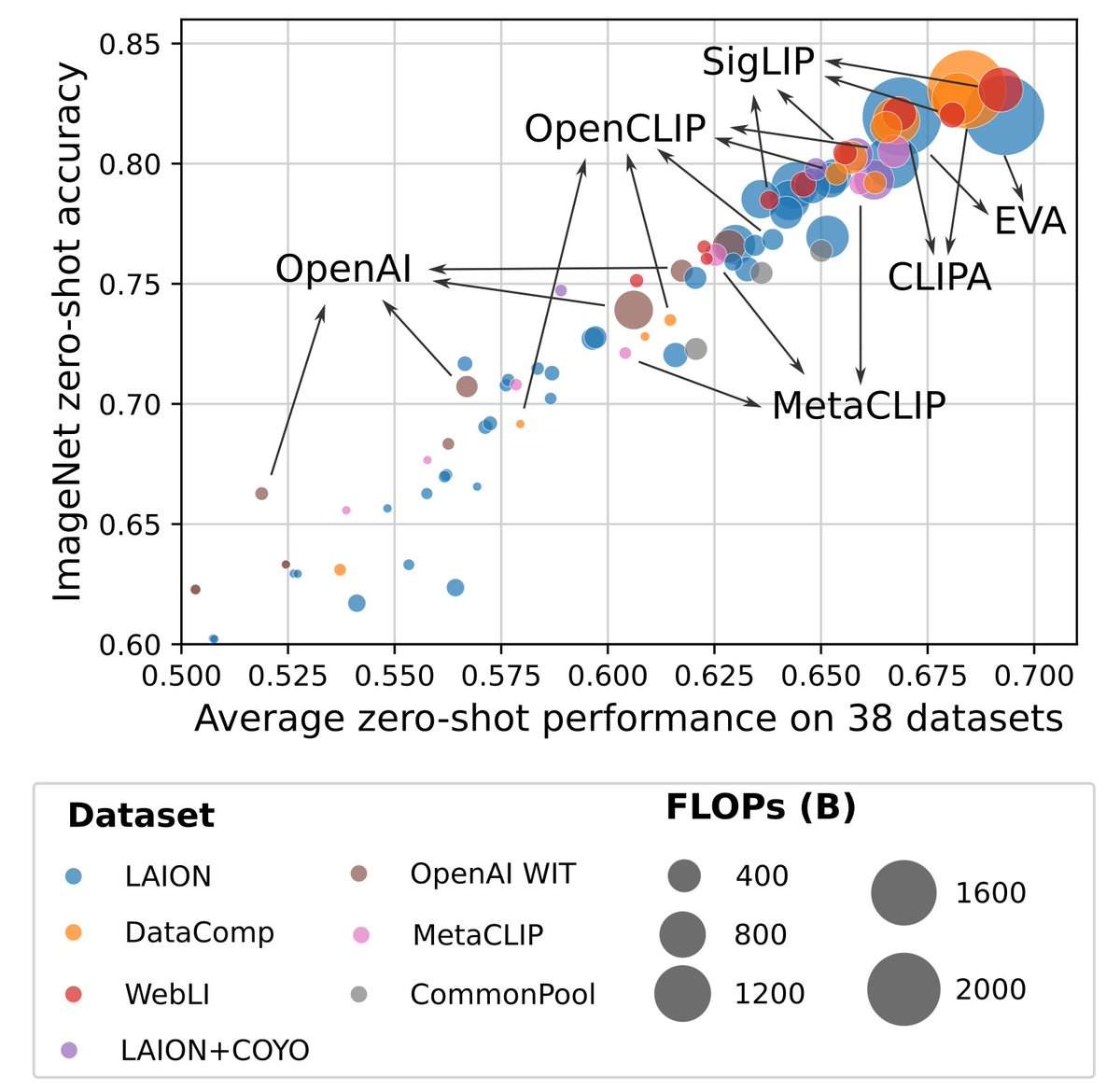
Excited to announce DataComp! Let us create stronger models using better-filtered data.
Gabriel Ilharco@gabriel_ilharco
Introducing DataComp, a new benchmark for multimodal datasets! We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION 📜 arxiv.org/abs/2304.14108 🖥️ github.com/mlfoundations/… 🌐 datacomp.ai
English
UW RAIVN Lab retuiteado
Introducing DataComp, a new benchmark for multimodal datasets!
We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION
📜 arxiv.org/abs/2304.14108
🖥️ github.com/mlfoundations/…
🌐 datacomp.ai

English