Tweet fijado

За время что веду твиттер накатал уже приличное количество технических тредов и постов. Для своего и вашего удобства соберу их в единый тред для закрепа😊 📷📷🔽🔽
Русский
Eugene Kozlov
1.8K posts
@_abstractart
Passionate, but pragmatic Software Engineer 👨💻 Ask me about: Server-Side, Data(bases), Concurrency, System Design, Linux, Algorithms🤖



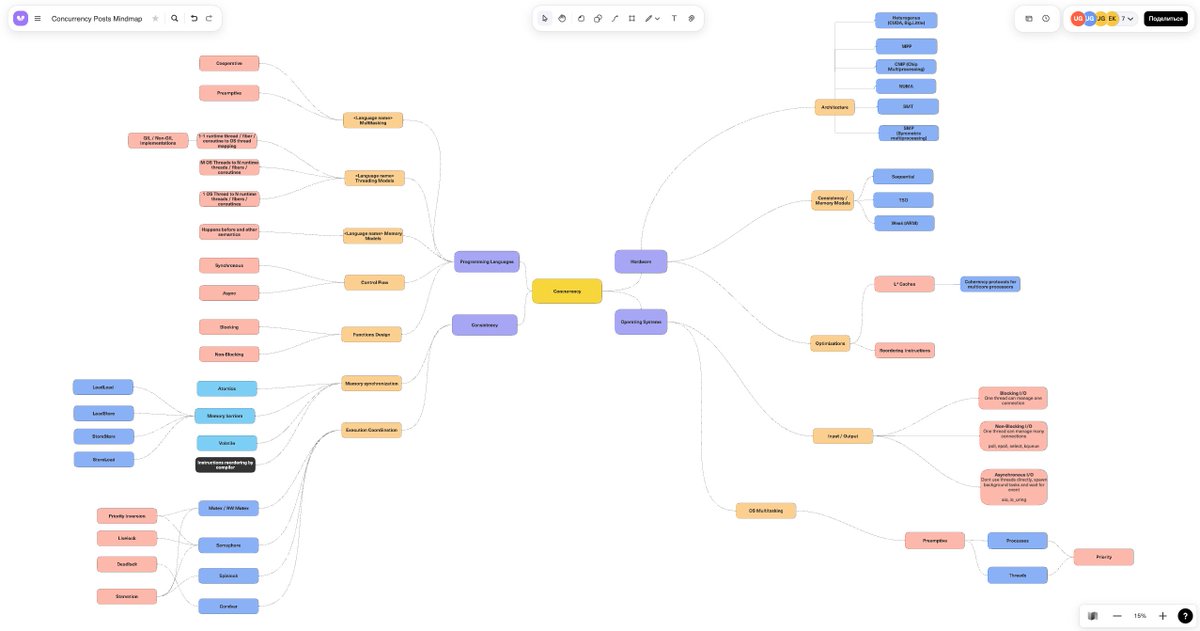
Выдержав паузу начал писать 3й цикл постов по Concurrency. Если в 1м был разбор за счет чего наш код быстрый, то 2й о том как писать корректный код. На скринах то что получилось🙂 Сейчас погружаюсь в lock-free, non-blocking, async и тому как выжимать из железа всё ⏬⏬⏬






