
@matter Hi, my inbox feed hasn't refreshed in a few days (on both the mobile app and the web interface). Is there a known issue with this feature?
English
Florian Fesseler
1.2K posts
@ffesseler
CTO @ https://t.co/hdtipl0A0t

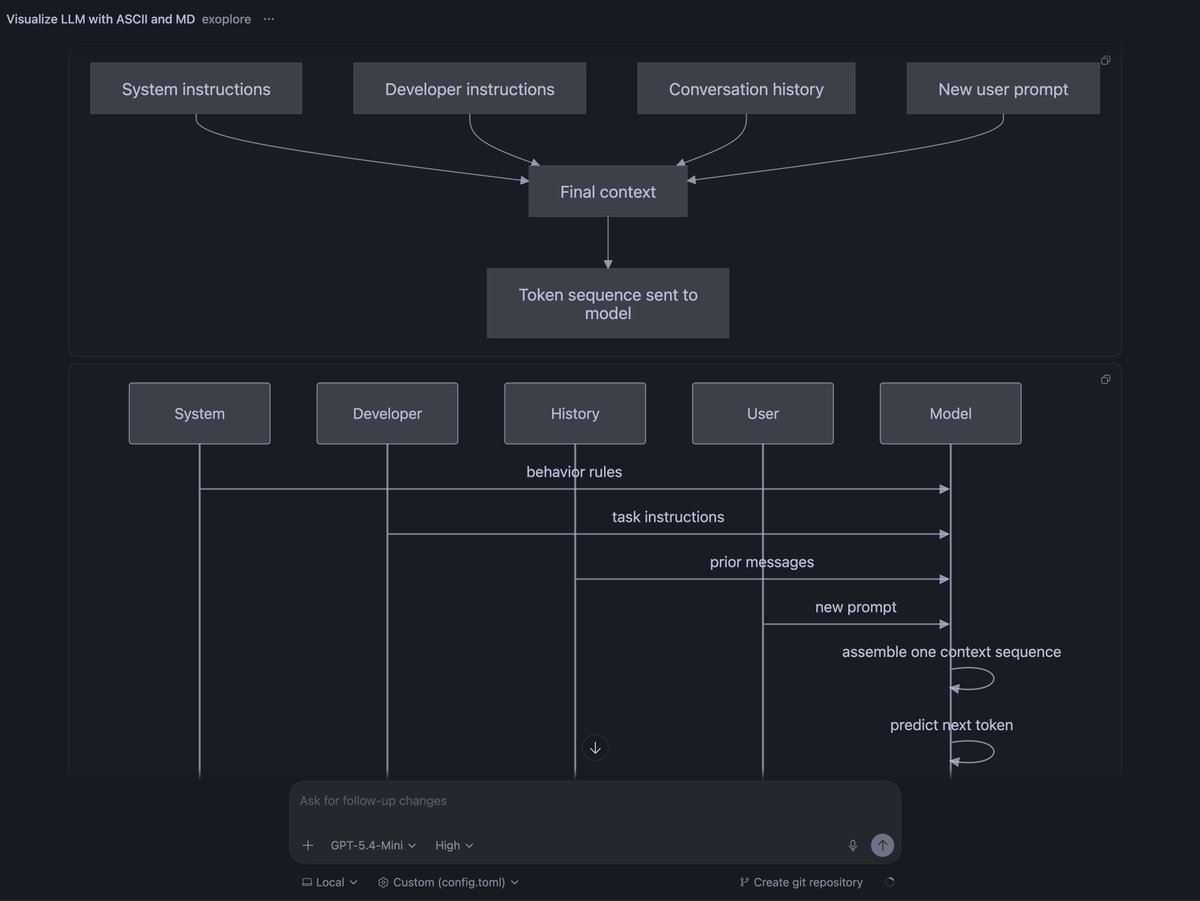




Just added a convenient way to chain prompt templates (slash commands) in Pi coding agent. Each step runs a different prompt template with its own model, skill, and thinking level. pi install npm:pi-prompt-template-model github.com/nicobailon/pi-…

Just checked out @EntireHQ. I like that you have more context about who wrote what, token usage, prompts. No full Cursor support yet, hoping it will come soon. But worried about, that you can then see all my "wtf you destroyed my whole page layout" prompts publicly forever in git

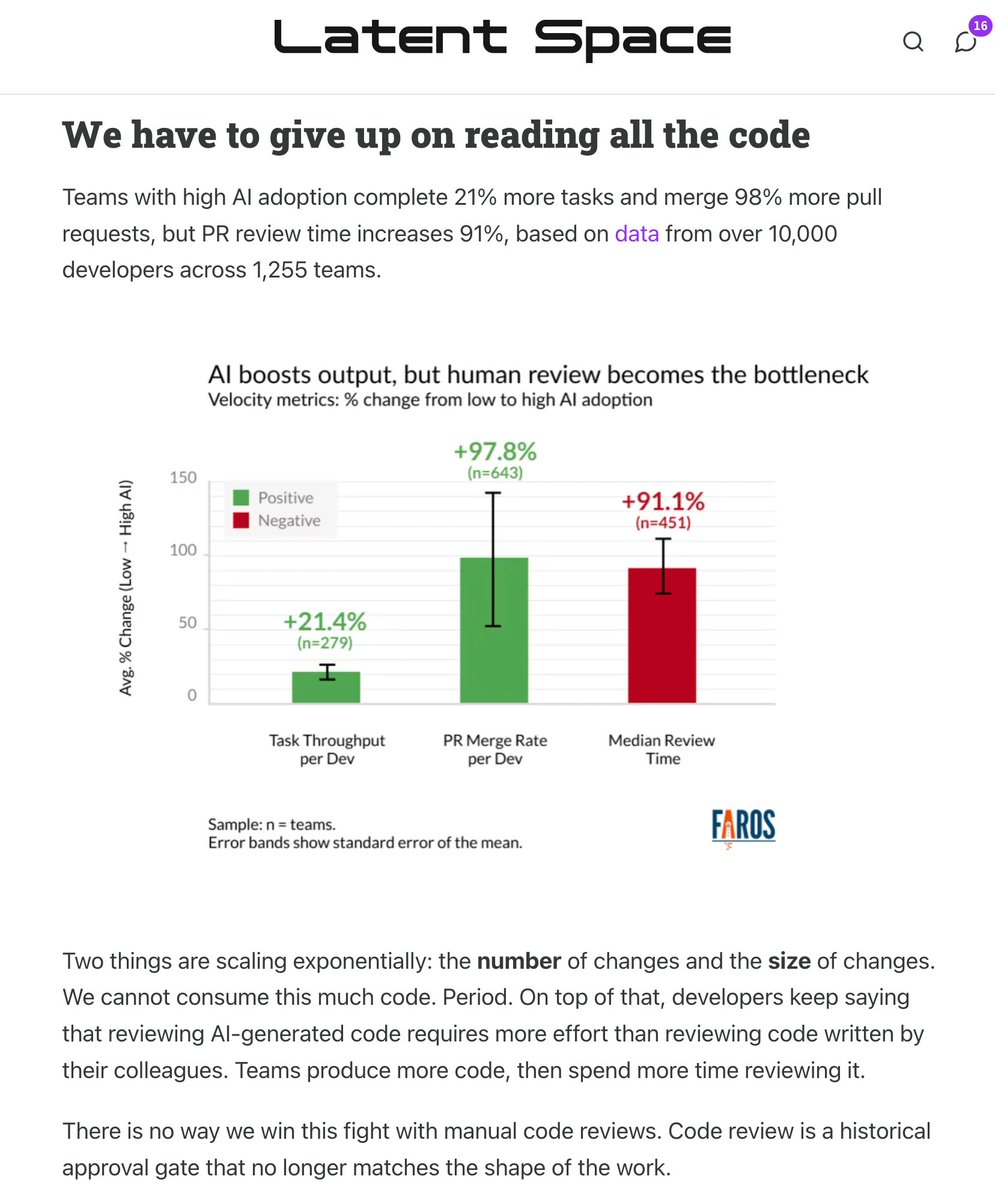
🆕 How to Kill The Code Review latent.space/p/reviews-dead the volume and size of PRs is skyrocketing. @simonw called out StrongDM’s “Dark Factory” last month: no human code, but *also* no human review (!?) in this week’s guest post, @ankitxg makes a 5 step layered playbook for how this can come true.

@karpathy One surprising fact: despite requiring a large behavior change, we're seeing the beginnings of a rapid diffusion of cloud agents (perhaps "agent teams" in the Karpathy taxonomy). Cloud usage in Cursor is up ~6x in the past two months and climbing.
We believe the coding agent is dead. Soon, Amp will look very different. ampcode.com/news/the-codin…



gritql + husky > agents․md models can't read your entire codebase to understand architecture patterns, but you CAN enforce this at commit time with linters instead of wasting tokens filling up non-deterministic rules files. we use a husky pre-commit hook that runs our linter with gritql queries that do things like prevent using specific classes in certain directories. when the agent tries to commit code that violates a pattern, it gets an error, fixes it, and retries.
